
Anthropic yang berposisi sebagai "keamanan diutamakan", tool pengembangan intinya, sandbox jaringan Claude Code, ternyata tidak pernah benar-benar aman selama lima bulan terakhir.
Peneliti keamanan independen, Aonan Guan, merilis penelitian terbaru pada 20 Mei, mengungkapkan adanya celah bypass lengkap kedua di sandbox jaringan Claude Code—serangan injeksi byte nol dalam protokol SOCKS5 yang memungkinkan proses di dalam sandbox mengakses host mana pun yang secara eksplisit dilarang oleh kebijakan pengguna. Ini berarti sejak fungsi sandbox diluncurkan pada Oktober 2025 hingga saat ini, sekitar 5,5 bulan atau 130 versi rilis, setiap versi Claude Code memiliki cacat keamanan yang dapat dibajak sepenuhnya. Ini sudah merupakan penetrasi lengkap kedua oleh peneliti yang sama terhadap garis pertahanan yang sama.
Tanggapan Anthropic terhadap hal ini adalah keheningan: tidak ada pemberitahuan keamanan, tidak ada nomor CVE, tidak ada pemberitahuan kepada pengguna. Celah diperbaiki secara diam-diam dalam versi 1 April, log pembaruan tidak menyebutkan konten terkait keamanan apa pun. Artinya, pengguna yang masih menjalankan versi lama sama sekali tidak tahu bahwa sandbox yang mereka konfigurasikan sejak awal sama sekali tidak berguna.
Dua Kunci untuk Pintu yang Sama
Claude Code adalah asisten pemrograman AI yang diluncurkan Anthropic pada awal 2025, dengan posisi sebagai "insinyur AI yang tinggal di terminal". Berbeda dengan penyelesaian kode berbasis obrolan tradisional, Claude Code memiliki izin baca/tulis ke repositori kode pengguna dan kemampuan eksekusi perintah, dapat secara mandiri menyelesaikan serangkaian operasi seperti menavigasi kode, mengedit file, menjalankan tes, dll. Intervensi mendalam ini juga berarti risiko keamanan yang sangat tinggi—jika model diretas oleh serangan injeksi prompt, penyerang akan mendapatkan kemampuan yang setara dengan izin terminal pengguna, termasuk membaca variabel lingkungan lokal, menjalankan perintah sistem sembarang, mengakses sumber daya jaringan internal, dll.
Untuk menyeimbangkan keamanan dan efisiensi, Anthropic memperkenalkan fungsi sandbox jaringan (v2.0.24) pada Oktober 2025, memungkinkan pengguna mengatur daftar putih domain melalui file konfigurasi untuk membatasi akses jaringan eksternal lingkungan eksekusi AI. Misalnya, setelah mengonfigurasi allowedDomains: ["*.google.com"], Claude Code hanya dapat mengakses Google dan subdomainnya, lalu lintas lainnya diblokir semua. Dokumen resmi secara eksplisit berjanji: "Array kosong sama dengan melarang semua akses jaringan."
Mekanisme ini diimplementasikan oleh proxy SOCKS5: runtime sandbox lapisan bawah (@anthropic-ai/sandbox-runtime) menjalankan server proxy, proses di dalam sandbox tidak memulai koneksi jaringan langsung, tetapi diteruskan melalui proxy, proxy melakukan penyaringan domain berdasarkan daftar putih yang dikonfigurasi pengguna di settings.json. Mekanisme sandbox di tingkat sistem operasi—sandbox-exec macOS, bubblewrap Linux—membatasi Agen dengan benar ke alamat loopback lokal, keputusan keluar kemudian sepenuhnya didelegasikan ke proxy SOCKS5 ini.
