Conducting technical research is actually a trap-filled endeavor (for both humans and AI). After all, from the beginning of the investigation, you receive a massive amount of information. Views and opinions pile up, and conclusions become increasingly vague. So, it's always crucial to remember to return to the original goal.
This is also why AI hasn't been excellent in this area for a long time. From the perspectives of attention and associative thinking, it tends to get even more trapped by the current volume of information and is weak at making truly valuable cross-disciplinary connections.
Of course, where AI excels is in its execution capability. It can search, summarize, and conclude layer by layer in the form of agents, completely avoiding the loss of details.
Although I haven't published much on my public account in the past six months, I've been closely following and researching major developments across almost all mainstream sectors in the industry. What supports this input and output is my own deep-research system.
Facing the launch of the Dynamic Workflows feature in Claude Code last week, I wanted to challenge it against my own system to see if its default capabilities could completely surpass mine.
2. What is Dynamic Workflows?
Dynamic Workflows has a core concept: before executing a task, the AI first automatically designs what workflow should be used to complete this task, and then initiates the execution.
This is fundamentally different from the "plan mode" and "skills" we used before. Plan mode breaks down tasks into finer details, but not necessarily according to a reasonable workflow. Only as you arrange your prompts might it add acceptance criteria (crucial for research); similarly, it only sets up harness rules better when given prompts.
But Dynamic Workflows automatically incorporates acceptance logic, result convergence, adversarial verification, and similar elements.
The trigger is simple: directly use the /deep-research command in Claude Code and provide some research templates and entry materials. If you want to use the dynamic workflow capability alone, you can use a specific prompt or directly say 'ultracode'. Before using, note that token consumption is about tens of times higher than normal.
3. The Six Built-in Workflow Patterns
The underlying foundation of Dynamic Workflows is six core orchestration patterns summarized by the developers. This is why it's more powerful than regular conversations/agents/skills.
Actually, behind these six patterns lie only two core questions: How to split the task? How to merge the results? Splitting them into six is essentially a permutation and combination of these two.
3.1 Router Pattern (Classify-And-Act)
First, one agent determines the task type, then distributes the task to the most suitable specialized agent to handle. The core logic is the selection logic of the router, not parallelism or iteration. A task follows only one path; other paths are not executed at all.
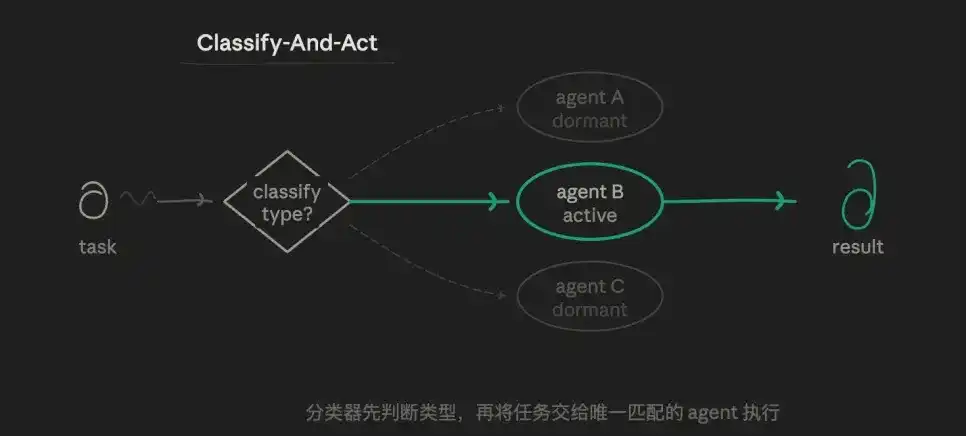
For example, I could pre-define three sub-agent roles: one analytical agent that strictly verifies data, one output agent skilled in writing, and one challenge agent specialized in finding vulnerabilities. The routing layer judges which sub-task is suitable for whom, rather than having one agent handle everything.
The value of this pattern lies in: precision and frugality. Each agent's prompt can be highly independent, not interfered by other objectives, enabling exploration with vertical depth. Token consumption is lowest, response speed is fastest. Responsibility boundaries are very clear.
