TL;DR
A chart estimating the breakdown of the approximately $20 monthly fee for Claude Pro in the U.S. among model companies, cloud computing power, GPU depreciation, electricity, and the supply chain is prompting investors to re-evaluate how to value AI application revenue.
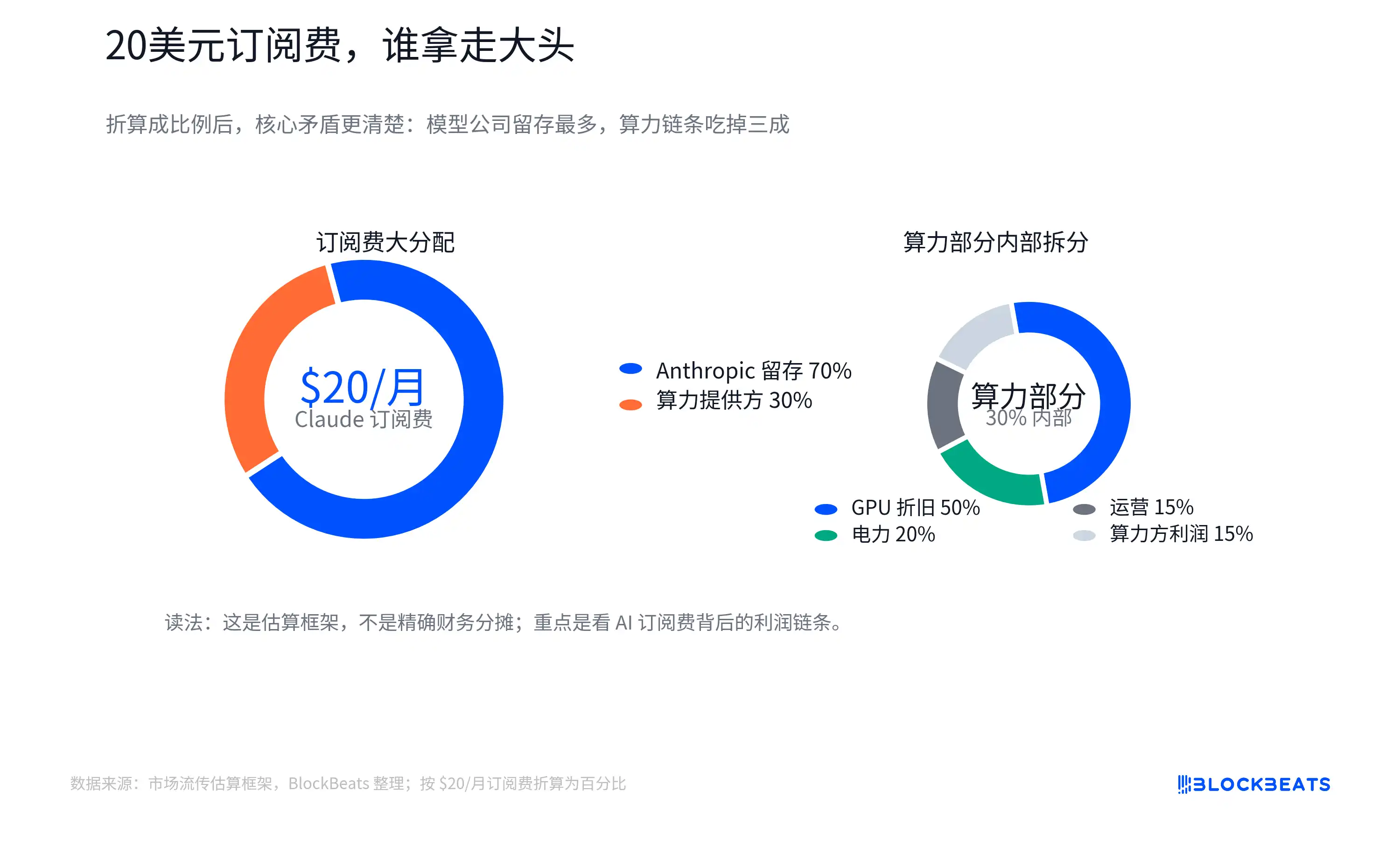
This chart is not official revenue-sharing data from Anthropic, Amazon Web Services, or NVIDIA, nor should it be treated as the real financials of any specific company. Its value lies in raising a more fundamental question: How much of the subscription fee users pay to AI applications can solidify into software gross profit, as seen with traditional SaaS?
