原创 | Odaily星球日报(@OdailyChina)
作者|Azuma(@azuma_eth)
版本之子、疯狂巨鲸、大热交易员 James Wynn 的操作今天再次刷屏。
昨日,我们发了《谁是 James Wynn:小镇走出的交易天才,豪赌 10 亿的疯狂巨鲸》,概述了 James Wynn 的出生环境、成长经历、经典战绩等等。在临发文之前,James Wynn 更是曾于 X 宣布将“金盆洗手”,带着超 2500 万美元的总利润暂时告别合约交易市场。
但谁也没想到的是,短短 2 个小时后,James Wynn 就重新杀了回来 —— 果然币圈交易员的话都不能信……
再次开单
昨日上午 11: 37 左右,即宣布“止盈离场”后 2 个小时,James Wynn 再次在 Hyperliquid 上建立 PEPE 多头仓位,使用 10 倍杠杆,仓位规模约 1010 万美元。
随后在下午 2: 20 左右,James Wynn 再度“小额”开出 40 倍 BTC 多单,开仓价格 109715 美元,初始仓位名义价值约 6805 万美元;随后在凌晨 1 点左右,James Wynn 再度加仓 BTC 多头,将位名义价值提升到了 7.9 亿美元。
行情下行,紧急止损
虽然 James Wynn 昨日开出的 PEPE 和 BTC 多头都曾短暂盈利,但随着行情于昨晚逐步转向下行,James Wynn 的仓位也开始出现浮亏。
今日早间,随着 BTC 加速下跌,James Wynn 先是紧急减仓 BTC 多单至 5782 枚(约 6.24 亿美元),并将爆仓价下调至 107390 美元。
随后,James Wynn 又以 85.8 万美元的亏损平掉了其 PEPE 多头仓位。
利润大幅回撤
Odaily 星球日报监测到,截至今日上午 9: 33 ,即距离 James Wynn 昨日“金盆洗手” 24 小时后,其在 Hyperliquid 上的仓位 24 小时已浮亏 1477 万美元,回吐过半总利润。
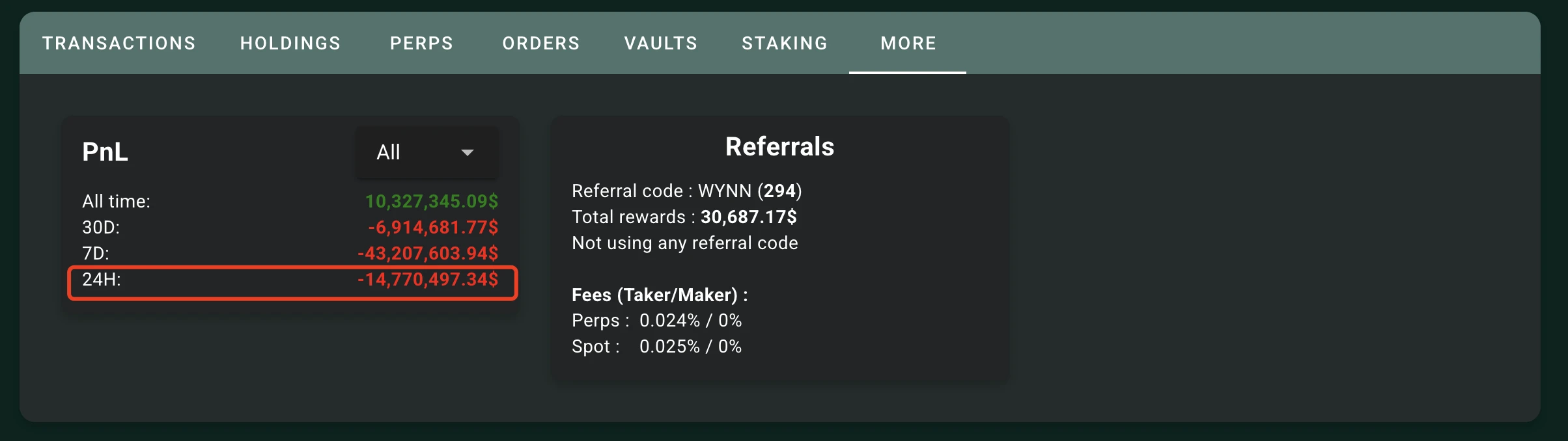
截至今日 10: 15 ,James Wynn 在 Hyperliquid 上历史总利润已回撤至 912 万美元左右,较昨日短暂离场前的 2500 万美元已大幅缩水,回撤幅度约为 63.5% 。
昨日传奇,今日赌狗?
