Catatan Editor: Banyak orang menggunakan Claude Code, kesan paling langsung adalah Token terkonsumsi terlalu cepat, sesi panjang mudah menghabiskan kuota. Tapi dari perspektif insinyur Anthropic, yang benar-benar memengaruhi biaya, seringkali bukan seberapa banyak kode yang Anda tulis, melainkan apakah sistem terus-menerus menggunakan kembali konteks yang telah diproses.
Inti dari artikel ini adalah cara menghemat Token melalui mekanisme caching. Penulis dalam seminggu menghemat lebih dari 300 juta Token melalui caching, dengan caching harian mencapai 91 juta. Karena biaya Token caching hanya 10% dari biaya Token input biasa, ini berarti 91 juta Token caching sebenarnya dikenai biaya setara dengan sekitar 9 juta Token biasa. Alasan sesi panjang Claude Code terasa lebih "awet", bukan karena model bekerja gratis, melainkan karena banyak konteks berulang berhasil digunakan kembali.
Kunci dari Prompt caching adalah "jangan mengganggu caching". Claude Code akan meng-cache prompt sistem, definisi alat, CLAUDE.md, aturan proyek, dan riwayat percakapan secara berlapis; selama awalan permintaan selanjutnya tetap konsisten, Claude dapat langsung membaca cache, bukan memproses ulang seluruh konteks. Anthropic internal juga memantau tingkat penggunaan kembali prompt cache, karena hal ini tidak hanya memengaruhi kuota pengguna, tetapi juga secara langsung terkait dengan biaya layanan model dan efisiensi operasi.
Bagi pengguna biasa, tidak perlu memahami semua detail teknis yang mendalam, hanya perlu menguasai beberapa kebiasaan kunci: jangan biarkan sesi kosong lebih dari 1 jam; lakukan session handoff saat beralih tugas; hindari sering mengganti model; dokumen besar sebaiknya dimasukkan ke dalam Projects, bukan ditempel berulang kali ke dalam percakapan.
Artikel ini lebih merupakan penyediaan cara penggunaan Claude Code yang lebih mendekati pemikiran insinyur, daripada sekadar membahas trik menghemat Token: perlakukan konteks sebagai aset, biarkan caching terus digunakan kembali, biarkan sesi panjang mengurangi perhitungan berulang.
Berikut adalah teks aslinya:
Saya menghemat 300 juta Token minggu ini, 91 juta dalam sehari, lebih dari 300 juta dalam seminggu.
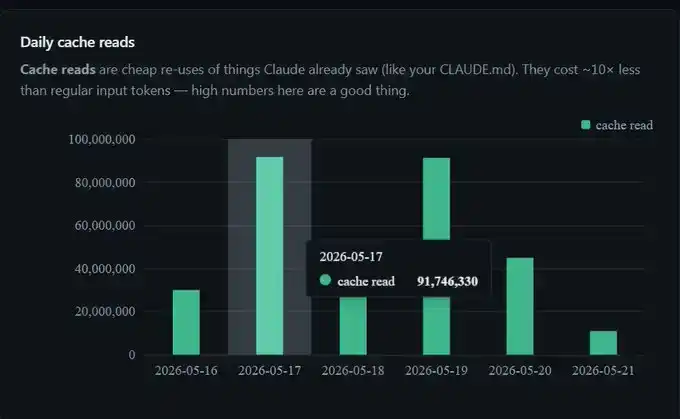
Saya tidak mengubah pengaturan apa pun. Ini hanyalah prompt caching yang bekerja normal di latar belakang.
Tapi setelah saya benar-benar memahami apa itu caching, dan bagaimana menghindari "mengganggu" caching, dengan kuota penggunaan yang sama, sesi saya dapat bertahan lebih lama. Jadi, berikut panduan 80/20 untuk pemula tentang prompt caching Claude Code, tanpa melibatkan detail mendalam di tingkat API.
TL;DR
Biaya Token caching hanya 10% dari biaya Token input biasa. 91 juta Token caching, biaya sebenarnya setara dengan sekitar 9 juta Token.