The valuation story for traditional SaaS is clear. Once the software is developed, selling an additional account typically incurs low incremental costs. Mature pure software companies commonly achieve gross margins of 70% or even over 80%. Investors are willing to assign high multiples because profitability often has room to improve further as revenue scales.
The trouble with AI applications is that every user query—be it writing code, analyzing documents, or calling an agent—consumes GPU time, electricity, memory bandwidth, and cloud resources behind the scenes. On the surface, it's a fixed monthly fee, but underneath lies a cost chain that varies with usage volume. Light users might be highly profitable, but for heavy users continuously running tasks within their usage limits or relevant tool packages, costs can escalate rapidly.
Therefore, the $20 breakdown chart aims to challenge not how many dollars a specific company takes, but whether "AI application revenue inherently equals SaaS revenue." For AI companies to justify high valuation multiples, they need to demonstrate not just that users are willing to pay, but also that the weighted gross margin after accounting for usage volume can continuously improve.
Behind the Subscription Fee Lies an Inference Cost Chain
The biggest difference between an AI subscription and a regular software subscription is that the marginal cost of "one use" is no longer close to zero.
In traditional SaaS, when a team adds an account, the service provider also incurs server, customer support, and bandwidth costs, but these costs typically don't increase linearly with every click. The real expenses are upfront R&D, sales, and customer acquisition. After the product scales, a significant portion of new revenue can be retained as profit.
Large language model products are different. A user inputs a question, and the model generates an answer. This process is called inference—the actual computation when the model is invoked by the user. Tokens are the basic unit for measuring the text the model reads and writes. The more users ask, the longer the context, and the more complex the generated content, the more tokens and computing power are consumed.