The drawback is also significant: weak handling capability for tasks with blurry boundaries (e.g., "both a technical and an account issue").
3.2 Split & Merge (Fan-out & Merge)
Also my most commonly used pattern. The core logic is parallel + merge. The task is split into N independent subtasks to run simultaneously, and after all are completed, they are uniformly merged.
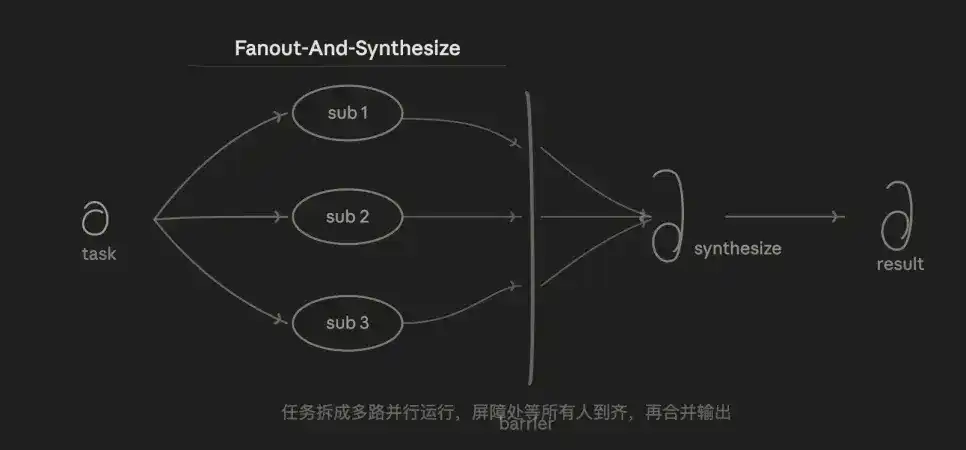
The advantage lies in speed and isolation. The total time taken is approximately equal to the slowest subtask, not the sum of all subtasks. Each subtask has an independent context, not interfering with each other, and noise from one subtask won't pollute others.
The weakness is that token cost is N times that of serial execution, and the merge layer (Synthesize) itself is challenging—how to fuse N structurally inconsistent outputs is a design challenge. Poor subtask division can lead to omissions or repeated coverage.
3.3 Adversarial Verification
The core logic is inspection. For the same conclusion, multiple agents challenge it from a "refutation" perspective; it only passes if a majority vote is reached.
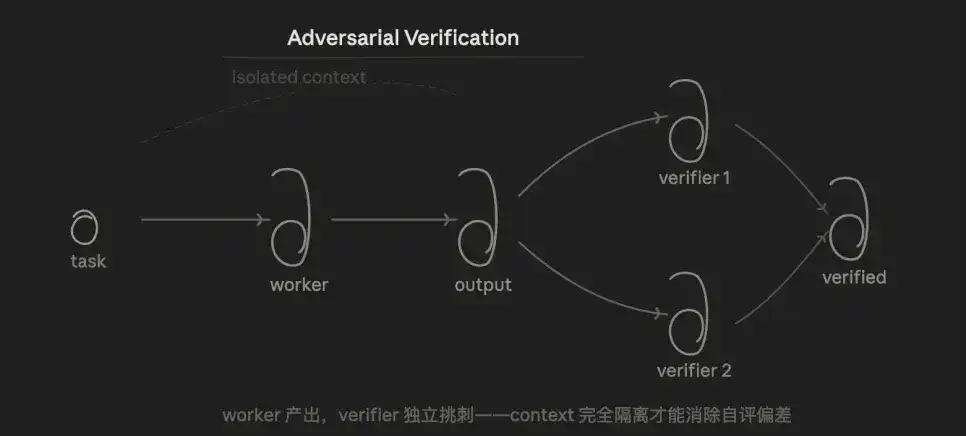
The advantage is that, since the Verifier doesn't know the Worker's line of thought and only looks at the result, it structurally eliminates the self-assessment bias that occurs when "asking the model to check its own code."
This pattern solves a problem that has long troubled me: we often chat with AI in a colloquial manner, but AI tends to answer according to your expectations, easily leading to "confirmation bias." Adversarial verification forces the AI to look for counterexamples and to verify based on data and experiments, not just cater to your ideas.