TTL caching versi langganan Claude Code adalah 1 jam; API default 5 menit; Sub-agent selalu 5 menit.
Caching dibagi menjadi tiga lapisan: lapisan sistem, lapisan proyek, lapisan percakapan.
Beralih model di tengah sesi akan merusak caching, termasuk mengaktifkan mode "opus plan".
Bagaimana sebenarnya caching dihitung biayanya?
Setiap Token yang di-cache, biayanya adalah 10% dari biaya Token input biasa.

Jadi, ketika dashboard saya menunjukkan suatu hari ada 91 juta Token yang mengenai cache, biaya sebenarnya hanya setara dengan memproses 9 juta Token. Ini juga sebabnya dibandingkan tanpa caching, saat menggunakan Claude Code dalam waktu lama, terasa sesi hampir "gratis" diperpanjang.
Ada dua angka di dashboard yang patut diperhatikan:
Cache create: Biaya satu kali yang muncul saat konten ditulis ke cache. Ini akan mulai bekerja pada putaran percakapan berikutnya.
Cache read: Token yang Claude gunakan kembali dari cache, seperti CLAUDE.md Anda, definisi alat, pesan sebelumnya, dll. Dibandingkan diproses ulang sebagai input, biayanya 10 kali lebih murah.

Jika angka Cache read Anda tinggi, artinya Anda efektif memanfaatkan caching; jika angka ini rendah, berarti Anda berulang kali membayar untuk konteks yang sama.
Thariq dari Anthropic punya kalimat yang membuat saya sangat ingat: "Kami sebenarnya memantau hit rate prompt cache, begitu hit rate terlalu rendah, alarm akan terpicu, bahkan insiden level SEV akan diumumkan."
Dia juga menulis artikel X yang bagus. Ketika hit rate cache tinggi, empat hal terjadi bersamaan: Claude Code terasa lebih cepat, biaya layanan Anthropic turun, kuota langganan Anda terasa lebih tahan lama, sesi coding panjang juga menjadi lebih realistis.
Tapi jika hit rate rendah, semua pihak dirugikan.

Jadi, insentif kedua belah pihak sebenarnya sejalan: Anthropic ingin hit rate caching Anda lebih tinggi, Anda sendiri juga ingin hit rate lebih tinggi. Yang benar-benar menghambat, hanyalah beberapa kebiasaan kecil yang tampak sepele, tetapi diam-diam me-reset cache.
Bagaimana caching tumbuh dalam setiap putaran percakapan?
Caching bergantung pada prefix matching, yaitu "pencocokan awalan".
Tidak perlu terjebak dalam detail teknis yang terlalu dalam, Anda hanya perlu memahami satu hal: selama konten sebelum suatu posisi benar-benar sama dengan konten yang telah di-cache, Claude dapat menggunakan kembali Token cache ini.
Sebuah sesi baru, kira-kira berjalan seperti ini:
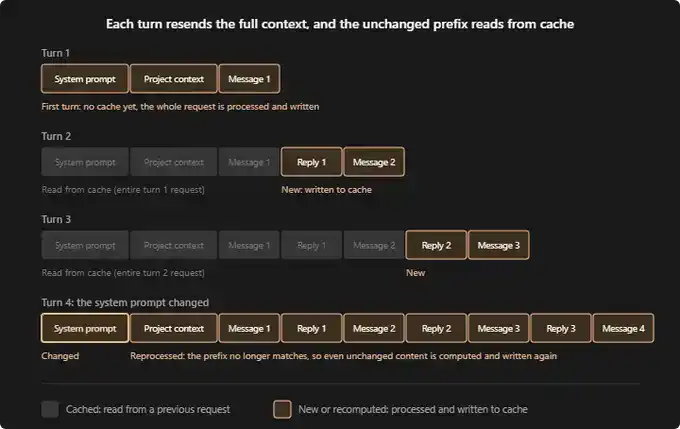
Berdasarkan dokumentasi Claude Code, sesi baru biasanya berjalan seperti ini:
Putaran percakapan pertama: Belum ada cache sama sekali. Prompt sistem, konteks proyek Anda (seperti CLAUDE.md, memory, aturan), serta pesan pertama Anda, semuanya akan diproses ulang, dan ditulis ke cache.