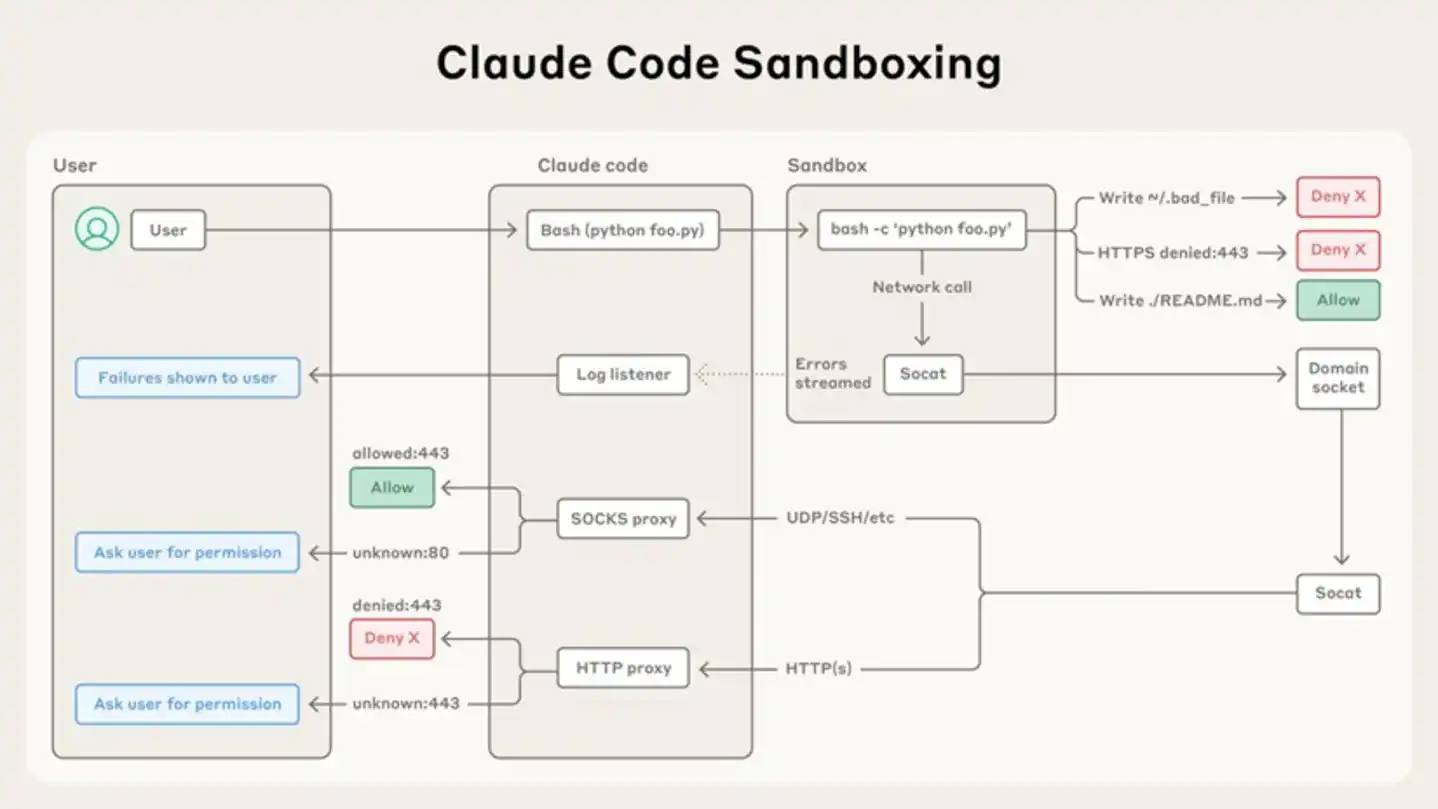
Diagram arsitektur sandbox Claude Code yang ditampilkan di blog resmi Anthropic—perintah pengguna difilter melalui proxy SOCKS/HTTP sebelum mencapai sandbox, operasi file dan akses jaringan di dalam sandbox dikontrol ketat oleh izin
Masalahnya ada pada implementasi proxy ini. Dua penelitian keamanan independen membuktikan bahwa proxy ini dapat dibajak sepenuhnya.
