作者:BlockSec
原标题:香港OTC监管三次进化:从“币店江湖”到全面纳管
2025 年 5 月,香港警方捣毁一个价值1500 万美元(约 1.17 亿港元)的虚拟资产洗钱集团,涉案团伙主要通过位于尖沙咀的OTC 渠道分拆、转移资金。
在早些时候,轰动全港的JPEX 案中,商业罪案调查科(Commercial Crime Bureau, CCB)披露,不少涉案资金通过在港 OTC 店铺完成兑换与转移,成为诈骗链条的重要一环。
2025 年 6 月,香港政府发布了《Legislative Proposal to Regulate Dealing in Virtual Assets》(《规管虚拟资产买卖服务立法建议》)公众咨询文件,建议将包括 OTC 在内的所有虚拟资产买卖服务纳入统一发牌监管框架。 虽然该建议目前仍处于咨询阶段,尚未形成法规,但它为香港虚拟资产监管的下一步描绘了清晰的蓝图——从早期的 VATP 平台发牌,到币店纳管,再到全面覆盖 VA Dealing 服务。
用一句话概括:三年时间,香港监管从 OTC 「真空地带」走向全链条纳管。
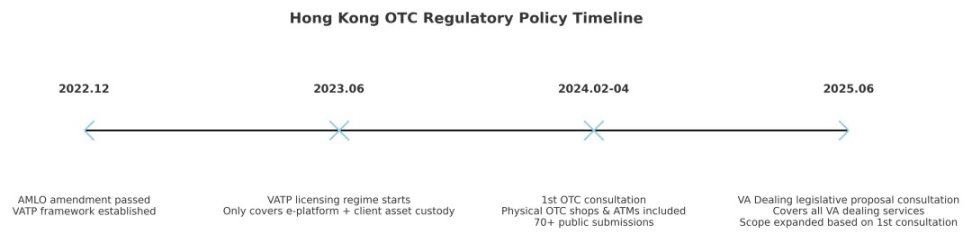
第一阶段(2023)VATP 纳入监管,OTC 却成「漏网之鱼」
2022 年底,香港通过《打击洗钱及恐怖分子资金筹集(修订)条例》,自 2023 年 6 月起,对虚拟资产交易平台(VATP)实施发牌制度,由证监会(SFC)监管。
VA Dealing Consultation Paper, 1.3
「In December 2022, … a licensing regime for VA trading platforms (」VATPs「) … commenced operation in June 2023 … must be licensed by the SFC unless otherwise permitted by the law.」VADEALING_consultation_…
根据VA exchange 的定义:
-
通过电子设施撮合买卖双方的虚拟资产交易;
-
接触客户资产(持有、控制或安排托管)
因此,当时的制度只针对「电子平台 + 接触客户资产」的业务,实体币店、柜台、ATM 等 OTC 场景并未纳入,这导致出现了监管的真空。
第二阶段(2024)海关发牌,加密货币 OTC 也需持牌
2024 年 2 月至 4 月,财政司及库务局(FSTB)推出首轮《虚拟资产场外交易服务发牌制度》咨询,首次将实体 OTC 纳入监管。
主要内容:
-
所有人在港经营虚拟资产现货交易(实体或线上)均须持牌;
-
由香港海关(CCE)负责发牌;
-
涵盖 USDT、BTC 等法币兑换与转账;
VA Dealing Consultation Paper, 1.6(a)-(b):
「Scope and coverage: Any person … services of spot trade of any VAs … would have to be licensed by the Commissioner of Customs and Excise (」CCE「).Eligibility: A licensee would be required to be a locally incorporated company …」
第三阶段(2025)OTC 并入 VASP 大家庭,SFC 统一监管
2025 年 6 月,香港发布第二轮《规管虚拟资产买卖服务立法建议》(Legislative Proposal to Regulate Dealing in Virtual Assets),监管范围和深度双升级:
-
范围扩展:涵盖大宗交易、经纪撮合、结算兑换、资产管理等复杂服务;
-
监管机构调整:由 SFC 发牌,HKMA 监管银行 /SVF 业务;
-
原则延续:同业务、同风险、同规则;
-
豁免安排:仅在一级市场发行 / 赎回稳定币且已获 HKMA 许可的发行人可豁免。
VA Dealing Consultation Paper, 1.10:
