Note de la rédaction : Ce rapport, basé sur environ 400 000 sessions Claude Code, examine comment les outils d'IA de programmation transforment la relation entre l'humain et le code.
La découverte principale est la suivante : dans la programmation par agents intelligents, l'humain décide principalement du « quoi faire », tandis que Claude s'occupe principalement du « comment le faire ». L'utilisateur assume la plupart des décisions de planification, tandis que Claude assume la majeure partie du travail d'exécution. En d'autres termes, l'IA prend en charge les étapes de mise en œuvre comme l'écriture de code, la modification de fichiers, l'exécution de commandes et le débogage, mais la définition des objectifs et l'évaluation des résultats reposent toujours sur l'humain.
Plus important encore, l'efficacité de l'utilisation de Claude Code ne dépend pas uniquement du fait que l'utilisateur soit programmeur ou non. Le rapport montre que dans les tâches générant du code, les taux de réussite des utilisateurs exerçant des métiers non techniques comme le droit, la finance, la gestion ou la recherche se rapprochent de ceux des ingénieurs logiciels. Ce qui influence vraiment le résultat, c'est la compréhension que l'utilisateur a du problème qu'il veut résoudre.
Cela signifie que la programmation par IA réduit le seuil de mise en œuvre, pas celui du jugement. À l'avenir, les personnes qui comprennent le métier, le contexte, qui peuvent formuler clairement les besoins et évaluer les résultats, pourraient mieux utiliser l'IA que celles qui savent simplement coder. L'IA ne remplacera pas automatiquement l'expertise métier, elle en amplifiera au contraire la valeur.
Voici l'article original :
Principales découvertes
En nous appuyant sur des recherches existantes, nous proposons un cadre pour étudier la programmation interactive par agents intelligents. Ce cadre, basé sur l'analyse respectueuse de la vie privée d'environ 400 000 sessions Claude Code entre octobre 2025 et avril 2026, évalue la composition des tâches, la façon dont l'humain et l'IA collaborent, ainsi que le taux de réussite des tâches.
Dans une session typique, l'humain est responsable de la majorité des décisions de planification, c'est-à-dire de décider « quoi faire » ; Claude est responsable de la majorité des décisions d'exécution, c'est-à-dire de décider « comment le terminer ». Plus l'expertise de l'utilisateur dans un domaine est grande, plus la quantité de travail que Claude accomplit par instruction est importante. Dans les tâches de codage, les taux de réussite moyens des principaux groupes professionnels – c'est-à-dire si l'utilisateur a accompli ce qu'il voulait faire initialement, avec des preuves vérifiables comme des tests réussis, des soumissions de code, etc. – sont presque au même niveau que celui des ingénieurs logiciels.
Plus les compétences professionnelles de l'utilisateur dans le domaine sont élevées, plus la session a de chances de se terminer avec succès. Cependant, l'écart entre les utilisateurs intermédiaires et les experts n'est pas très grand. Au cours des sept mois observés, la proportion de sessions consacrées au débogage a presque diminué de moitié, et l'utilisation a évolué vers des usages plus complets de l'agent : déploiement et exécution de code, analyse de données et rédaction de documents non liés au code.
Au cours de ces sept mois, la valeur typique des tâches a augmenté dans presque tous les types de travail. En comparant avec les offres d'emploi indépendant pour estimer la valeur des tâches, nous constatons une augmentation moyenne d'environ 25%.
Introduction
La programmation par agents intelligents est en plein essor. Depuis fin 2025, la proportion de projets GitHub présentant une activité d'agent de codage a plus que doublé, et les utilisateurs de Claude Code utilisent désormais cet outil en moyenne 20 heures par semaine. Les personnes sans expérience formelle en programmation peuvent-elles réussir à diriger un agent intelligent pour accomplir des travaux techniques complexes ? Comment l'adoption rapide et l'amélioration des capacités de ces outils affecteront-elles le travail intellectuel au sens large ? Nous n'avons pas encore de réponse complète, mais les données d'utilisation de Claude Code révèlent déjà quelques signes précoces.
Ce rapport, basé sur l'analyse respectueuse de la vie privée d'environ 400 000 sessions interactives impliquant environ 235 000 utilisateurs entre octobre 2025 et avril 2026, fournit des preuves sur la façon dont Claude Code est réellement utilisé. Il s'inscrit dans la continuité de nos recherches précédentes sur les indicateurs d'autonomie dans les sessions Claude Code et sur la manière dont Claude Code change le travail interne chez Anthropic. Cet article propose un cadre pour décrire l'utilisation d'un assistant de programmation IA interactif : quel travail les gens accomplissent, qui l'accomplit, et si le travail est réussi. Nous nous concentrons sur les utilisations de Claude Code via l'interface en ligne de commande (CLI), Claude.ai ou l'application de bureau Claude Code. En suivant l'évolution des usages de la programmation par agents intelligents avec l'amélioration des capacités des modèles, nous pouvons mieux comprendre l'impact de ces outils sur les professionnels de la programmation et sur le marché du travail des travailleurs du savoir.
Ce qui se passe avec Claude Code pourrait préfigurer l'avenir du travail intellectuel : les agents intelligents s'intégreront progressivement dans des travaux non liés au codage. Nous constatons que Claude s'occupe de tâches plus complexes et de plus grande valeur. Parallèlement, une division claire du travail persiste dans la programmation par agents : l'humain décide quoi construire, l'agent décide comment le construire.
Nous voyons également des preuves que ce qui amplifie vraiment l'efficacité de l'outil est l'expertise métier, et non la maîtrise de la programmation. En particulier, les experts du domaine réussissent plus facilement et se remettent plus facilement des erreurs et des malentendus. Cependant, l'écart entre les experts et les utilisateurs intermédiaires n'est pas très marqué. Cela suggère qu'une maîtrise suffisante dans un domaine permet d'utiliser ces outils presque aussi efficacement qu'un expert confirmé.
Ces découvertes nous permettent d'observer les transformations potentielles du marché du travail. Dans nos données, le succès dépend de la compréhension du problème à résoudre par l'utilisateur, et non de sa formation en programmation. Si ces modèles se vérifient à l'échelle de l'économie, cela signifierait que les outils de programmation par agents intelligents, tout en absorbant une partie des travaux de mise en œuvre, récompensent également ceux qui comprennent véritablement les problèmes qu'ils cherchent à résoudre dans leur travail. Les agents de codage ne remplacent pas l'expertise métier. Au contraire, plus un travailleur apporte de compréhension à l'agent, plus l'agent peut accomplir un travail de haute qualité.