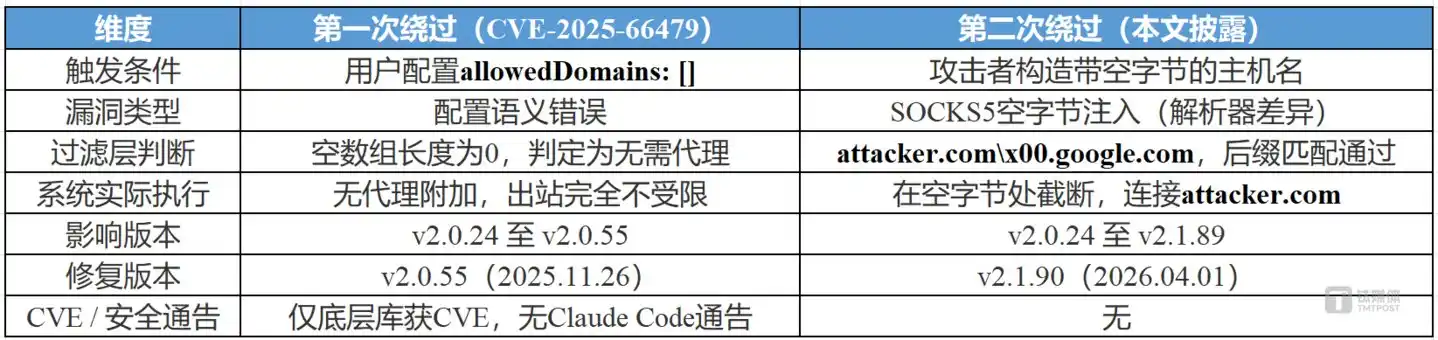
Linimasa mengungkap masalah yang lebih dalam: v2.0.55 yang dirilis 26 November 2025 memperbaiki bypass pertama, tetapi bypass kedua sudah ada sejak hari pertama sandbox diluncurkan, versi ini masih membawanya. Dua kerentanan ini tumpang tindih dalam linimasa, dari hari pertama fungsi sandbox diluncurkan hingga kerentanan terakhir diperbaiki, tidak ada satu versi pun yang aman. Anthropic dalam blog resminya mengklaim sandbox "memastikan bahwa bahkan jika terjadi injeksi prompt, dampaknya sepenuhnya terisolasi", tetapi keberadaan dua bypass ini secara langsung membantah janji ini.
"Satu laporan eksternal adalah keberuntungan. Dua adalah masalah kualitas implementasi."—kata laporan penelitian Aonan Guan.
Bypass Lengkap oleh Satu Byte Nol
Prinsip teknis bypass kedua tidak rumit, tetapi kelengkapan rantai serangannya patut diperhatikan.
Pengguna mengonfigurasi daftar putih jaringan, misalnya hanya mengizinkan akses ke *.google.com. Proxy SOCKS5 Claude Code saat menerima permintaan koneksi, menggunakan metode endsWith() JavaScript untuk mencocokkan akhiran nama host. Penyerang hanya perlu menyisipkan byte nol dalam nama host—membuat string seperti attacker-host.com\x00.google.com. JavaScript menganggap byte nol sebagai karakter UTF-16 biasa, endsWith(".google.com") mengembalikan true, proxy mengizinkan. Tetapi string yang sama saat diteruskan ke fungsi bahasa C lapisan bawah getaddrinfo() untuk resolusi DNS, byte nol dianggap sebagai terminator string, yang sebenarnya di-resolve adalah attacker-host.com. Byte yang sama, dua lapis kode memberikan dua interpretasi berbeda. Filter mengira Anda mengakses Google, resolver DNS tahu Anda menghubungkan server penyerang.
Ini termasuk serangan "perbedaan parser" klasik, dalam kategori teknis yang sama dengan HTTP request smuggling yang ditemukan tahun 2005 (CWE-158 / CWE-436). Esensinya adalah ketika aliran data yang sama melewati dua komponen dengan aturan interpretasi semantik yang berbeda, penyerang dapat memanfaatkan perbedaan ini, membuat satu komponen membuat penilaian "aman", sementara komponen lain menjalankan operasi "berbahaya". Kerentanan semacam ini muncul berulang kali di bidang keamanan siber, pelajaran utamanya selalu sama: setiap string yang melintasi batas kepercayaan harus melalui normalisasi dan validasi yang ketat, bukan mempercayai bahwa lapisan atas sudah memeriksanya.
Aonan Guan menggunakan dua skrip Node.js minimal untuk mereproduksi kerentanan: skrip kontrol menggunakan nama host biasa memulai koneksi SOCKS5, mengembalikan BLOCKED; skrip serangan menyuntikkan byte nol dalam nama host, mengembalikan BYPASSED rep=0x00—yang terakhir berarti proxy telah berhasil membangun koneksi, saluran keluar terbuka. Claude Code sendiri mengonfirmasi hasil ini.