「Under the proposed regime, any person … providing the VA service of dealing in any VAs in Hong Kong is required to be licensed by or registered with the SFC… including conversion, brokerage, block trading…」
变化原因:这一轮建议正是建立在首轮咨询收到的 70 多份书面意见基础上制定的,政府在文件中说明,意见集中反映了 OTC 高风险性、跨境洗钱漏洞、监管覆盖不足等问题,因此将原有的 OTC 监管建议扩展为更广泛的「VA Dealing」框架。
VA Dealing Consultation Paper, 1.8:
「Following the conclusion of the first round of consultation, we received over 70 written submissions from various stakeholders… We have refined our proposal to expand the scope to VA dealing services to better address AML/CFT risks.」
重要提示:该阶段的内容目前仍处于公众咨询阶段,并未正式立法,最终细节可能在立法过程中调整。
政策变化背后的驱动
香港 OTC 监管政策的三次演变,并非孤立发生,而是多重因素叠加推动的结果,背后至少有三个核心驱动:
驱动一:重大案件频发,暴露监管真空
2025 年 5 月的 1500 万美元洗钱案中,涉案团伙利用 OTC 拆分资金、绕过银行监控,短时间完成多笔跨境转账。在 JPEX 案中,商业罪案调查科(CCB)发现,不少投资者被骗资金通过本地 OTC 店完成现金或稳定币兑换,再快速流向境外钱包。
这些案件暴露了一个问题:即使平台监管收紧,线下 OTC 的匿名、即时结算特性依然能绕开监管,成为「最后一公里」的风险通道。
驱动二: 国际监管压力与 FATF 标准
FATF(金融行动特别工作组)自 2019 年更新第 15 号建议(Recommendation 15)起,明确要求各司法辖区将虚拟资产服务提供者(VASPs)全面纳入反洗钱 / 反恐怖融资(AML/CFT)框架。香港在首次引入 VATP 发牌时,虽然已满足部分 FATF 要求,但 OTC 业务的「漏网」状态被国际评估机构和合作方多次指出。为维持香港国际金融中心的信誉,监管机构必须弥补这一漏洞,确保「same business, same risk, same rules」落到实处。
香港要做国际虚拟资产中心,必须解决 AML/CFT 隐患。
驱动三: 本地公众意见推动政策升级
在 2024 年首轮 OTC 咨询中,政府共收到 70 多份书面公众意见,来自银行、合规机构、加密企业、执法部门等。多数意见集中反映:OTC 的匿名交易风险高;跨境资金流难以追踪;诈骗和洗钱案件中,OTC 扮演重要中介角色。
政府在 2025 年发布的《VA Dealing》立法建议中明确指出,正是基于这些反馈,才将原本仅覆盖 OTC 兑换的监管范围扩大到更完整的VA Dealing 全链条业务。
VA Dealing Consultation Paper, 1.8:
「Following the conclusion of the first round of consultation, we received over 70 written submissions from various stakeholders… We have refined our proposal to expand the scope to VA dealing services to better address AML/CFT risks.」
总结
OTC 曾是香港加密货币市场的「地下水路」,如今它正被纳入光天化日之下。从 2023 年的平台监管,到 2024 年的币店纳管,再到 2025 年提出的全链条「VA Dealing」框架,香港虚拟资产监管正走向系统化与国际化。而这一切的最新篇章,正处于公众咨询期,等待立法的最后定稿。
Twitter:https://twitter.com/BitpushNewsCN
比推 TG 交流群:https://t.me/BitPushCommunity
比推 TG 订阅: https://t.me/bitpush