However, when it comes to verification, if it gives wrong judgments, it can mislead the Worker to cater to the Verifier. Therefore, it's better to prefer verification based on reproducible facts rather than relying on opinions.
Jokingly speaking, if you ask AI to find problems, it can find endless issues, so you must limit the boundaries within which it can search for problems.
3.4 Generate & Filter
The core logic is diverge then converge. Deliberately produce an excessive number of candidates first, then use a rubric to filter down to the essence, retaining only high-confidence results for output.
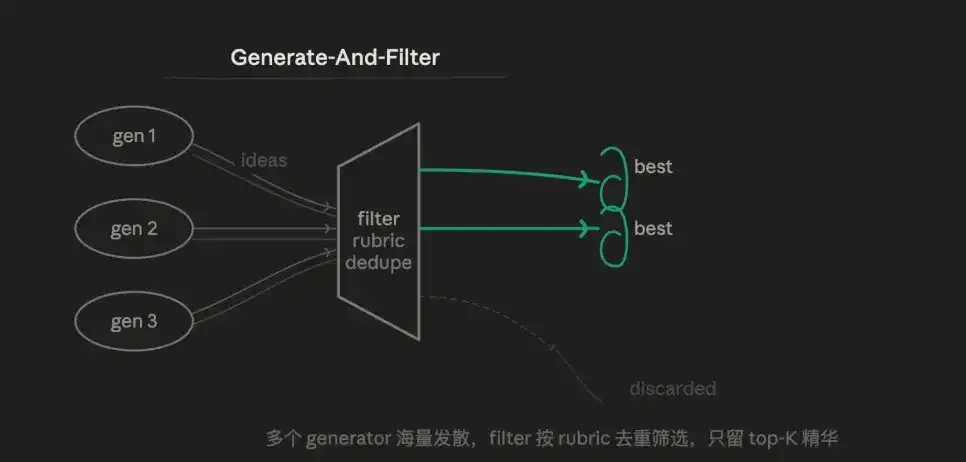
Instead of letting one agent output a "decent" answer, have it generate ten, then filter with a verification layer. Therefore, the advantage lies in diversity. Multiple Generators can use different strategies and prompts to produce solutions hard to anticipate manually, and the filtering step ensures highly concentrated final output quality.
The weakness is that the quality of the Filter's rubric directly determines the final outcome. A poorly designed rubric renders the entire process useless.
Suitable scenarios are situations where the correct answer is unknown beforehand, needing to choose the best from multiple possibilities, or where there's a clear need for diversity.
It's only superficially similar to Fan-out-And-Synthesize: Both are "multi-path parallel → single output," making them easiest to confuse.
The key difference lies in the intent: Each path in Fan-out handles a different part of the task; results are complementary, and all paths contribute during merging. In Generate-And-Filter, each path handles the same task; results are competitive, and most are discarded during merging. The former is a "jigsaw puzzle," the latter is a "beauty pageant."
3.5 Tournament Pattern
The core logic is competitive elimination. N agents each independently do the same thing, eliminated round by round through pairwise comparison, ultimately selecting the best solution.
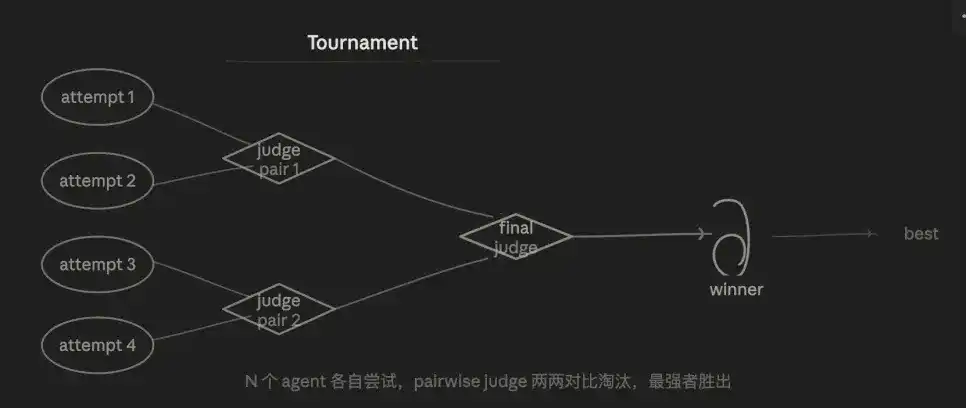
I've done this manually before—running two or three versions of the same code change, then having AI compare which is better. Now it can be orchestrated directly within the workflow.
