June 22, 2026 — The new model "Fugu" released by Sakana AI sent shockwaves through the AI community. In the rigorous SWE-Bench Pro and TerminalBench benchmark tests, Fugu Ultra scored 73.7 and 82.1 points respectively, surpassing GPT-5.5 and Claude Opus 4.8, and even claimed to be on par with the export-controlled Fable 5 and Mythos Preview. Surprisingly, the core of this system, which topped the charts in engineering and reasoning capabilities, is not a massive model with hundreds of billions of parameters, but a model with only 7B parameters. It doesn't do the work itself; instead, it acts as a "project manager," dynamically orchestrating top global large models. This counter-intuitive architecture not only shatters the myth of "parameters equal justice" but also reflects Japan's path to AI breakthroughs amidst constrained computing resources.
The 7B "Project Manager": The Counter-Intuitive Architecture of Fugu
To understand the peculiarities of Fugu, one must first look at its origins. Sakana AI was founded in Tokyo in 2023 by Llion Jones, a co-author of the Transformer paper, and former Google researcher David Ha. From its inception, the company carried the "nature-inspired" gene, dedicated to solving AI problems with evolutionary algorithms and natural swarm intelligence. In 2025, Sakana AI secured investments from giants like NVIDIA and Google, valuing the company at over $25 billion. However, despite backing from these giants, Japan still lacks the massive computing infrastructure and data pools found in China and the US. Under these resource constraints, Sakana AI did not choose to compete head-on with trillion-parameter models but instead took an "orchestration" route.
Fugu is officially positioned as "a multi-agent orchestration system acting as a single foundational model." In traditional AI architecture, a large model is a "monolithic beast." A user inputs a prompt, and the model calculates from the first neural network layer to the last, outputting the result. This mode is extremely efficient for simple problems but often leads to hallucinations or logical breakdowns when facing complex, multi-step engineering tasks.
Fugu fundamentally changed this paradigm. Its core is a 7B-parameter model trained with reinforcement learning, called the RL Conductor. This 7B model does not directly generate the final answer; instead, it plays the role of a "project manager." When a user submits a task through a single OpenAI-compatible API, the RL Conductor dynamically analyzes the task type and then assigns subtasks to top global models in its agent pool, such as GPT-5, Gemini 3.1 Pro, or Claude Opus 4.8. It is responsible for scheduling, verifying, and synthesizing the outputs of these models, ultimately providing a result that has undergone multiple rounds of verification.
The theoretical underpinning for this architecture comes from two papers at ICLR 2026: "TRINITY: An Evolved LLM Coordinator" and "Learning to Orchestrate Agents in Natural Language with the Conductor." The papers detail how a small-parameter model can "conduct" large models through reinforcement learning. This changes the paradigm of "Test-time scaling." In the past, computing power was primarily used for deep inference within the model, making the model "struggle" for an answer. Now, computing power is used for external scheduling, verification, and synthesis. Traditional large models are monolithic all-rounders, while Fugu is a team of experts. The 7B RL Conductor proves that model parameter size is no longer the sole determinant of capability; knowing how to call tools and external agents can also lead to performance leaps.
The Truth Behind the Scores: Matching Fable and Surpassing GPT-5.5
The immediate reason for Fugu's sensation is its benchmark scores in rigorous tests. In the AI industry, benchmark scores are the hard currency for measuring model capabilities, but different benchmarks focus on entirely different aspects. The SWE-Bench Pro and TerminalBench 2.1 chosen by Sakana AI are both "tough nuts" biased towards real-world engineering environments.
SWE-Bench Pro focuses on software engineering capabilities, requiring models to locate and fix bugs in real codebases. According to data published in the Sakana AI console, Fugu Ultra scored 73.7 on SWE-Bench Pro. For comparison, Claude Opus 4.8 scored 69.2, GPT-5.5 scored 58.6, and Gemini 3.1 Pro scored 54.2. On TerminalBench 2.1, another test for system operation capabilities, Fugu Ultra scored 82.1, surpassing GPT-5.5's 78.2 and Opus 4.8's 74.6. These two tests not only examine a model's code generation ability but also its logical stability and tool-calling capability in multi-step, long-chain tasks. Fugu Ultra's lead means it experiences fewer mid-process crashes or deviations from goals when handling complex engineering problems compared to monolithic models.