Division du travail
Que font les gens avec Claude Code
Pour comprendre comment les gens utilisent Claude Code, nous classons chaque session dans l'un des neuf modes de travail, c'est-à-dire l'activité unique qui décrit le mieux l'objectif de la session. Quatre de ces modes impliquent directement l'écriture ou la maintenance de code : construire quelque chose de nouveau, réparer quelque chose de cassé, tester du code, et orchestrer d'autres agents ou des pipelines d'automatisation. Une autre catégorie concerne l'exploitation de logiciels, incluant le déploiement, la configuration, l'exécution de pipelines et la surveillance de systèmes. Deux autres catégories visent davantage à comprendre « quoi faire » : comprendre le fonctionnement d'un système existant, et planifier des modifications avant de les mettre en œuvre. Enfin, deux dernières catégories sont indépendantes du code, ou le code n'est qu'un élément auxiliaire du produit final : analyser des données, et communiquer via des présentations et d'autres documents textuels.
Environ 56% des sessions consistent à écrire du code (25%), à réparer du code (26%), ou à tester et orchestrer du code (5%). L'exploitation de logiciels représente 17%, la planification ou l'exploration 14%, et l'analyse ou la rédaction de texte 13% (voir Figure 1).
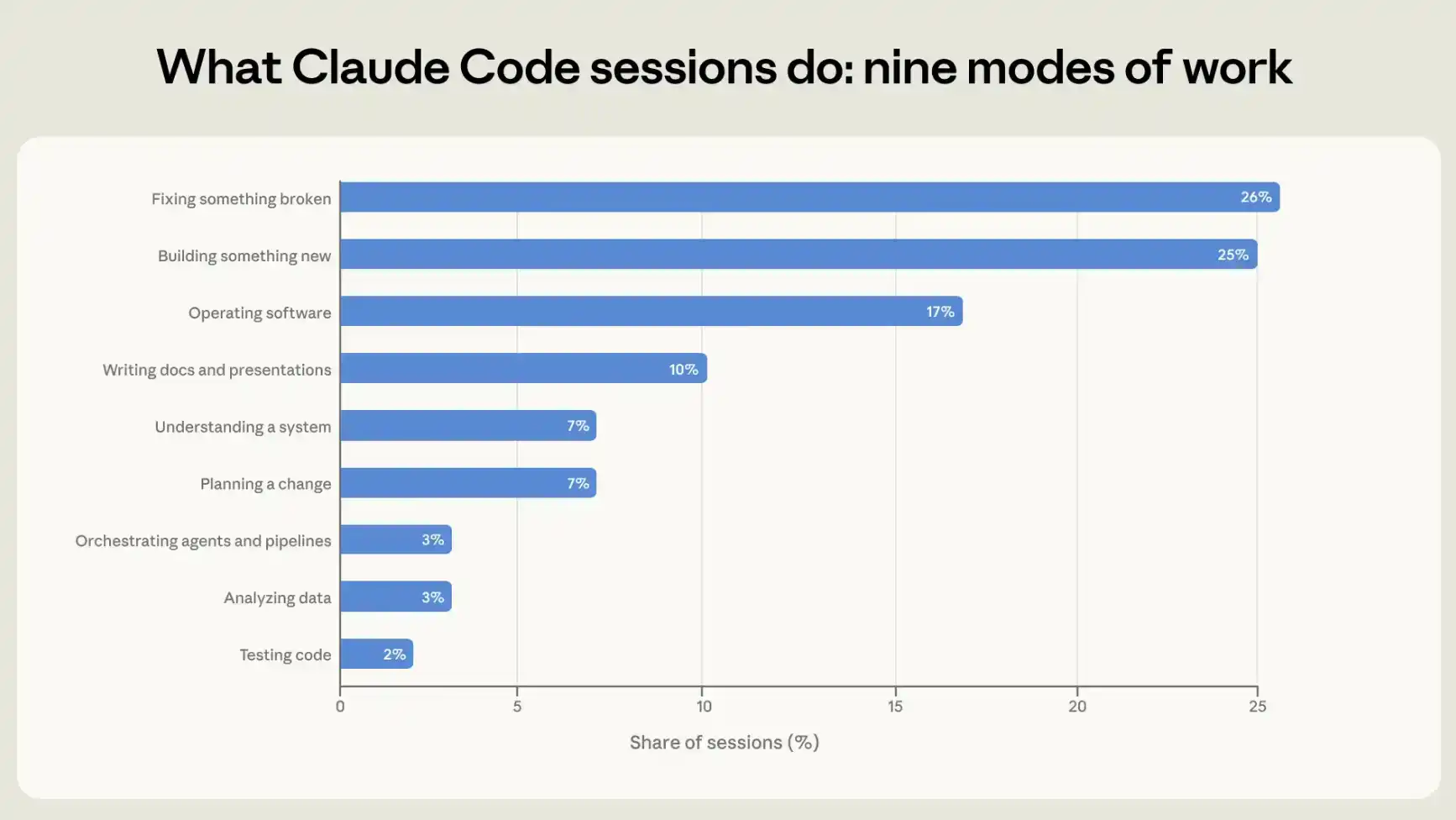
Nous avons d'abord fait lire les transcriptions des sessions au modèle pour les classer ; ensuite, nous avons utilisé nos outils d'analyse respectueux de la vie privée pour recouper ces classifications avec les données de télémétrie automatiquement enregistrées pour chaque session, y compris l'ajout ou la suppression de lignes de code. Il existe une forte cohérence entre les deux sources. Par exemple, dans les sessions classées comme création ou modification de code par notre classifieur, plus de 90% montrent également des changements de code dans les données de télémétrie. Pour plus de détails, voir l'annexe.
Qui prend les décisions
À quel point Claude Code est-il autonome ? Les évaluations de capacités montrent que sa limite supérieure est déjà élevée et continue d'augmenter. Par exemple, dans des benchmarks comme l'évaluation d'intervalle temporel de METR, les modèles de pointe sont désormais capables d'accomplir de manière autonome des tâches logicielles qui nécessitaient auparavant des heures de travail humain, en surmontant elles-mêmes les obstacles. Mais dans l'usage réel, comment cela se présente-t-il ? Ici, nous nous intéressons à la part de pilotage assumée par l'humain et par Claude dans des sessions réelles.