The advantage lies in judgment stability. Pairwise comparison ("Which is better, A or B?") is much more stable than absolute scoring ("Score A") because it eliminates the problem of drifting scoring standards. The result goes through multiple rounds of competition, so the credibility of the final winner is high.
It's also superficially similar to Generate-And-Filter: Both select the best from multiple candidates. The key difference is the selection mechanism: Tournament uses pairwise judges for two-by-two comparison, which is "making candidates compete against each other." When the rubric is difficult to quantify or judgment is essentially relative, this is more reliable.
3.6 Loop Pattern (Loop)
The core logic is adaptive iteration: constantly trying, encountering resistance, collecting error information, supplementing context, retrying until meeting the acceptance conditions.
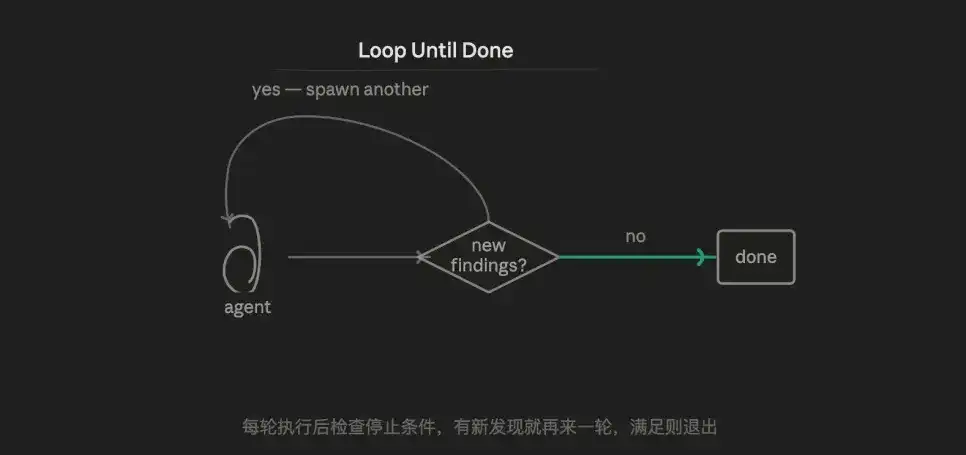
Essentially, it combats AI's randomness: try a few more times, and you'll eventually stumble upon a better result. But a more mature approach is to combine it with adversarial verification, making each iteration execute with more information, not just relying on randomness.
The advantage lies in handling capability for tasks with unknown workloads. The other five patterns assume the task boundary is determined. Loop Until Done is the only pattern that can handle "not knowing how many rounds are needed."
The weakness is the potential risk of losing control—poorly designed stopping conditions can lead to infinite loops. The agent in each round has a brand-new context and cannot accumulate cross-round state (unless explicitly written to a file).
4. The Battle Between My Own Skill and the Official Workflow
Before Dynamic Workflows came out, I had specifically designed my own deep-research skill. The logic of my skill roughly went like this:
- Give only simple information (e.g., a certain project launched a new feature).
- Let the AI search all related materials: official documentation, source code, market sentiment.
- Compress the information into meaningful summaries.
- Multiple agent roles conduct adversarial analysis to generate a report.
- Automatically deduplicate because multi-agent content often has high repetition rates.
After using it for a while, I thought it was quite useful. But it had a fundamental flaw: it lacked goal-oriented convergence.
Moreover, even with the fifth step of deduplication, it often deleted valuable information. Without deduplication, the skill would easily give you a 10,000-word long article—very comprehensive in information but failing to directly tell you "what does this have to do with you, what should you do?"
However, research serves "decision-making." This is why many skills can only stop at the research itself, achieving 80 points but missing the crucial final 20.