This creates a tension between fixed subscription fees and variable costs. The monthly fee for Claude Pro in the U.S. is roughly $20 (subject to region, taxes, and adjustments by Anthropic). Users see a fixed price, but the model company faces widely varying usage behaviors. Some users only write emails and look up information, while others process long documents, run coding tasks, or invoke more complex automated workflows.
The circulating breakdown chart attempts to visualize this: out of the $20, a portion remains with the model company, and another portion goes to cloud and computing power providers. Computing power costs include electricity, operations, and GPU depreciation. GPU procurement flows further upstream to NVIDIA, TSMC, HBM (High-Bandwidth Memory) suppliers, optical modules, ODMs, and electricity-related companies.
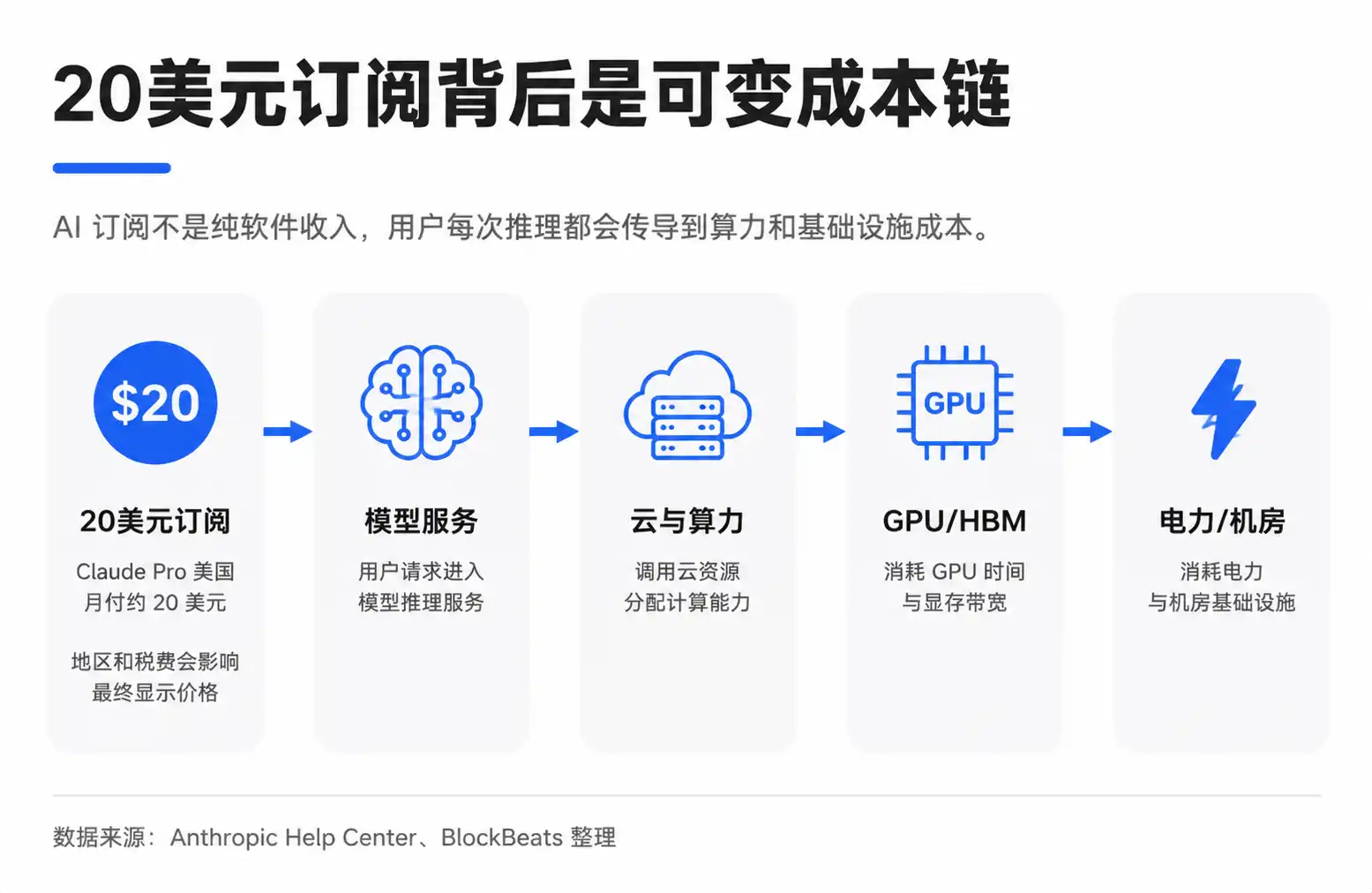
Here, "GPU depreciation" can be understood as the expensive GPU cost not being accounted for all at once, but gradually amortized into the AI service based on useful life, intensity of use, or accounting rules. The actual allocation is influenced by factors like plan limits, the mix of light and heavy users, internal cloud provider pricing, reserved capacity discounts, GPU utilization, and depreciation periods. Average cost is not the same as marginal cost.
The direction investors truly need to watch is this: AI application companies cannot just disclose revenue growth; they must also answer whether computing power costs are growing in sync with that revenue growth. If usage volume expands faster than model efficiency improves, the higher the subscription revenue, the more pressure there may be on gross margins. Only with sufficient improvement in efficiency can model companies have a chance to approach the profit structure of software companies again.
Infrastructure Gets More Certain Revenue First
At this stage, the growth in AI usage flows more directly to infrastructure rather than all solidifying at the application layer.
Regardless of whether users engage with models through Claude, ChatGPT, Gemini, or internal enterprise agents, inference ultimately lands on computing power, electricity, memory, and networks. The application layer may see product turnover, but the consumption of underlying resources is more rigid. As long as AI usage continues to rise, cloud capital expenditures, GPU procurement, HBM demand, and data center electricity consumption will be driven up.