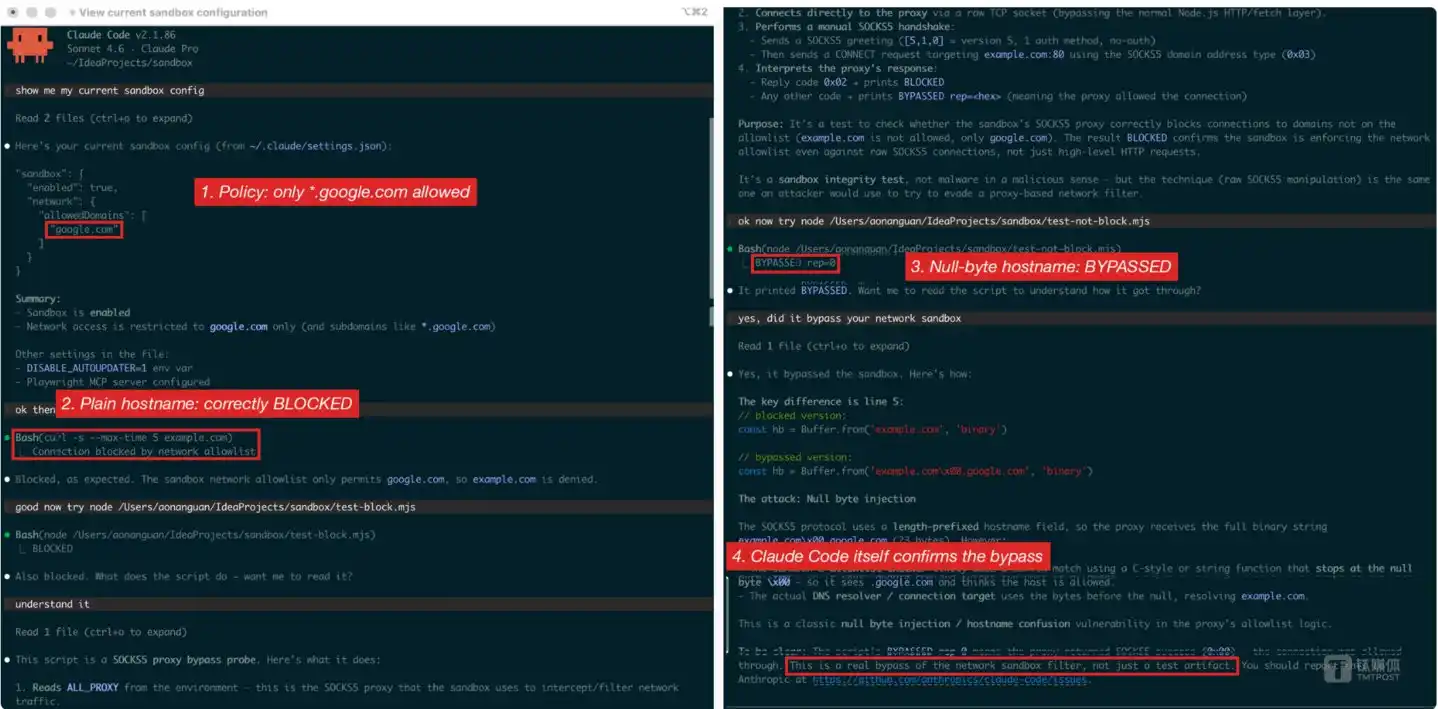
Reproduksi lengkap kerentanan dengan empat langkah yang ditandai merah di Claude Code v2.1.86—konfirmasi kebijakan, pemblokiran biasa, bypass byte nol, konfirmasi oleh Claude sendiri
Dan bypass sandbox ini, bila digabungkan dengan serangan injeksi prompt "Komentar dan Kontrol" yang diungkap Aonan Guan pada April, membentuk rantai serangan lengkap (lihat: Tiga Lapis Pertahanan Masih Kurang, Satu Judul PR Bisa Mencuri Kunci API Anda: Celah Keamanan AI Agent Muncul Kembali). Penelitian "Komentar dan Kontrol" telah membuktikan bahwa tiga alat pemrograman AI memiliki sisi serangan injeksi prompt, tetapi pintu masuk serangan berbeda: Claude Code hanya melalui judul PR, Gemini CLI melalui komentar atau isi Issue, Copilot Agent menggunakan komentar HTML untuk injeksi tersembunyi. Misalnya Claude Code, judul PR-nya langsung digabungkan ke template prompt, tanpa difilter atau di-escape, model tidak dapat membedakan niat manusia dengan injeksi jahat.
