Auteur : qinbafrank
En février, dans l'article « Que signifie cette guerre des dépenses en capital ? », nous avons évoqué le fait que les maillons clés de la chaîne industrielle de la puissance de calcul peuvent encore capter la plus grande valeur : les puces, l'assemblage et les tests, la mémoire, les modules optiques, etc. Les capacités qui ne peuvent pas être rapidement étendues et celles qui disposent de barrières à l'entrée extrêmement élevées profiteront des énormes dépenses en capital.
La marge d'optimisation de l'efficacité reste considérable : la distillation, la quantification, le MoE, les puces dédiées, le refroidissement liquide, la fusion nucléaire (à long terme) côté inférence pourraient réduire la consommation énergétique et le coût par unité de puissance de calcul d'un facteur 10 à 100. Il faut chercher des opportunités dans ces domaines.
Récemment, plusieurs banques d'investissement (Morgan Stanley, JPMorgan, Bank of America, Goldman Sachs, UBS, Citi, Bernstein, HSBC) ont publié des rapports de mise à jour sur l'IA/les semi-conducteurs/l'électricité/la mémoire. Le goulot d'étranglement du matériel IA s'est étendu d'une unique dimension « l'approvisionnement en GPU » à une tension collective sur cinq dimensions : l'électricité, les puces, la mémoire, les équipements et les matériaux.
Le niveau de demande de l'IA a dépassé les intervalles de prévision de tous les modèles de planification énergétique traditionnelle, de capacité des équipements semi-conducteurs, de prix de la mémoire et d'hypothèses d'installation de robots.
Une analyse thématique mondiale de Morgan Stanley indique que la consommation hebdomadaire mondiale de tokens de grands modèles linguistiques est passée de 6,4 billions à 22,7 billions en 3 mois, soit une augmentation de 2,5 fois. Les États-Unis auront un déficit de 55 GW d'électricité pour les centres de données entre 2025 et 2028. JPMorgan, dans sa première couverture de la dette de projet pour le calcul haute performance dans les centres de données, avance directement le chiffre d'un « déficit de financement de 122 GW sur les 5 prochaines années ». La planification électrique américaine sur 5 ans est passée de 101 GW à 230 GW, et 44 % des nouveaux projets ont des délais de raccordement supérieurs à 4 ans. Dans son dernier rapport de prix cible pour Alphabet, Bank of America a directement relevé les dépenses en capital de 2026 à 1 815 milliards de dollars, soit un doublement en glissement annuel, et prévoit une baisse de 62 % du flux de trésorerie disponible. Ces trois ensembles de données ne proviennent pas du même cadre d'analyse, mais sont des images indépendantes établies par trois institutions différentes suivant des chemins de recherche distincts.
L'évolution des goulots d'étranglement dans la chaîne industrielle des semi-conducteurs (en particulier dans le domaine de la puissance de calcul IA) progresse précisément selon l'ordre clair suivant : « Calcul (GPU) → Mémoire (HBM, etc.) → Interconnexion optique → Électricité/Refroidissement liquide ». C'est le consensus sectoriel pour 2025-2026. Alors que les grappes d'entraînement/d'inférence IA passent d'un baie unique (quelques dizaines de GPU) à des échelles hyper-dimensionnées (de milliers à des dizaines de milliers de GPU), chaque fois qu'un goulot d'étranglement est résolu, la prochaine limite physique/du supply chain est immédiatement exposée, formant une contrainte complémentaire « à la Leontief » (l'absence d'un seul élément empêche l'expédition).