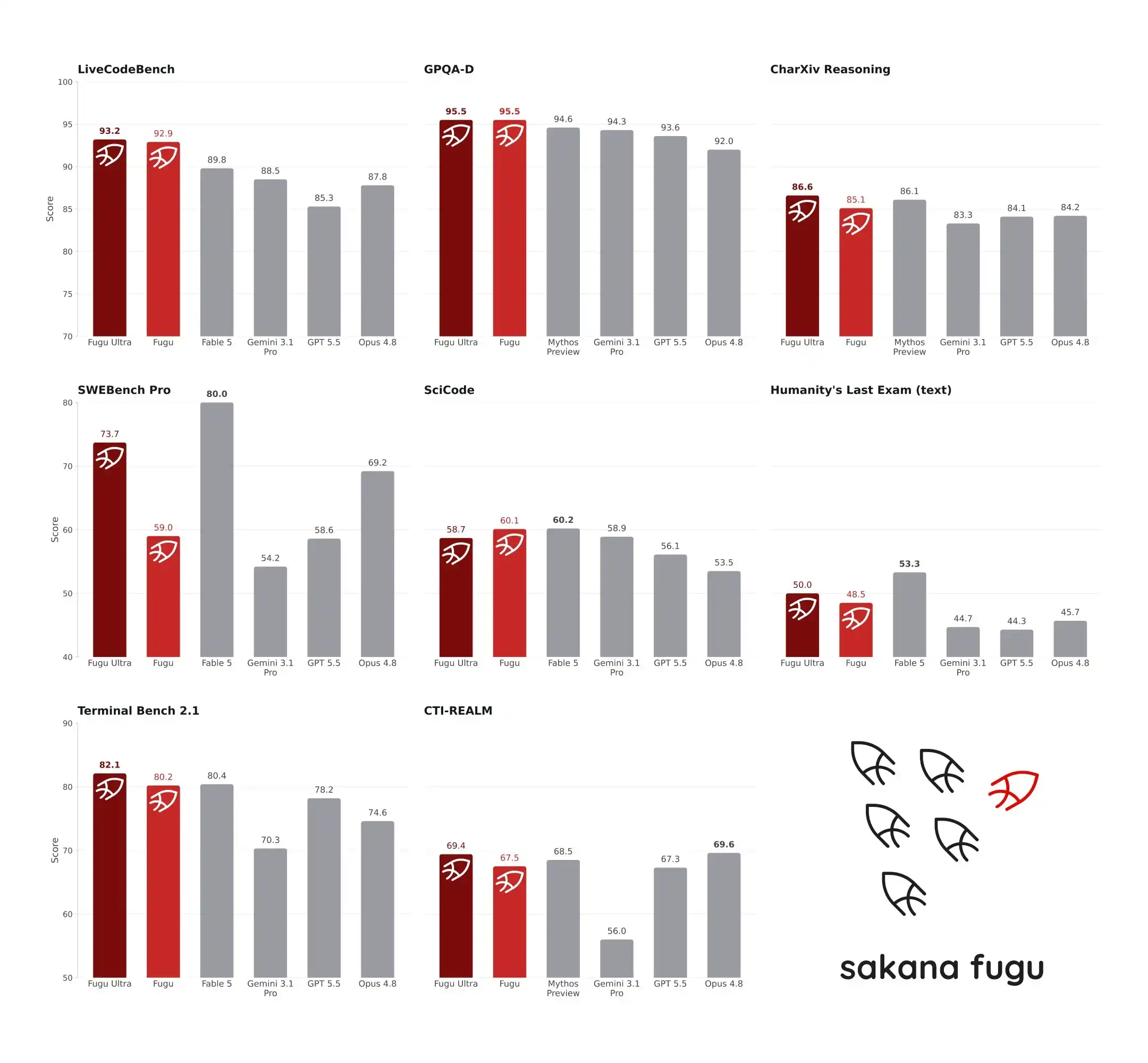
More attention was paid to the comparison between Fugu and Fable 5/Mythos Preview. Anthropic's Fable series and another frontier lab's Mythos series represent the pinnacle of current AI reasoning capabilities. However, due to export controls or incomplete public release, these two models are not part of Fugu's agent pool. Sakana AI officially claims that Fugu Ultra is "on par" with Fable 5 and Mythos Preview on engineering and science benchmarks. It must be clarified, however, that this comparison is not based on head-to-head testing in the same pool. Fugu's scores are based on actual runs of its own system, while Fable and Mythos data are based on report scores publicly released by their respective vendors.