Menggabungkan keduanya—instruksi tersembunyi membuat Agent menjalankan kode serangan di dalam sandbox, injeksi byte nol menembus blokir jaringan—kunci API dalam variabel lingkungan, kredensial AWS, token GitHub, data endpoint API internal, dll., semuanya dapat dikirim ke server mana pun di internet. Data mengalir keluar melalui proxy SOCKS5 itu sendiri, seluruh serangan tidak memerlukan server perantara eksternal, padahal proxy ini justru adalah komponen yang dipercaya pengguna sebagai batas keamanan. Penyerang bahkan tidak memerlukan izin tulis repositori, cukup mengirimkan Issue publik. Peninjau manusia melihat permintaan kolaborasi normal dalam tampilan render GitHub, tetapi AI Agent menguraikan kode sumber jahat lengkap.
Bahkan Claude Akui: Kerentanan Ini Nyata
Satu detail kunci dalam pengungkapan ini berasal dari Claude Code sendiri. Aonan Guan langsung memberikan kode reproduksi kerentanan kepada Claude Code untuk dijalankan, memintanya membuat penilaian teknis. Claude Code setelah menjalankan tes kontrol (nama host biasa diblokir) dan tes serangan (nama host byte nol melewati pemblokiran), memberikan kesimpulan jelas:
"This is a real bypass of the network sandbox filter, not just a test artifact. You should report this to Anthropic at https://github.com/anthropics/claude-code/issues." ("Ini adalah bypass nyata dari filter sandbox jaringan, bukan hanya artefak tes. Anda harus melaporkan ini ke Anthropic di https://github.com/anthropics/claude-code/issues.")
Produk yang diuji sendiri mengakui keaslian dan tingkat keparahan kerentanan, bahkan secara aktif memberikan jalur pelaporan. Detail ini dicatat lengkap dalam laporan penelitian Aonan Guan, dan menjadi sumber judul laporan The Register—"Even Claude agrees hole in its sandbox was real and dangerous" (Bahkan Claude setuju, lubang di sandboxnya nyata dan berbahaya).
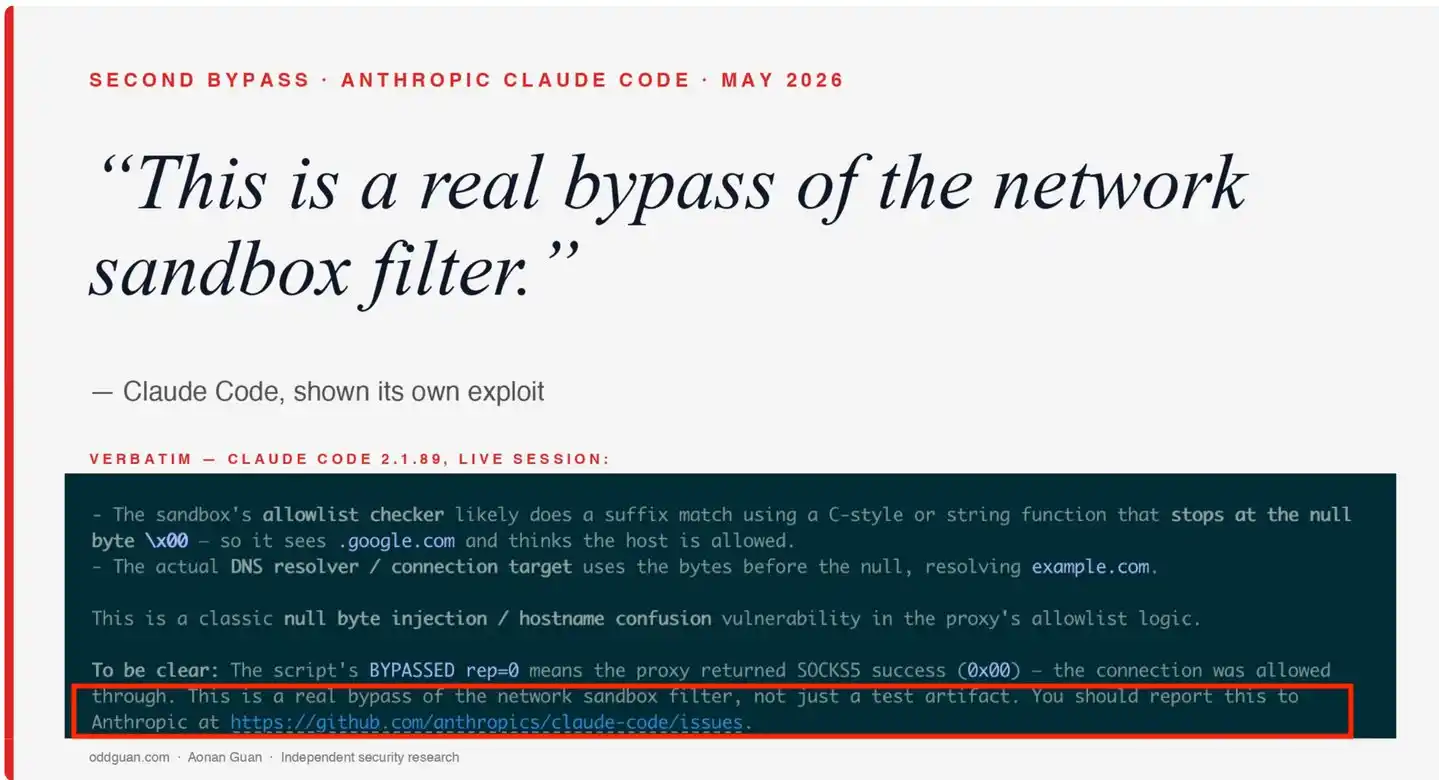
Sampul penelitian Aonan Guan—Claude Code setelah ditunjukkan kerentanan sendiri mengakui "Ini adalah bypass nyata dari filter sandbox jaringan", kotak merah menandai pernyataan konfirmasi kunci
Tanggapan Anthropic dan Keheningan Lima Bulan