As a result, after AI preliminarily completes the research, it often requires ten more rounds of thinking and dialogue to reach a satisfactory, comprehensive conclusion.
What More Does the Official Dynamic Workflow Do?
Through several complex research task experiments this week, I found that the deep-research workflow built into Claude Code (note, not just a skill, but a module compiled and embedded into CC), compared to my own skill, adds several key steps:
- Problem Decomposition Layer: It doesn't start searching directly. Instead, it first asks questions, breaking my query into multiple sub-questions: What do you really want to clarify? How does this relate to you? Which dimensions are worth delving into? This step I used to skip.
- Credibility Assessment: Evaluates the falsifiability of each piece of information, similar to authority scoring in traditional SEO—is the source credible? What about citation counts? This is a step I hadn't thought to add before.
- Cross-cutting Deletion, Not Average Merging: My previous approach was to average and select all conclusions, so documents were large. Dynamic Workflows conducts multi-agent voting on each conclusion, deleting those with insufficient votes, not simply merging.
- Goal-oriented Output: The final report isn't an information dump, but provides judgment and suggested solutions centered around your original goal. The key to achieving this lies in its preset ability to orchestrate multiple sub-agents. The reason my skill often lacked final goal orientation was precisely because of instruction weight decay after massive amounts of information.
What Problems Do These Mechanisms Solve?
They target several typical problems when AI handles long tasks:
Goal Drift: Good state at the start of the task, losing track in the middle, and regaining rhythm at the end—similar to a human zoning out in class. More obvious with longer tasks.
Premature Stopping: Running along, encountering difficulty, the AI thinks it's "done" and stops, even though the acceptance criteria aren't met at all.
Context Pollution: A single agent handling a complex task compresses the execution space for subsequent steps with the large amount of preceding prompts. A better way is to control preceding prompts within a few thousand tokens and distribute context across multiple agents.
Output Bias: AI tends to answer along your expectations; colloquial questioning triggers this problem more easily.
Dynamic Workflows solves these four problems in a structured way: automatically adding acceptance criteria to prevent premature stopping; parallel isolation of context; adversarial verification to counteract output bias; decomposing the problem and constraining the AI layer by layer to first understand the goal before acting.
5. Summary
Finally, as a long-term research practitioner, I am astounded by this new CC mechanism. Its six built-in patterns—Router Selection, Split & Merge, Adversarial Verification, Generate & Filter, Tournament Competition, and Loop Cycle—cover the orchestration needs of the vast majority of complex research tasks.
I no longer need to manually design agent orchestration, nor handle deduplication and cross-validation myself; these are now built into the workflow itself.
Moreover, it's particularly suitable for open-ended exploration where information is lacking. Because its inherent multi-agent orchestration + task goal decomposition raises its generality once again. In fact, as early as three years ago, AI already did quite well in solving extremely clear, small problems under layered constraints. But the qualitative leap for AI truly lies in generality. Only then does its competition shift from simply solving one problem to becoming a true Agent, adapting from solid-state problem-solving to handling any problem.
So, Dynamic Workflows is not "smarter single conversations," but the structuralization of the research process itself.
Research that originally required me to initiate ten-plus independent conversations is now compressed to 3-4. Although the corresponding token consumption has increased tens of times.
So why still 3-4 times? I think the root cause lies in the differences of these demands.
First, the rigor of the verification mechanism. I mainly research new technologies on the blockchain. For many things, official documentation lags; there are more valuable reference sources like open-source code, on-chain transactions, etc. Currently, the AI still defaults to official documentation as the standard, not verification based on factual evidence.
Second, completely cross-disciplinary deep thinking. Although workflow presets can solve some of this (pre-defining various dimensional subAgents to think about the same issue), AI excels at mainstream thinking models. For the very new, very profound, lacking data basis, it's slightly insufficient.
Third, solution design and verification. The significance of a solution lies not in its proposal but in its verification and support. It relies on measuring existing mechanisms, investment, and costs. If AI is well-trained, it can certainly do better, but this somewhat contradicts generality.
Finally, extreme information condensation. This then requires returning to an understanding of the audience's background. Some people have no foundation and need you to explain in an anthropomorphic, vivid way, while some listeners need you to impress them in one sentence~.