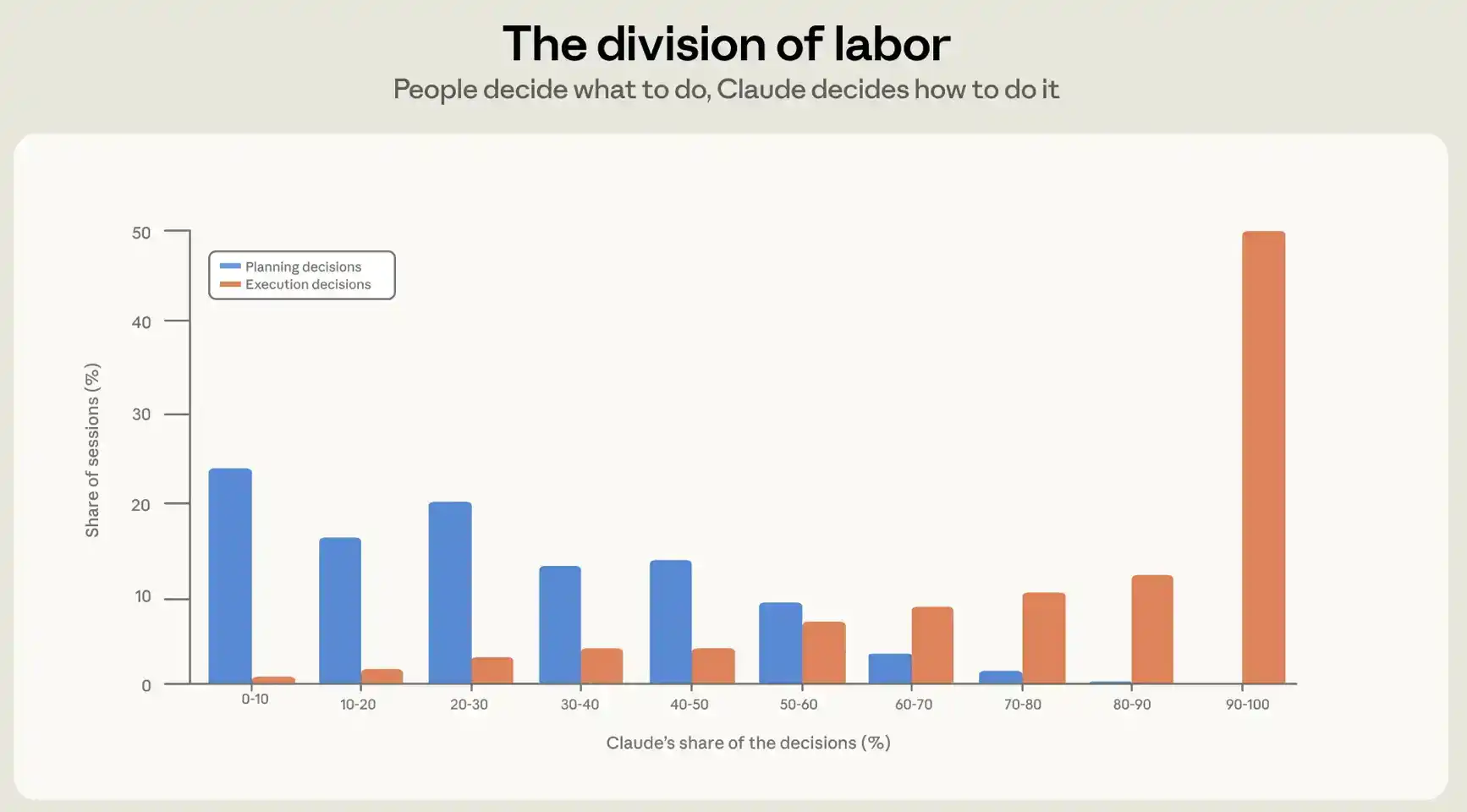
Nous étudions cette question sous deux angles. Premièrement, nous examinons dans quelle mesure les gens délèguent les décisions à Claude ; deuxièmement, nous observons combien d'actions ils assignent à Claude. Pour comprendre la répartition des décisions dans une session, nous avons construit un classifieur d'attribution de décisions respectueux de la vie privée basé sur le contenu des sessions. Nous demandons au classifieur de lister toutes les décisions significatives de la session et de les classer en décisions de planification et en décisions d'exécution. Les décisions de planification incluent quoi faire, quelle méthode adopter, ce qui constitue une fin ; les décisions d'exécution incluent quels fichiers modifier, quel code écrire, dans quel langage, et quelles commandes exécuter. Ensuite, le classifieur attribue chaque décision à Claude ou à l'utilisateur, et génère deux chiffres pour chaque session : le pourcentage de décisions de planification assumées par l'utilisateur, et le pourcentage de décisions d'exécution assumées par l'utilisateur.
En moyenne, les humains prennent environ 70% des décisions de planification, mais seulement 20% des décisions d'exécution (voir Figure 2). Dans l'usage réel, la programmation par agents établit une division claire du travail : l'humain décide quoi construire, l'agent décide comment le construire.
Pour comprendre le degré de délégation des actions dans une session, nous examinons non pas le contenu, mais la structure de la session. Les sessions Claude Code consistent en des aller-retour entre Claude et l'utilisateur : l'utilisateur envoie un prompt, Claude exécute des actions ; puis l'utilisateur envoie un nouveau prompt, et ainsi de suite. Dans une session typique, il y a environ quatre de ces tours. Dans nos données historiques d'octobre à avril, chaque prompt envoyé par l'utilisateur déclenche en moyenne environ 10 actions de la part de Claude, parfois plus de 100. À chaque tour, Claude lit des fichiers, modifie du code, exécute des commandes, et produit en moyenne 2400 mots.
La quantité de travail accomplie par Claude entre deux vérifications de l'utilisateur dépend largement de qui prend les décisions. Lorsque l'utilisateur conserve le contrôle du processus d'exécution, c'est-à-dire lorsqu'il prend plus de 80% des décisions d'exécution, Claude exécute moins d'actions par tour, environ 8. Lorsque Claude contrôle la planification, c'est-à-dire lorsqu'il prend plus de 80% des décisions de planification, il assume le plus grand nombre d'actions, environ 16.