Putaran percakapan kedua: Semua konten dari putaran pertama sekarang sudah di-cache. Claude hanya perlu memproses balasan baru Anda dan pesan berikutnya. Biaya putaran ini jauh lebih rendah.
Putaran percakapan ketiga: Logikanya sama. Percakapan sebelumnya tetap disimpan di cache, hanya interaksi putaran terbaru yang perlu diproses ulang.
Caching sendiri bisa dibagi menjadi tiga lapisan:

Dari artikel X Thariq:
Lapisan sistem (System layer): Termasuk instruksi dasar, definisi alat (read, write, bash, grep, glob) dan gaya output. Lapisan ini di-cache secara global.
Lapisan proyek (Project layer): Termasuk CLAUDE.md, memory, aturan proyek. Lapisan ini di-cache per proyek.
Lapisan percakapan (Conversation): Termasuk balasan dan pesan, akan terus bertambah seiring setiap putaran percakapan.
Jika di tengah sesi, ada perubahan pada konten lapisan sistem atau lapisan proyek, semua konten harus di-cache ulang dari awal. Inilah operasi yang paling "mahal". Bayangkan: Anda sudah sampai pesan ke-16, tiba-tiba mengubah prompt sistem, atau berhenti satu jam di tengah jalan, maka semua Token dari pesan pertama harus diproses ulang.
Kebingungan 1 jam dan 5 menit
Ini adalah bagian yang paling mudah disalahpahami.
Versi langganan Claude Code: TTL default adalah 1 jam.
Claude API: TTL default adalah 5 menit. Anda bisa membayar biaya lebih tinggi untuk menaikkannya menjadi 1 jam.
Sub-agent di bawah semua rencana: Selalu 5 menit.
Obrolan web Claude.ai: Tidak ada catatan resmi yang jelas. Mungkin sama dengan versi langganan, tapi saya belum memastikannya.
Beberapa bulan lalu, banyak yang mengeluh kuota langganan Claude terlalu cepat habis. Saat itu ada yang mengira Anthropic diam-diam menurunkan TTL dari 1 jam menjadi 5 menit, tanpa memberi tahu pengguna. Tapi faktanya tidak, TTL Claude Code masih 1 jam.
Masalahnya, dokumentasi Claude Code dan API terpisah, dan keduanya memang hal yang sama sekali berbeda, sehingga menimbulkan banyak kebingungan.
Jika Anda menjalankan banyak alur kerja Sub-agent, atau langsung menggunakan API, maka angka 5 menit ini penting. Tapi bagi 95% pengguna Claude Code, yang benar-benar perlu diperhatikan, sebenarnya hanya jendela 1 jam itu.
Tiga kebiasaan yang mencakup 95% pengguna
Berikut ini adalah bagian yang menurut saya benar-benar berguna dalam penggunaan sehari-hari.
Jangan berhenti terlalu lama
Jika Anda sudah menganggur lebih dari satu jam, konten sebelumnya pada dasarnya sudah kedaluwarsa dari cache. Pesan Anda berikutnya akan membangun cache ulang. Dalam situasi seperti ini, daripada melanjutkan sesi lama yang sudah "dingin", lebih baik melakukan handoff yang jelas, lalu memulai sesi baru, biasanya biayanya lebih rendah.
Saat beralih tugas, langsung mulai ulang
/compact atau /clear memang akan merusak cache, jadi daripada pada titik ini benar-benar me-reset sekali.
Saya sendiri membuat session handoff skill, sebagai pengganti /compact. Ini akan merangkum apa yang telah kita selesaikan, keputusan apa yang masih tertunda, file mana yang paling penting, dan dari mana harus dilanjutkan. Kemudian saya jalankan /clear, tempelkan rangkuman ini, dan bisa melanjutkan seolah-olah tidak ada gangguan.