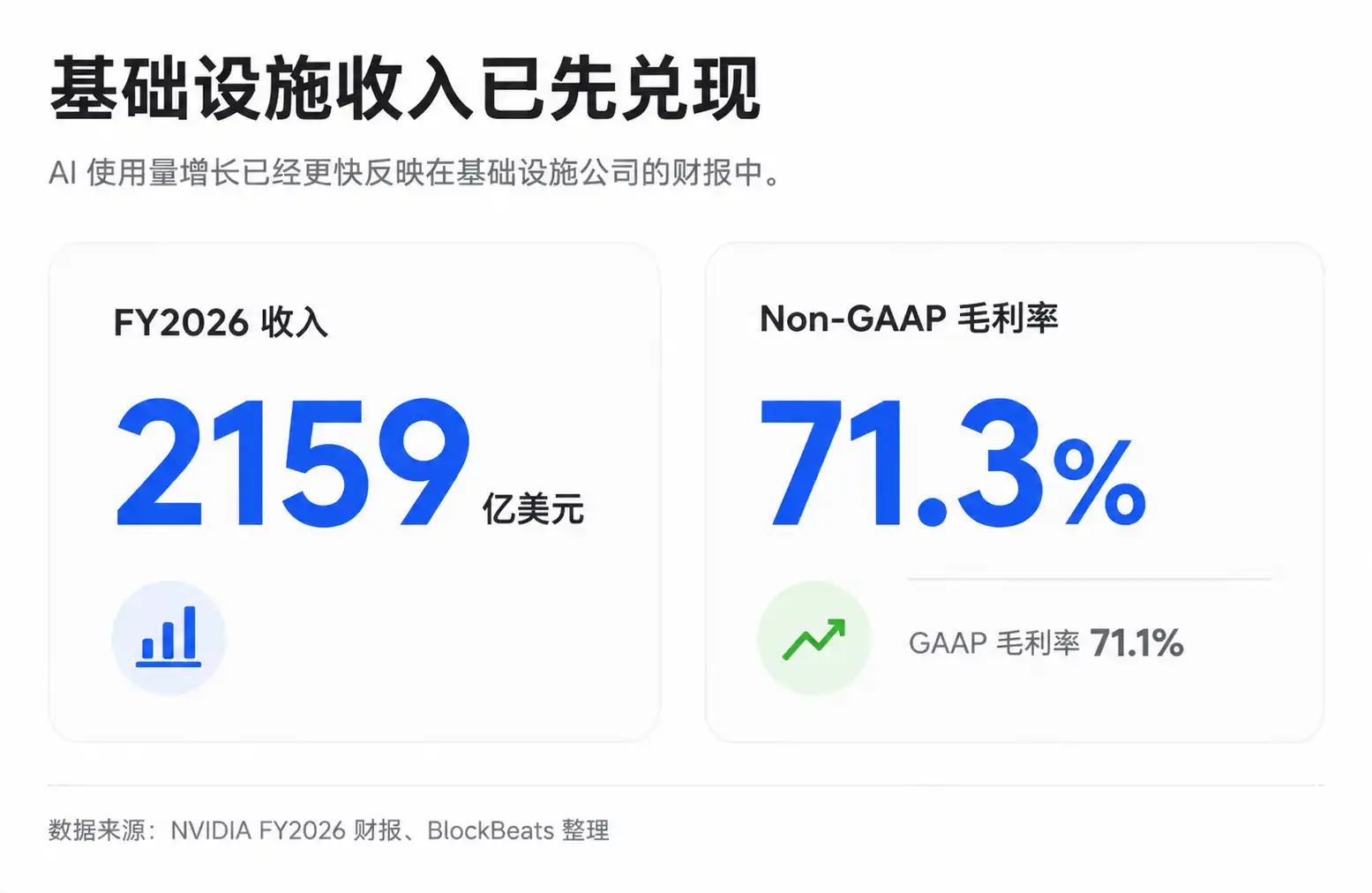
This is also why infrastructure chain players like NVIDIA, TSMC, and SK Hynix continue to be revalued by the market. NVIDIA's overall gross margin has been at high levels in recent years, with FY2026 GAAP and Non-GAAP gross margins at approximately 71.1% and 71.3%, respectively, with subsequent quarterly guidance remaining high. Note that individual quarters can be affected by specific charges, and public filings don't always allow a clean breakout of the real gross margin structure for AI data centers, but the pricing power of scarce infrastructure is already reflected in the financials.
HBM is a typical link in this chain. It's not ordinary memory but a key component in AI accelerators that supports high-throughput computing. As model scale, context length, and concurrent inference demands increase, AI chips become more reliant on high-bandwidth memory. Supply chain estimates indicate HBM accounts for a growing share of the cost in new-generation AI chips, which is a key reason why SK Hynix, Samsung, and Micron are being revalued in this AI cycle.