Niveau de compétence
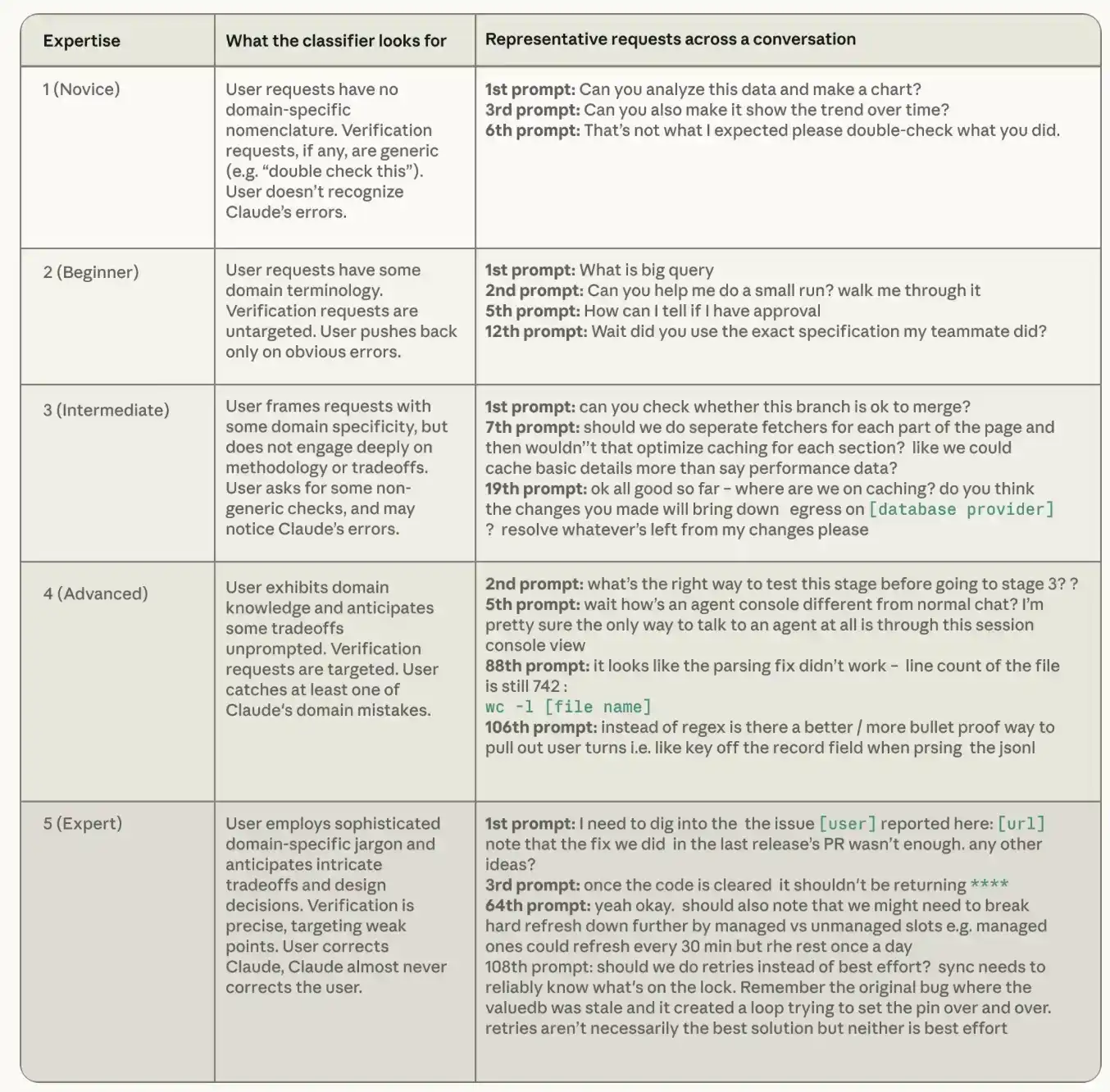
Pour chaque transcription de session, Claude évalue le niveau de compétence apparent de l'utilisateur sur cette tâche sur une échelle à cinq niveaux, de novice à expert. Le classifieur de niveau de compétence se concentre sur trois signaux : la précision des instructions données par l'utilisateur, ce que l'utilisateur demande à Claude de vérifier, et si c'est plus souvent l'utilisateur qui corrige Claude ou l'inverse. Il est important de noter que cette compétence est distincte du poste ou des capacités générales, et surtout, elle est spécifique à la tâche. Un ingénieur expérimenté qui pose une question sur Rust pour la première fois peut être un débutant sur une tâche Rust. Un comptable n'ayant jamais utilisé Python, mais capable de dire précisément à Claude quelles règles de rapprochement un script Python doit exécuter et d'identifier les cas limites que le script traiterait incorrectement à la fin du mois, est un expert sur cette tâche.
Le tableau ci-dessous montre comment nous définissons chaque niveau de compétence dans le classifieur, avec des exemples de demandes tirés de l'ensemble de données publiques de conversations d'agents de codage SWE-chat. Les conversations classées comme « novice » donnent des instructions générales, sans montrer de connaissances spécifiques au domaine ; celles classées comme « expert » transmettent une compréhension approfondie de la base de code et de l'environnement technique.
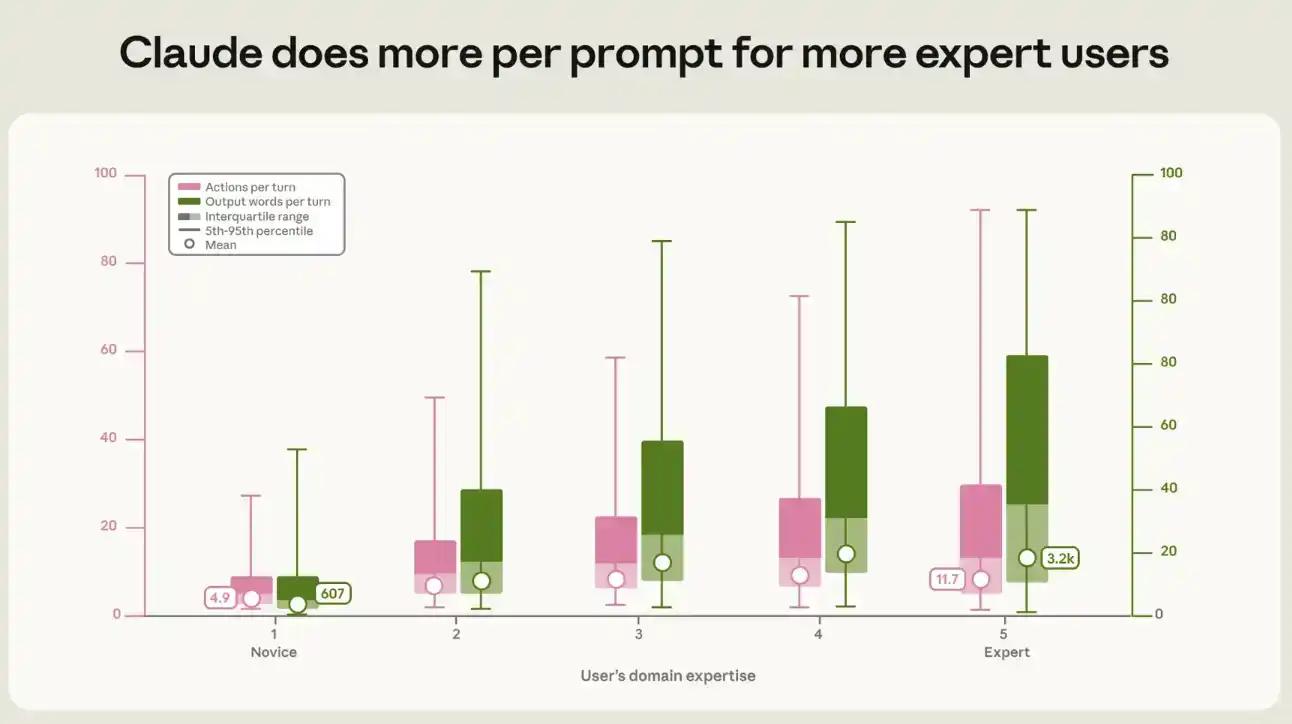
Nous avons quantifié la relation entre le niveau de compétence et le volume de sorties et d'activités générées par chaque prompt de Claude. Dans une session typique de novice, chaque prompt déclenche environ 5 actions et produit environ 600 mots de la part de Claude ; dans une session d'expert, la chaîne d'actions est plus de deux fois plus longue, environ 12 actions, et le volume de sortie atteint environ 3200 mots, soit cinq fois plus (voir Figure 3). Cet écart entre novice et expert se retrouve dans tous les types de travail et toutes les tranches de valeur de tâche.