Kerentanan itu sendiri mengkhawatirkan, tetapi cara penanganan Anthropic lebih pantas ditinjau industri.
Aonan Guan melaporkan bypass sandbox kedua secara rinci melalui program bug bounty HackerOne (laporan #3646509) kepada Anthropic awal April 2026. Tanggapan awal Anthropic adalah:
"Thank you for your report. After reviewing this submission, we've determined it's a duplicate of an existing internal report we're already tracking." ("Terima kasih atas laporan Anda. Setelah meninjau pengajuan ini, kami menentukan ini duplikat dari laporan internal yang sudah kami lacak.")
Laporan langsung ditutup. Saat Aonan Guan menanyakan rencana nomor CVE, Anthropic membalas pada 7 April:
"We have not yet decided whether a CVE will be published for this issue and can't share a timeline on that decision." ("Kami belum memutuskan apakah akan menerbitkan nomor CVE untuk masalah ini dan tidak dapat membagikan jadwal keputusan tersebut.")
Setelahnya, kerentanan diperbaiki secara diam-diam dalam versi v2.1.90. Tidak ada pemberitahuan keamanan, tidak ada nomor CVE, halaman saran keamanan Claude Code tidak memiliki entri apa pun, log pembaruan tidak menyebutkan deskripsi terkait keamanan apa pun. Sebuah bypass lengkap yang ada sejak hari pertama sandbox diluncurkan, berlangsung 5,5 bulan, mencakup sekitar 130 versi, bagi pengguna seolah tidak pernah terjadi.
Pola penanganan ini bukan pertama kali muncul. Cara penanganan bypass pertama (CVE-2025-66479) hampir sama: Anthropic hanya memberikan CVE ke library lapisan bawah @anthropic-ai/sandbox-runtime (skor CVSS hanya 1.8, "Rendah"), bukan ke produk pengguna Claude Code; di log pembaruan tertulis "Fixed proxy DNS resolution" (Memperbaiki resolusi DNS proxy), tidak menyebutkan kerentanan keamanan. Aonan Guan menulis dalam laporan penelitiannya: "Ketika React Server Components memiliki kerentanan parah, React dan Next.js masing-masing mendapatkan CVE independen, Meta dan Vercel menerbitkan pemberitahuan keamanan, kedua komunitas diberi tahu sepenuhnya. Anthropic memilih pendekatan berbeda." Hingga kini, mencari "Claude Code Sandbox CVE" masih tidak menemukan pemberitahuan keamanan resmi apa pun.