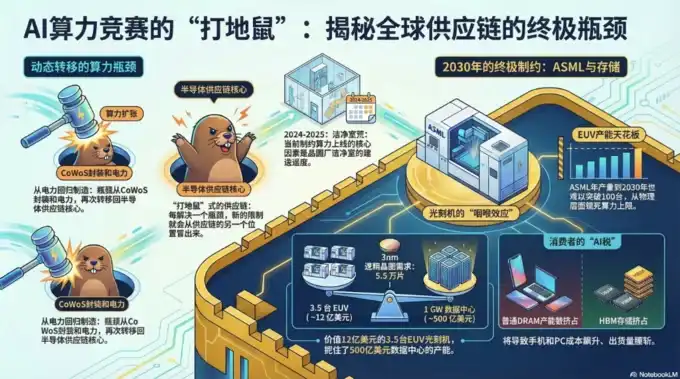
Il est nécessaire de comprendre pourquoi cette évolution se produit, la situation actuelle et les raisons physiques/techniques sous-jacentes :
1. Premier goulot d'étranglement : Calcul GPU (dominant en 2022-2024) Limitation principale :
La capacité en tranches (wafers) des GPU haut de gamme (comme NVIDIA Hopper H100 → Blackwell B200 → Rubin) + l'assemblage avancé.
Pourquoi un goulot d'étranglement : Les grands modèles d'IA nécessitent des calculs parallèles massifs. La capacité des procédés logiques TSMC en 4nm/3nm/2nm + l'assemblage CoWoS (2,5D/3D) sont devenus les principaux points de blocage. Même si les tranches frontales (wafers) sont suffisantes, la capacité backend à assembler les puces logiques + la mémoire HBM empilée ne suit pas, et le GPU entier ne peut pas être produit.
Allègement de la situation : TSMC étend massivement CoWoS (doublement de la capacité en 2024-2025), NVIDIA Blackwell est expédié à grande échelle. Mais cela ne fait que débloquer l'étape « calcul », exposant immédiatement de nouveaux problèmes.
2. Deuxième goulot d'étranglement : Mémoire (HBM - mémoire à haut débit, devenu le plus critique en 2024-2025)
Limitation principale : Capacité de production HBM3/HBM3e/HBM4.
Pourquoi devient-il le goulot d'étranglement suivant : La puissance de calcul des GPU a augmenté, mais la croissance explosive des paramètres des modèles (milliers de milliards, voire dizaines de milliers de milliards de paramètres) a fait du transfert de données (bande passante mémoire) le « mur de la mémoire ». Le HBM peut transférer plusieurs To de données par seconde, soit plus de 20 fois plus vite que la mémoire DDR standard. Comme le HBM est adjacent à la puce logique, les données n'ont pas besoin d'être transmises loin, ce qui permet d'économiser de l'énergie.
Un GPU B200 nécessite 192 Go+ de HBM3e, un seul baie (NVL72) contient déjà 30-40 To de HBM, et les besoins en bande passante dépassent largement ceux de la DRAM traditionnelle.
Situation de la chaîne d'approvisionnement : Seuls SK Hynix, Samsung et Micron peuvent produire du HBM à l'échelle industrielle. Le processus est complexe (TSV + empilement). Toute la production de 2025 est déjà vendue, celle de 2026 reste insuffisante face à la demande, avec une hausse des prix de 246 % en glissement annuel. Même si les puces GPU sont prêtes, sans HBM, l'assemblage et la livraison sont impossibles, retardant le déploiement de grappes IA entières.
Résultat : La mémoire est passée de « marchandise » à un maillon stratégique crucial, pouvant représenter jusqu'à 30 % des dépenses en capital.
3. Troisième goulot d'étranglement : Interconnexion optique (en cours de transition en 2025-2026)
Limitation principale : Limites physiques des câbles cuivre (NVLink/NVSwitch) en termes de bande passante, distance, consommation électrique et poids.
Pourquoi une transition vers l'optique est inévitable : À l'intérieur d'un baie unique (72 GPU), le cuivre reste possible. Mais pour s'étendre à plusieurs baies, voire interconnecter des milliers de GPU, l'atténuation du cuivre est sévère (bande passante de 1,8 To/s, distance efficace < 1 mètre), le poids explose (baie NVL72 : plus de 5 000 câbles cuivre, poids total 1,36 tonne), et la consommation électrique est élevée (les modules optiques enfichables remplaçant le cuivre consommeraient 20 000 W supplémentaires). L'intégrité du signal, la latence et le refroidissement ne peuvent pas supporter des grappes plus grandes.