你很难不感叹交易市场的风云变迁之迅速。
假设 James Wynn 昨日真的“金盆洗手”了,那么在名望巅峰之际带着巨额利润离场的他必然会成为加密货币历史上的一大传奇,但短短 24 小时内,围绕着 James Wynn 的讨论情绪却从膜拜、羡慕快速转为了吃瓜、调侃。
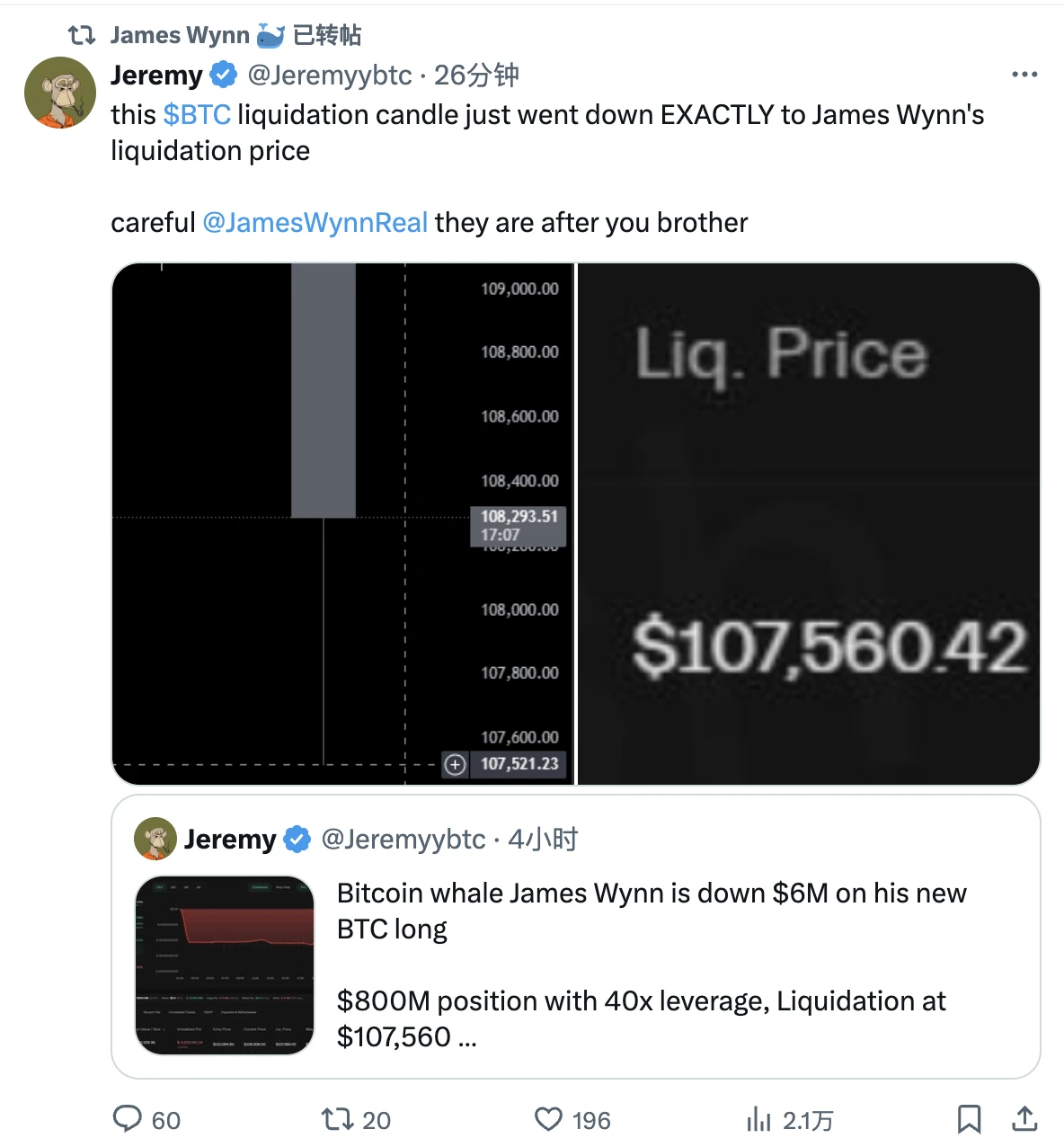
截至发文,James Wynn 这位向来发言极为高频的交易员(多少有些表演型人格)并未就最新的亏损发表评论,只是转发了另一位 X 用户 Jeremy 关于“有些人正在狙击 James Wynn”的评论 —— 或许在 James Wynn 的眼里,这不仅仅是一笔简单的交易,而是一场真正的战斗。
已发生过的事请永远不可逆,或许正是这样大胆、激进的风格才成就了如今的 James Wynn。这是他的来时路,但这条路最终会带他走向哪里,可能连 James Wynn 自己都没有答案。