Electricity and data centers have also moved from background costs to a key investment theme. The energy consumption of a single ordinary text query might not be staggering, but complex agents, long contexts, code generation, and multi-step tasks amplify the computational load. For cloud providers and data center operators, the key isn't how much electricity one query uses, but what happens when massive inference requests occur continuously: cluster utilization, electricity prices, cooling, facility capacity, and grid access all become cost factors and bottlenecks.
The advantage for the infrastructure end is that performance verification is faster. Cloud providers' AI capital expenditures are already happening; NVIDIA's revenue and gross margins appear in its reports; HBM vendor orders and pricing also enter P&L statements relatively quickly. The model application layer trades more on future expectations: subscription conversion, enterprise penetration, API revenue, and the release of profits after the future cost curve declines.
Efficiency Improvements Remain the Core Argument for Bulls
Software investors and AI bulls do have counterarguments. The core view of the efficiency camp is that today's relatively high inference costs are merely a phenomenon of the early stage. Model optimization, caching, smaller models, custom chips, and higher cluster utilization will continuously drive down unit costs. If costs fall fast enough, AI applications may still return to a high-margin software logic.
This rebuttal has a basis in reality. Some mainstream models have seen significant price drops per token while maintaining or improving capability. OpenAI has disclosed that GPT-4o mini's cost per token has decreased by 99% compared to the earlier text-davinci-003. The pace isn't uniform across all companies—Anthropic has recently focused more on same-price upgrades and model tiering—but the industry direction is still to provide stronger capabilities at lower cost.

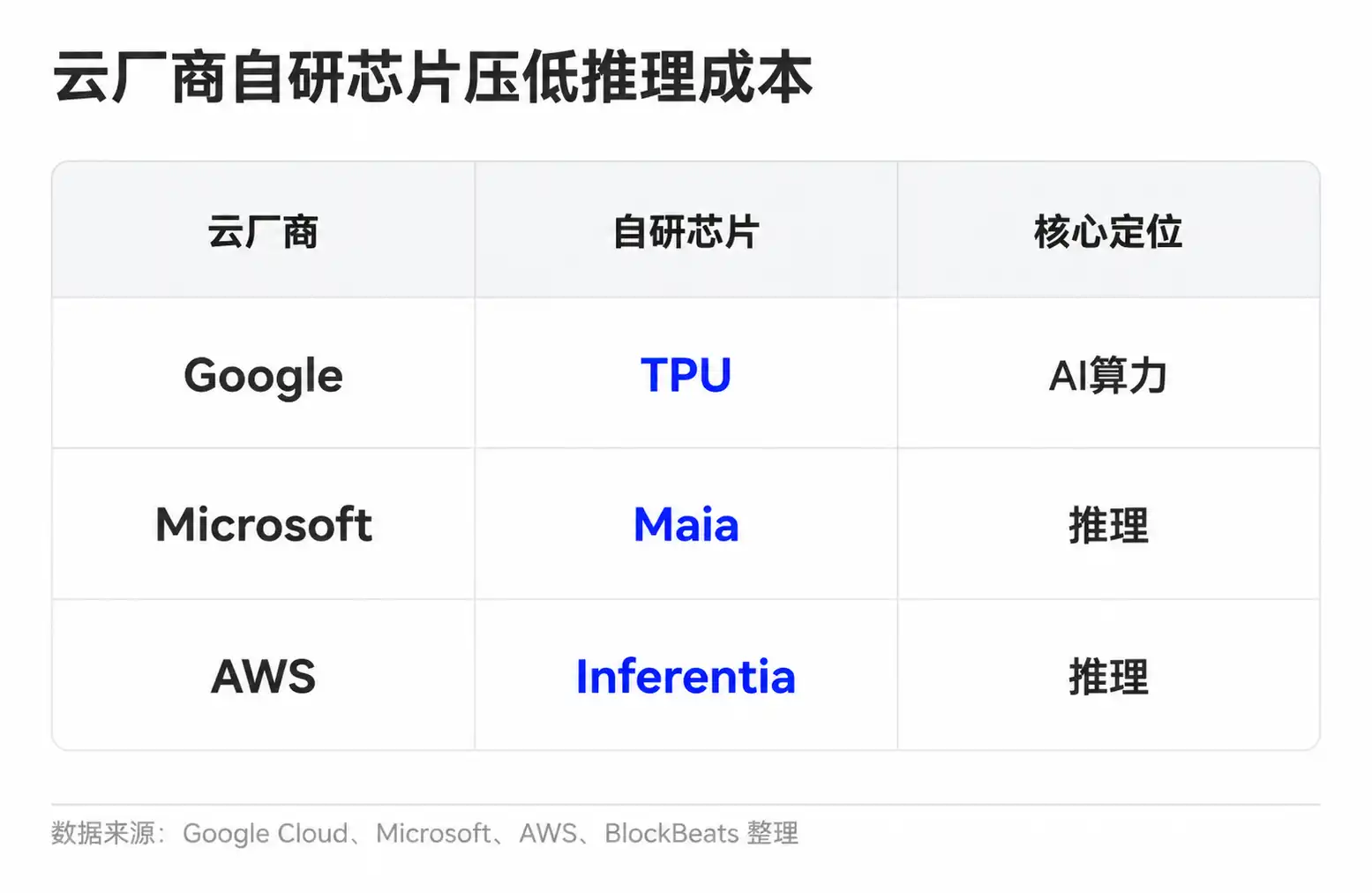
Model companies also have multiple ways to improve unit economics. Simple tasks can be routed to smaller models; common requests can be reused via caching; long-context and complex tasks go to stronger models. Cloud providers, meanwhile, aim to lower unit computing costs through custom chips and cluster scheduling. Google has TPUs, Microsoft has introduced Maia for inference, and Amazon is advancing Trainium and Inferentia.
Looking purely at technological progress, there is indeed room for AI application margins to improve. Cheaper inference, better model routing, and stronger compression capabilities can all allow the same $20 subscription to handle more usage. Light users, higher-priced enterprise plans, tiered API pricing, and stricter usage limits can also improve overall unit economics.