Ces indicateurs complètent nos recherches précédentes sur l'autonomie de Claude Code. Ces dernières suivaient la durée d'exécution de l'agent et la fréquence à laquelle les utilisateurs approuvaient automatiquement ses actions. En revanche, nos indicateurs d'attribution de décisions capturent qui prend les décisions substantielles sur l'ensemble de la session, tandis que le volume de sorties et le nombre d'actions par prompt mesurent le degré d'activité autonome que chaque instruction humaine peut susciter de la part de Claude.
Qui utilise Claude Code, et pour quoi faire
Utilisateurs
Pour comprendre qui accomplit ce travail, nous déduisons la profession de chaque utilisateur à partir des transcriptions de session et la faisons correspondre à l'une des 23 catégories principales du système de classification des professions (SOC) du Bureau américain des statistiques du travail. Le classifieur est invité à se baser uniquement sur les signaux suivants : le contexte du projet chargé par l'agent au début de la session, les noms et structure des fichiers, les documents ou artefacts cités par l'utilisateur (par exemple, documents juridiques, données cliniques, rapports financiers, supports de cours), et le vocabulaire utilisé par l'utilisateur. Il est explicitement demandé au classifieur de ne pas considérer le fait « d'écrire du code » comme une preuve en soi que l'utilisateur exerce une profession de programmation. Ce n'est que lorsqu'il existe un signal clair indiquant que le travail logiciel ou de données fait partie de la profession de l'utilisateur que la session est classée dans la catégorie SOC liée au codage, à savoir « Professions informatiques et mathématiques ». Si un avocat construit un script pour vérifier automatiquement l'absence de certaines clauses dans un ensemble de contrats, même si la session consiste principalement à écrire un logiciel, elle sera classée dans les professions juridiques. S'il n'y a aucun signal concernant la profession de l'utilisateur, la session n'est pas classée.
Nous avons pu déduire la profession pour environ 70% des sessions. Parmi ces sessions classables, les « Professions informatiques et mathématiques » constituent le groupe le plus important, ce qui n'est pas surprenant car cette catégorie couvre la plupart des travaux liés aux logiciels. Viennent ensuite les opérations commerciales et financières, les arts, le design et les médias, la gestion, ainsi que les sciences de la vie, physiques et sociales. Dans notre échantillon, les groupes professionnels non logiciels à la croissance la plus rapide sont la gestion, les ventes et les professions juridiques.
Travail accompli
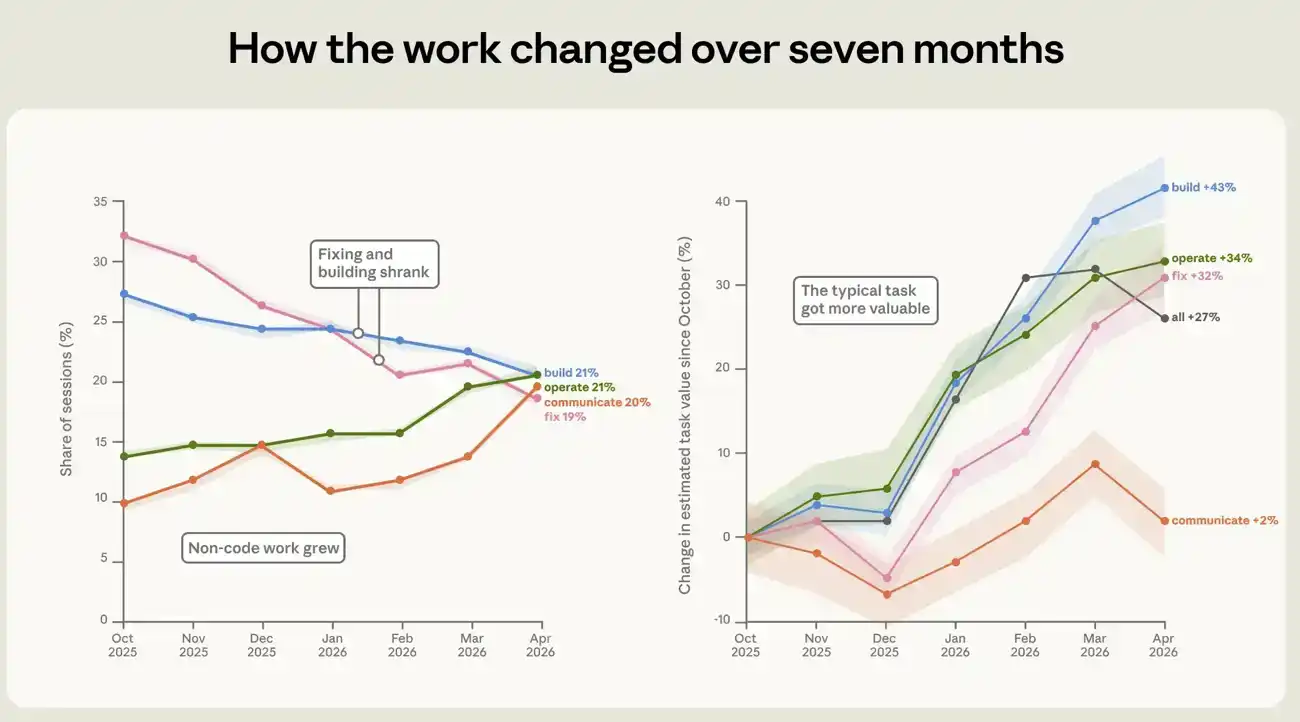
D'octobre 2025 à avril 2026, la composition du travail accompli avec Claude Code a considérablement changé. Le changement le plus marquant est la baisse de la proportion de sessions consacrées à la réparation de code cassé, passant de 33% à 19% (voir Figure 4). Elles ont été remplacées par davantage de travaux autour du code. La proportion d'exploitation de logiciels est passée de 14% à 21%. L'écriture et l'analyse de données ont environ doublé, passant d'environ 10% à environ 20%.
La valeur des tâches elles-mêmes a également augmenté. Nous estimons approximativement la valeur économique de chaque session en évaluant le coût d'un travail similaire sur le marché du travail indépendant, en nous calibrant sur un ensemble de données d'offres d'emploi publiques réelles. Selon cette mesure, la valeur estimée moyenne d'une session a augmenté de 27% entre octobre et avril. Cette hausse est observée dans de nombreux types de travail. Les valeurs des tâches de construction, d'exploitation et de réparation ont augmenté d'environ 43%, 34% et 32% respectivement. Ces estimations de prix sont assez approximatives, nous les utilisons donc principalement pour comparer les tendances des différentes tâches au fil du temps, et non comme des valeurs en dollars directement interprétables. Pour plus de détails sur la construction de l'estimateur de valeur des tâches, voir l'annexe.