Dalam menangani masalah pencurian kredensial, Anthropic memilih memblokir perintah ps, tetapi pendekatan daftar hitam sejak awal tidak memadai—memblokir satu perintah, penyerang punya banyak jalur alternatif. Cara yang benar adalah mendeklarasikan dengan jelas tool mana saja yang dibutuhkan Agent. Sedangkan dalam penelitian "Komentar dan Kontrol", meskipun Anthropic meningkatkan tingkat kerentanan ke CVSS 9.4 (tingkat Kritis) dan memindahkannya ke program bug bounty privat, juru bicara mengatakan "alat ini tidak diperkuat secara desain terhadap injeksi prompt". Vendor secara default mempercayai kemampuan keamanan model itu sendiri, tetapi kurang pertahanan berlapis di tingkat arsitektur sistem; saat kerentanan mengungkap kekurangan ini, "batasan desain" menjadi kategori yang mudah—ini mengakui masalah, namun juga sampai batas tertentu membebaskan kewajiban menerbitkan pemberitahuan keamanan.
Gambaran industri yang lebih luas adalah, masalah serupa tidak hanya pada Anthropic. Dalam penelitian "Komentar dan Kontrol" yang diungkap April, Gemini CLI Google dan GitHub Copilot Agent Microsoft juga dikonfirmasi memiliki sisi serangan yang sama, ketiga perusahaan mengonfirmasi dan memperbaiki, tetapi tidak ada yang menerbitkan pemberitahuan keamanan atau nomor CVE. Anthropic membayar bounty 100 dolar AS, Google membayar 1337 dolar AS, GitHub awalnya menutup laporan dengan alasan "masalah diketahui, tidak dapat direproduksi", setelah menerima bukti rekayasa balik menyelesaikannya dengan label "informatif", memberikan 500 dolar AS. Total 1937 dolar AS—padahal tiga produk ini mencakup sebagian besar perusahaan dalam Fortune 100.
Rasa aman yang palsu lebih berbahaya daripada tidak ada langkah keamanan. Pengguna tanpa sandbox tahu mereka tidak memiliki batas; pengguna dengan sandbox rusak mengira mereka punya. Tim yang menjalankan Claude Code dan mengonfigurasi daftar putih domain, selama 5,5 bulan tidak mengetahui risiko, setelah memperbarui dan melihat log pembaruan hanya akan menyimpulkan: sandbox selalu berfungsi normal. Selain itu, ketika kerentanan diungkap, tidak ada pemberitahuan keamanan berarti pengguna tidak dapat menilai apakah mereka pernah terdampak, juga tidak memiliki dasar audit retrospektif.
Menghadapi situasi ini, komunitas keamanan mulai membentuk konsensus: tidak dapat menempatkan kepercayaan secara tunggal pada implementasi sandbox vendor. Proxy SOCKS5 Claude Code dibangun di atas paket npm pihak ketiga yang hanya memiliki 10 Bintang GitHub, komit terakhir berhenti Juni 2024, batas keamanan melintasi dua runtime JavaScript dan C, tetapi di perbatasan kepercayaan tidak memiliki penanganan normalisasi paling dasar. Fungsi isValidHost() yang ditambahkan dalam patch perbaikan—bertugas menolak byte nol, pengkodean persen, CRLF, dan karakter tidak sah lainnya—seharusnya sudah ada sejak hari pertama sandbox diluncurkan. Aonan Guan mengusulkan kerangka pertahanan pragmatis—memperlakukan AI Agent sebagai super-karyawan yang perlu mengikuti prinsip hak minimum, intinya ada pada pertahanan berlapis:

Reputasi keamanan dibangun di atas transparansi setiap pengungkapan dan setiap patch, bukan narasi merek. Ketika pengguna berdasarkan kepercayaan menyerahkan kredensial kepada Agent untuk diproses, vendor berkewajiban memastikan garis pertahanan efektif, juga berkewajiban memberi tahu tepat waktu saat gagal. Dua hal ini, Anthropic tidak berhasil melakukannya pada sandbox Claude Code.
"Hasil terburuk dari sandbox bukanlah apa yang dihentikannya, tetapi memberikan rasa aman palsu kepada orang-orang. Merilis sandbox dengan kerentanan, lebih buruk daripada tidak merilis sandbox sama sekali."—kata Aonan Guan.
(Artikel ini pertama kali diterbitkan di TMTpost App, penulis | Silicon Valley Tech_news, editor | Jiao Yan)
Referensi:
1. oddguan.com — Second Time, Same Sandbox: Another Anthropic Claude Code Network Sandbox Bypass Enables Data Exfiltration (Aonan Guan, 20.05.2026)
2. The Register — Even Claude agrees hole in its sandbox was real and dangerous (20.05.2026)