The difficulty lies in the fact that cost reduction isn't the only variable. AI applications are evolving from simple chat to heavier workloads. In the past, users might have only asked questions and rewritten text. Now, more demand comes from coding agents, long document processing, video and multimodal generation, and enterprise automation workflows. These scenarios offer higher value but also higher consumption. The more useful the model, the more likely users are to entrust it with more complex, longer-duration tasks.
The disagreement thus becomes more specific: Can the speed of inference cost decline outpace the growth in usage volume and task complexity? If unit costs fall rapidly, but average user consumption grows even faster, the model company's weighted gross margin will still face pressure. Conversely, if model routing, caching, custom chips, and price tiering are effective enough, AI subscriptions could gradually shed today's heavy-cost characteristics.
Subscriber Count Is Not Gross Margin
The $20 breakdown chart shouldn't be interpreted as the final outcome. It's more like a valuation reminder for the current stage: When the market still lacks sufficiently transparent gross margin data from model companies, investors need to discount the assumption that "AI application revenue inherently equals SaaS."
For unlisted model companies like OpenAI and Anthropic, external investors have little access to a complete financial picture. Clues will come from fundraising materials, partner disclosures, cloud cost structures, enterprise plan pricing, the proportion of API revenue, and usage limits. The truly valuable data isn't how many paying users there are, but the proportion of light versus heavy users, whether enterprise clients are willing to pay higher prices for intense usage, whether cloud settlement costs are declining, and whether unit inference cost reductions are flowing into company gross margins.
Validation in the public company chain will appear faster in financial reports. NVIDIA's overall gross margin and data center revenue growth, TSMC's demand for advanced processes and packaging, HBM vendor pricing and profit margins, and the intensity of cloud providers' capital expenditures will all continue to reflect whether AI usage is still being channeled to the infrastructure end. If these indicators remain strong while the model application layer lacks evidence of gross margin improvement, the market will likely continue to assign a more certain valuation premium to infrastructure.
Ultimately, for model companies to reclaim a higher valuation anchor, they need to prove not just that users are willing to pay $20, but that these subscription fees, after accounting for heavy usage, can still leave behind sufficient gross profit. The next round of valuation divergence likely won't be over the headline ARR numbers, but over whether inference costs, plan limits, and enterprise pricing can all work out simultaneously.