Le succès dépend de ce que l'utilisateur apporte
Estimer la valeur des tâches est une façon de comprendre comment Claude Code aide les gens à accomplir leur travail. Un autre angle est d'observer combien de sessions réussissent, et quelles caractéristiques des sessions sont corrélées au succès. Pour tous les indicateurs de succès, nous observons un schéma clair : plus le niveau de compétence manifesté par l'utilisateur dans la session est élevé, plus la session a de chances de réussir. La majeure partie de l'amélioration se concentre sur les niveaux de compétence inférieurs, c'est-à-dire que l'écart entre un novice et un utilisateur intermédiaire est plus grand qu'entre un utilisateur intermédiaire et un expert.
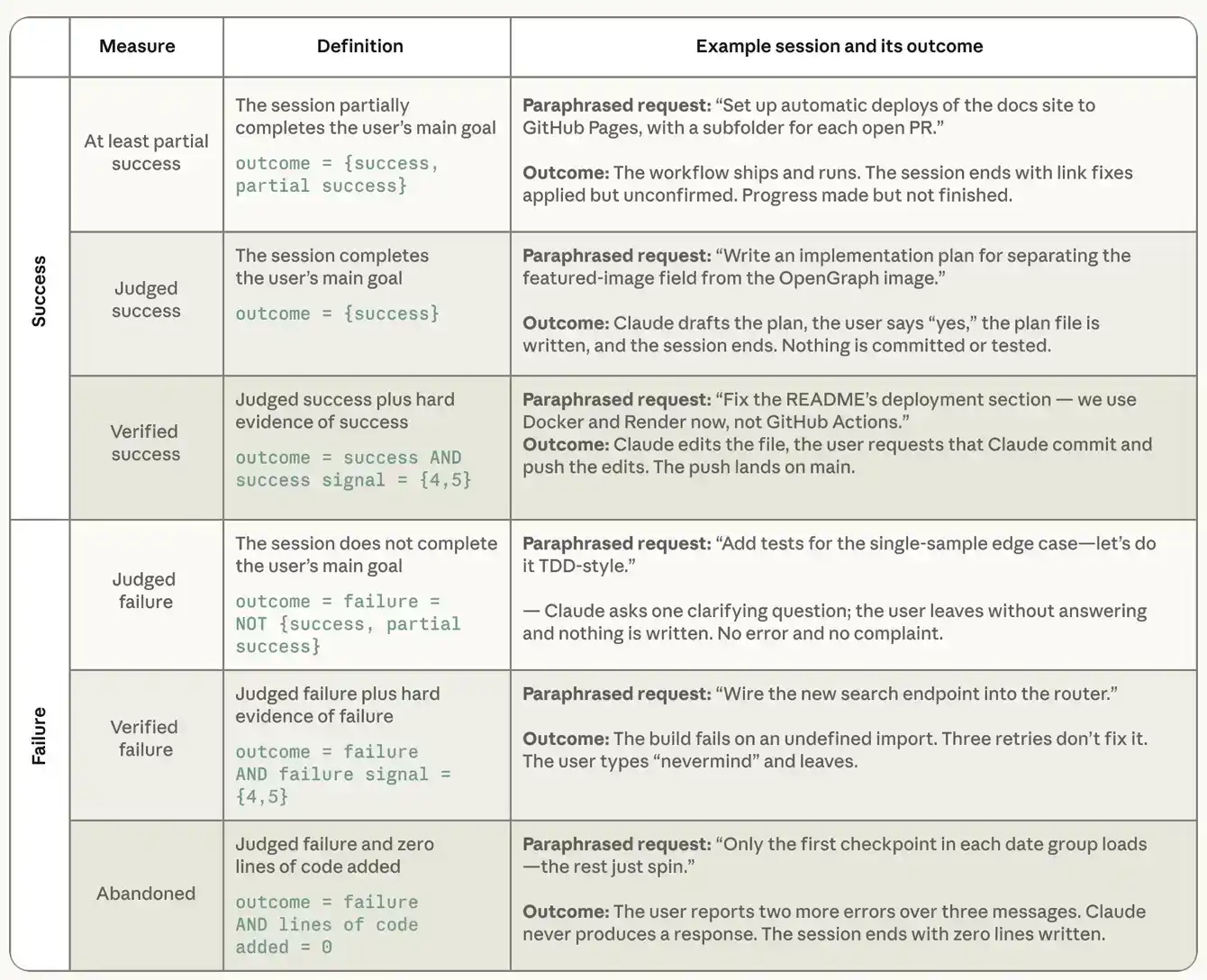
Avant d'analyser les caractéristiques des sessions réussies, nous devons préciser comment nous mesurons le succès. Nous ne pouvons pas observer les résultats dans le monde réel, ni demander directement aux utilisateurs s'ils ont accompli ce qu'ils voulaient avec Claude. Nous nous appuyons donc sur deux mesures complémentaires basées sur les transcriptions. La première est le « succès jugé », où un classifieur lit la transcription complète de la session et détermine si l'utilisateur a atteint son objectif initial, avec des options : succès, succès partiel, échec, aucun objectif clair. Ensuite, deux classifieurs complémentaires évaluent la force des preuves de ce jugement pour déterminer le « succès vérifié ». Le classifieur de signaux de succès recherche des preuves vérifiables de succès, en particulier les activités git correspondant au travail (commits, pull requests), la réussite de suites de tests, et l'expression explicite de satisfaction de l'utilisateur. Il note la session sur une échelle allant de « aucun signal » à « signal faible » (1 point) jusqu'à « plusieurs signaux forts » (5 points). Un classifieur parallèle de signaux d'échec note les preuves que quelque chose a mal tourné : erreurs, tests échoués, tentatives répétées de la même chose, objections de l'utilisateur, etc. Le succès vérifié requiert deux conditions simultanées : la session est jugée comme un succès, et il existe au moins un signal fort et vérifiable de succès. L'analyse suivante se concentre sur le degré de succès ou d'échec des sessions, nous excluons donc les sessions jugées « aucun objectif clair » par le classifieur de résultats, représentant environ 7,7% de l'échantillon complet.
Les bénéfices du niveau de compétence
Quelles sessions ont donc le plus de chances de réussir ? Les résultats montrent que le score de niveau de compétence de session décrit précédemment a une forte influence sur le succès de la session.