Perintah compact terkadang juga berjalan lambat. Handoff skill ini biasanya selesai dalam waktu kurang dari satu menit.
Di obrolan Claude, dokumen besar sebaiknya dimasukkan ke dalam Projects
Mekanisme caching di Claude.ai tidak dijelaskan sangat detail secara resmi, tapi jelas Projects menggunakan cara pengoptimalan yang berbeda dengan utas percakapan biasa. Jadi, jika Anda ingin menempelkan dokumen besar, sebaiknya masukkan ke Project, daripada langsung menjejalkannya ke percakapan.
Operasi apa yang diam-diam merusak cache?
Ada beberapa hal yang akan me-reset semua cache tanpa peringatan yang jelas.
Beralih model: Karena caching bergantung pada pencocokan awalan, dan setiap model memiliki cache sendiri. Begitu beralih model, permintaan berikutnya akan membaca riwayat lengkap tanpa ada hit cache.
Mode "Opus plan": Pengaturan ini akan menggunakan Opus di fase perencanaan, dan Sonnet di fase eksekusi. Saya sebelumnya merekomendasikannya di beberapa video optimisasi token, ada alasannya. Tapi perlu dipahami, setiap kali beralih plan, pada dasarnya adalah beralih model, artinya harus membangun cache ulang. Dalam jangka panjang, ini masih membantu memperpanjang kuota sesi, tapi Anda perlu tahu apa yang sebenarnya terjadi di baliknya.
Mengedit CLAUDE.md di tengah sesi diperbolehkan: Perubahan ini tidak langsung berlaku, harus menunggu restart berikutnya baru diterapkan. Jadi, cache yang sedang berjalan saat ini tidak akan terpengaruh.
Dashboard Token gratis saya
Tangkapan layar yang saya tunjukkan sebelumnya, berasal dari token dashboard.
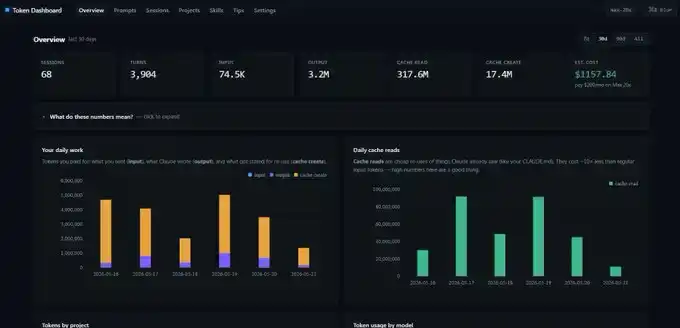
Ini adalah repositori GitHub yang sangat sederhana. Anda berikan tautannya ke Claude Code, minta ia menyelesaikan deployment di localhost lokal, maka ia akan membaca semua rekaman sesi Anda sebelumnya, bukan menghitung dari kondisi kosong. Anda langsung bisa melihat data input, output, cache create dan cache read harian.
Tapi ada satu hal yang perlu diperhatikan: Dashboard ini menghitung data Token di perangkat lokal. Jika Anda beralih dari desktop ke laptop, angkanya tidak akan persis sama. Setiap perangkat memiliki tampilan statistiknya sendiri.
Ringkasan
Prompt caching adalah hal yang bisa diteliti sangat dalam. Artikel Thariq itu membahasnya lebih lengkap dari sini, jika Anda ingin melihat gambaran penuh, layak dibaca.
Tapi Anda tidak perlu memahami semua detail untuk mendapat manfaat darinya. Anda hanya perlu menguasai 80/20 yang paling penting: Token caching 10 kali lebih murah daripada Token biasa; TTL Claude Code adalah 1 jam; beralih model akan merusak cache; melakukan handoff yang jelas di antara tugas, biasanya lebih hemat daripada menggunakan sesi lama yang sudah "kedaluwarsa" dan dipaksa dilanjutkan.