This comparison methodology has sparked some controversy in the developer community. Some argue that test conditions across different systems and environments are difficult to align perfectly, making direct score comparisons unfair. However, other developers point out that referencing vendor-reported data is industry practice in the absence of a unified testing environment. Setting aside the controversy with Fable and Mythos, Fugu Ultra's surpassing of GPT-5.5 and Opus 4.8 on SWE-Bench Pro and TerminalBench 2.1 is a real, like-for-like comparison. This surpassing is not because Fugu's underlying model is smarter than GPT-5.5, but because the RL Conductor performs task decomposition and expert scheduling more precisely. In experiments requiring multiple rounds of reasoning and verification, such as AutoResearch, Rubik's Cube solving, and mechanical design, Fugu consistently showed advantages. This indicates that in handling "long, messy, multi-step" real-world workflows, the multi-agent orchestration architecture indeed offers more resilience than monolithic models.
Real Development Scenario Tests: Code Review and Long Session Stability
For developers and AI tool users, benchmark scores are only references. What truly determines a model's usefulness is its performance in real work scenarios. Fugu underwent beta testing with nearly 500 early users before release. Their feedback revealed Fugu's unique value in practical applications.
Code review is one of the most common AI scenarios for developers. Traditional monolithic models often only find superficial syntax errors or common logic bugs when reviewing code. In beta testing, some developers reported that Fugu demonstrated unusually detailed performance in code reviews, capable of uncovering deep architectural bugs, while other tools often found only a few surface-level issues. This difference stems from Fugu's architecture. Upon receiving a code review task, the RL Conductor can call models specializing in static analysis, logical reasoning, and security auditing respectively to conduct cross-validation on the same piece of code from multiple angles. This "expert consultation" model naturally uncovers more hidden problems than the "solo effort" of a single model.
Another frequently mentioned advantage is long-session stability. When building AI Agent products, one of developers' biggest headaches is the model's "persona drift" in long conversations. As the number of dialogue rounds increases, monolithic models often forget the initial setup or deviate in instruction following. After testing, some enterprise executives reported that Fugu's Persona in long conversations is exceptionally stable, with almost no drift. This is because the RL Conductor itself is not responsible for maintaining long-text memory; it only selects the most appropriate underlying model to generate a response in each dialogue round based on the current context. This architecture of "separation of control and generation" greatly improves Agent stability during long-running sessions.
In the field of cybersecurity, Fugu also demonstrated end-to-end practical capability. In tests, Fugu could independently complete the entire workflow from reconnaissance, XSS/SQLi vulnerability detection to authentication review, and generate a complete penetration test report, strictly adhering to instructions not to cross boundaries and damage systems. This level of completion for complex tasks relies on the RL Conductor's precise orchestration of security toolchains and the capabilities of different large models.
In addition, token efficiency is a major highlight of Fugu. Traditional large models often generate lengthy chains of thought, consuming a large number of tokens when dealing with complex problems. Fugu's RL Conductor avoids wasteful long CoT consumption through precise routing. Official data and early testing show it can significantly reduce waste of ineffective tokens. For developers billed by tokens, this means not only cost reduction but also improved response speed.
The Achilles' Heel of Underlying Dependency: The Cost of Multi-Agent Orchestration
Although Fugu shines in architecture and benchmark scores, as a tool for practical work, it is not without weaknesses. The multi-agent orchestration architecture, while bringing performance breakthroughs, also introduces significant risks and limitations.