On pourrait craindre que le niveau de compétence ne soit pas le vrai facteur déterminant. Peut-être que les experts choisissent simplement des tâches différentes, ou diffèrent à d'autres égards. Dans cette section, nous répondons en partie à cette préoccupation en comparant des sessions de même type de travail, de même valeur estimée, du même mois, sur le même sujet, provenant du même grand groupe professionnel, et examinons comment le niveau de compétence de l'utilisateur influence les résultats.
Pour tous les indicateurs de succès, plus le niveau de compétence manifesté par l'utilisateur dans la session est élevé, plus la session a de chances de réussir. Les sessions notées comme novices atteignent un succès selon notre indicateur le plus strict, le « succès vérifié », dans 15% des cas, et un succès au moins partiel dans 77% des cas. Les sessions notées intermédiaires et au-dessus atteignent un taux de succès vérifié de 28% à 33%, et un taux de succès au moins partiel de 91% à 92% (voir Figure 5).
Pour chaque indicateur, la majeure partie du bénéfice provient du passage de novice à intermédiaire ; la pente ralentit ensuite du niveau intermédiaire à expert. Pour les détails de l'analyse de régression sous-jacente à la Figure 5, voir l'annexe.
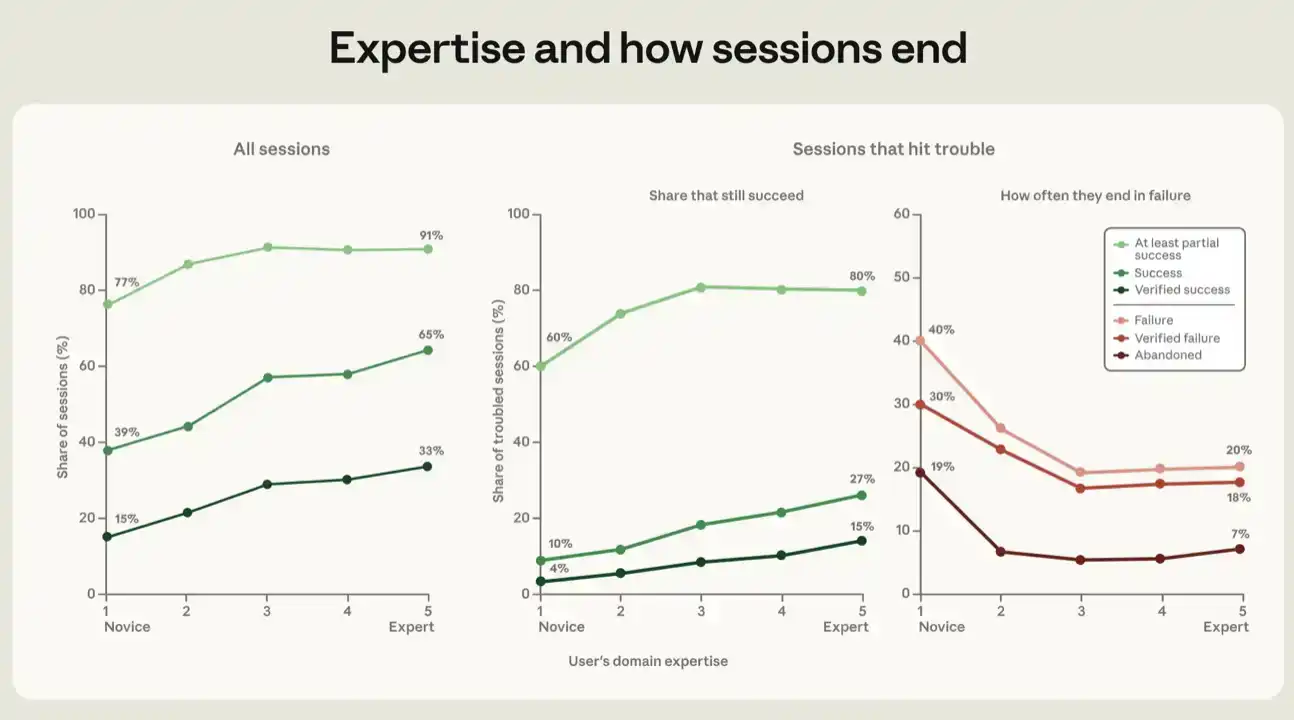
On observe un gradient similaire dans les sessions rencontrant des difficultés. Lorsque les signaux d'échec enregistrent des preuves vérifiées d'échec, nous considérons que la session « a rencontré un problème ». Cela peut inclure des erreurs, des tests échoués, plusieurs tentatives pour accomplir la même chose, ou l'expression de frustration et de mécontentement par l'utilisateur. Parmi les sessions ayant rencontré un problème, après contrôle des variables ci-dessus, la proportion de succès vérifié passe de 4% pour les sessions de novices à 15% pour les sessions d'experts (voir Figure 5). Avec un indicateur de succès plus large, nous constatons que la proportion de succès au moins partiel est de 60% chez les utilisateurs novices, et de 80% à 81% chez les utilisateurs intermédiaires à experts.
Nous avons également tracé la relation inverse, entre le niveau de compétence et divers indicateurs d'échec. Il est important de noter que dans cette analyse, les sessions jugées comme des échecs sont celles qui n'atteignent même pas un succès partiel. Si une session ayant rencontré un problème est jugée comme un échec et n'a écrit aucune ligne de code, nous la qualifions d'abandonnée. Dans les sessions où l'utilisateur semble novice, 19% sont finalement abandonnées ; dans les autres groupes d'utilisateurs, ce taux est de 5% à 7%. En d'autres termes, les utilisateurs les moins expérimentés, lorsqu'ils rencontrent des difficultés en cherchant à atteindre un objectif, abandonnent plus facilement. Une partie de la valeur des compétences professionnelles semble résider dans la capacité à ramener l'agent sur la bonne voie.
La profession est peut-être moins importante que le niveau de compétence
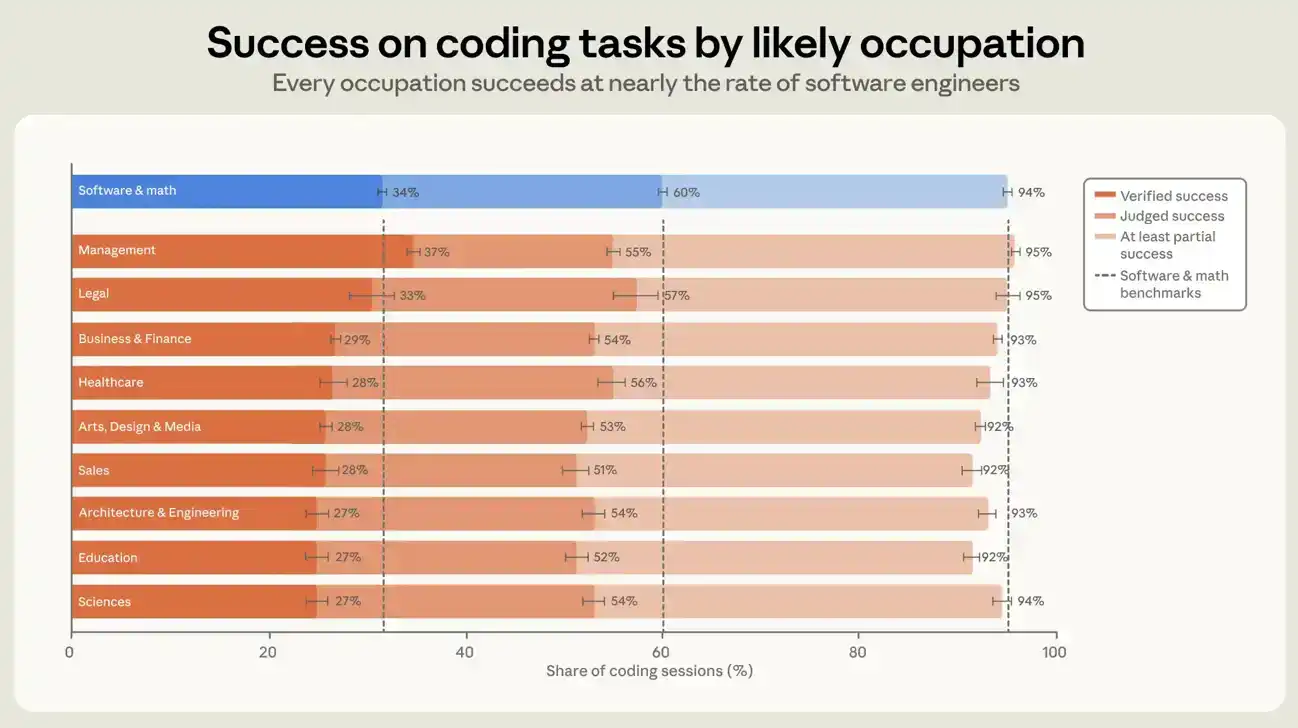
Les utilisateurs des professions liées aux logiciels ont un taux de succès vérifié d'environ 30% sur toutes les sessions, contre environ 26% pour les autres professions. Dans les sessions générant du code, c'est-à-dire celles ajoutant ou modifiant au moins une ligne de code, ces chiffres sont respectivement de 34% et 29% (voir Figure 6). Avec une définition plus large du succès, l'écart entre les professions liées aux logiciels et les autres se réduit davantage. Dans les sessions générant du code, les proportions atteignant au moins un succès partiel sont de 89% et 88% respectivement. Un écart de cinq points n'est pas énorme, et il n'a ni augmenté ni diminué au cours des sept mois, bien que le taux de réussite des deux groupes ait progressé. Dans les sessions générant du code, les dix plus grands groupes professionnels de notre ensemble de données présentent chacun un écart de réussite de moins de sept points de pourcentage par rapport aux ingénieurs logiciels. Les professions de gestion ont le taux de succès vérifié le plus élevé, légèrement supérieur à celui des ingénieurs logiciels. Le taux de succès vérifié plus élevé des gestionnaires pourrait refléter la transférabilité des compétences managériales à la tâche de diriger un agent. Mais cela peut aussi provenir en partie de notre méthode de mesure : la vérification s'appuie dans une certaine mesure sur la confirmation explicite de l'utilisateur dans la session, et les gestionnaires peuvent être plus habitués à s'exprimer lorsqu'ils obtiennent le résultat souhaité.
Perspectives
Les résultats de ce rapport esquissent un tableau émergent : la programmation par agents intelligents amplifie certaines connaissances et compétences, tout en en remplaçant d'autres. Dans les sessions générant du code, les taux de réussite des principales professions diffèrent peu de ceux des professions liées aux logiciels. Il semble que les agents de codage rendent le fait d'avoir une formation en programmation moins important pour réussir une tâche de programmation.
Parallèlement, les sessions réussies ont plus de chances de manifester une expertise métier. Les sessions classées comme expertes ont un taux de succès vérifié plus de deux fois supérieur à celui des sessions de novices. Lorsqu'une session rencontre un problème, les novices abandonnent plusieurs fois plus souvent que les autres utilisateurs. La façon même de collaborer rend ce tableau plus clair : les experts du domaine peuvent guider Claude vers plus de travail accompli par instruction. Ainsi, la capacité à orienter Claude vers le succès provient davantage de la maîtrise d'un domaine que de la capacité à écrire du code. Toute personne possédant cette maîtrise dans n'importe quel domaine peut désormais accomplir des travaux techniques qu'elle ne pouvait pas réaliser auparavant. Ceux qui manquent de cette compréhension professionnelle, même avec le même outil, en tireront beaucoup moins. De plus, le bénéfice principal provient de la compétence, et non de l'expertise. Avoir une compréhension opérationnelle d'un domaine procure déjà la majeure partie du bénéfice ; une spécialisation approfondie n'apporte qu'un avantage supplémentaire limité.
Ces découvertes sont encore préliminaires. Comme pour la plupart de nos recherches, nous ne pouvons pas mesurer les résultats dans le monde réel, par exemple si le code écrit lors d'une session est ensuite utilisé ou jeté, ou s'il produit des résultats ayant une valeur économique. De plus, ce rapport exclut les utilisations non interactives, qui représentent une part considérable de l'activité globale. Développer un cadre capable de mesurer ce type d'utilisation est un axe de travail futur important. Par ailleurs, toutes nos classifications de sessions reposent sur la lecture des transcriptions par le modèle. Dans l'annexe, nous montrons que les classifieurs sont cohérents avec les données de télémétrie indépendantes dans les directions attendues, et qu'ils sont en accord avec les jugements d'un modèle de référence solide pour la plupart des sessions. Cependant, la validation des classifieurs à grande échelle reste difficile ; les sessions Claude Code elles-mêmes ajoutent à cette difficulté car elles peuvent être trop longues et complexes pour servir de référence fiable via un étiquetage humain.
Au fur et à mesure que les modèles, les utilisateurs et la division du travail entre eux évoluent, le tableau présenté dans ce rapport sera mis à jour. Nous espérons que ces indicateurs nous aideront à suivre les transformations majeures en cours. Par exemple, si à l'avenir les bénéfices liés au niveau de compétence commencent à diminuer, cela indiquera que les modèles commencent à fournir le jugement clé que les utilisateurs apportent actuellement, et les bénéfices de ces outils s'étendront des experts du domaine à une population plus large. Si la proportion d'utilisateurs hors des professions logicielles réussissant des sessions de codage continue d'augmenter, cela pourrait signifier que la production de logiciels devient une partie ordinaire du travail dans tous les domaines, et non plus le produit d'une profession unique. Ces transformations changeront qui bénéficie de la programmation par agents intelligents, et dans quelle mesure, et affecteront les capacités les plus valorisées sur le marché du travail.