The core issue is underlying dependency risk. Fugu's agent pool heavily relies on underlying APIs from US giants like GPT, Claude, and Gemini. Although the RL Conductor has dynamic routing capabilities and can switch to other models if one fails or is rate-limited, this only mitigates single-supplier risk. It does not and cannot detach from the entire US AI infrastructure ecosystem. If these underlying models collectively raise prices, impose large-scale rate limits, or change API terms, Fugu's cost structure and stability will be directly impacted. This "parasitic" mode, living atop others' infrastructure, has inherent fragility in commercialization and long-term stability.
Next is the trade-off between latency and cost structure. While the RL Conductor saves on ineffective token consumption through precise routing, multi-agent orchestration inevitably involves multiple API calls and inter-model communication. For real-time interaction scenarios requiring extremely low latency, such as real-time voice conversations or high-frequency trading assistance, Fugu Ultra's "deep thinking and scheduling" time may be longer than directly calling a monolithic model. In scenarios where response speed is paramount, Fugu's architectural advantage could become a drag on user experience.
Furthermore, controversies over fairness of comparison persist. As mentioned, Fugu claims parity with Fable and Mythos, but the latter two are not in its agent pool. In the developer community, some voices question whether comparisons based on vendor-reported data have practical reference value. After all, model performance can vary greatly across different task distributions, and simple aggregate score comparisons might mask specific strengths and weaknesses. For developers needing precise model capability assessments, the lack of head-to-head test data means they must remain cautious during selection.
Not Competing on Compute, but on Orchestration: Japan's Asymmetric Breakthrough in Large Models
Looking beyond the specific product review, Fugu's birth carries deeper implications for Japan's large model ecosystem. In the global AI arms race, Japan is in an awkward position. It lacks both the continuous influx of top-tier computing power and frontier algorithm accumulation of the US, and the massive data pools and fiercely competitive market environment of China. More critically, Japan also faces export control risks from US frontier models (like Fable/Mythos). Against this backdrop, Sakana AI's "evolutionary algorithm" and "multi-agent orchestration" route showcase the logic of "asymmetric breakthrough" for a resource-constrained nation.
Japan does have domestic large model players. NTT released tsuzumi, and institutions like ELYZA, Rinna, and LLM-jp are also working hard to train local language models. However, most follow the traditional "train from scratch" route, struggling to compete with top US and Chinese models in parameter scale and general capabilities. Sakana AI is the only Japanese lab with global frontier influence that champions an "asymmetric architecture."
Fugu's dynamic routing capability essentially helps Japanese companies and institutions establish "AI Sovereignty." Under limited computing resources, instead of spending huge sums to train a hundred-billion-parameter model that is inferior to GPT-5.5 in all aspects, it's better to train a clever 7B "project manager." This manager can flexibly connect to the world's best models based on task needs. If one day a US model faces export controls or supply cuts, the RL Conductor can quickly route tasks to other available models, even connecting to Japan's domestic specialized models. This architecture gives Japan a degree of autonomy and risk resilience in utilizing AI capabilities.
Observing the global AI tool ecosystem, OmniTools notes that large model capabilities are gradually leveling, and the main battleground of competition is shifting from mere parameter stacking to toolchains and landing scenarios. The emergence of Fugu precisely confirms this trend. It no longer pursues perfection in a single model but pursues optimality at the system level. This thinking holds significant reference value for nations and regions lacking advantages in compute and data.
Of course, this "asymmetric breakthrough" has its ceiling. As long as the core technology of underlying models remains in the hands of a few giants, the capability ceiling of orchestration systems will be limited by those underlying models. Fugu proves a 7B model can be an excellent conductor, but it cannot magically create capabilities that the underlying models lack. For Japan's large models to truly achieve a breakthrough, beyond architectural innovation in orchestration, continued investment in underlying computing power, core algorithms, and high-quality data is still necessary. Fugu is an ingenious system-level innovation, but it's not a panacea. For developers and enterprise users, Fugu provides a highly competitive new option in complex engineering scenarios. However, when using it, one must also be clear-eyed about its underlying dependency vulnerabilities and the latency-cost trade-offs.