Solution : Transition vers l'interconnexion optique (CPO - Co-Packaged Optics + technologie du silicium photonique). Intégrer les moteurs optiques directement à côté des GPU/ASIC, utiliser la fibre optique pour la mise à l'échelle (Scale-Out), obtenant une densité de bande passante plus élevée, une consommation par bit plus faible et une distance plus longue.
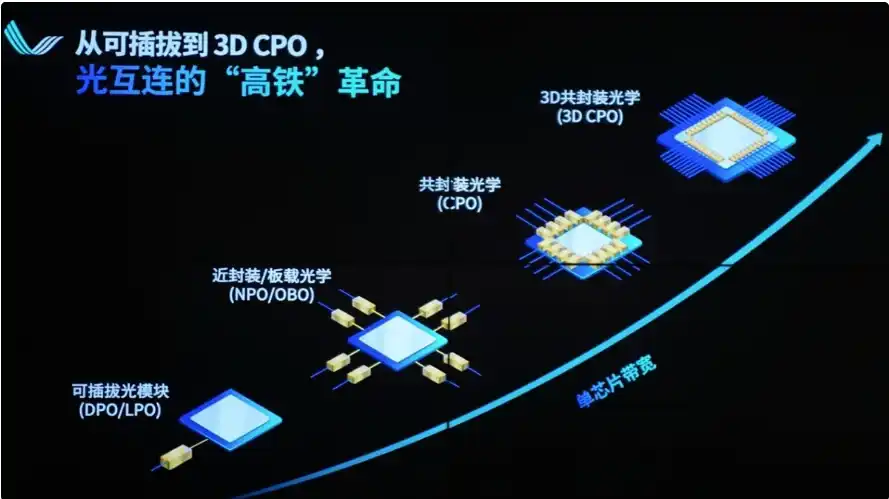
NVIDIA a fortement misé là-dessus lors de la GTC 2026, a investi dans des sociétés d'optique, et la demande pour les modules optiques 800G/1,6T explose. Lite, Broadcom, Coherent, Ayar Labs, etc., deviennent les nouveaux gagnants.
Progression actuelle : Le cuivre a atteint sa limite, l'interconnexion optique passe de « optionnelle » à « obligatoire », repoussant le plafond de performance des centres de données IA.
4. Quatrième goulot d'étranglement (à la pointe actuelle) : Électricité + Refroidissement liquide (devenant la contrainte physique ultime à partir de 2026) Limitation principale : Mur de la consommation + mur thermique + raccordement au réseau électrique.
Pourquoi le goulot d'étranglement ultime : La consommation de chaque GPU est passée de 300W → 700-1200W, un baie unique est passé de 10-20 kW (ère des CPU) à plus de 120-200 kW+, voire plus. La limite physique du refroidissement par air traditionnel n'est que de 20-50 kW, le bruit, le flux d'air et la consommation énergétique deviennent inacceptables.
Côté électricité : Les centres de données ont besoin d'une alimentation de l'ordre du GW, les files d'attente de raccordement au réseau peuvent atteindre plusieurs années, et les délais de livraison des transformateurs, transformateurs à état solide, etc., s'allongent jusqu'à 100 semaines. Le PDG de Microsoft a déclaré sans ambages « avoir des GPU mais pas d'électricité pour les brancher ».
Côté refroidissement liquide : Il faut passer au refroidissement liquide Direct-to-Chip (direct sur puce) ou par immersion, combiné à la microfluidique, aux plaques froides, etc. TSMC a déjà démontré le refroidissement liquide sur silicium sur sa plateforme CoWoS, supportant > 2,6 kW TDP. Les fabricants de gestion thermique/refroidissement liquide comme Vertiv (VRT) deviennent de nouveaux acteurs clés de l'infrastructure.
Effet domino : Le PUE (Power Usage Effectiveness) doit être < 1,2. La récupération de chaleur fatale, l'intégration de l'énergie nucléaire/des nouvelles énergies deviennent de nouveaux sujets. Même si toutes les étapes précédentes sont résolues, sans électricité et sans refroidissement, les baies ne peuvent pas être installées et fonctionner.
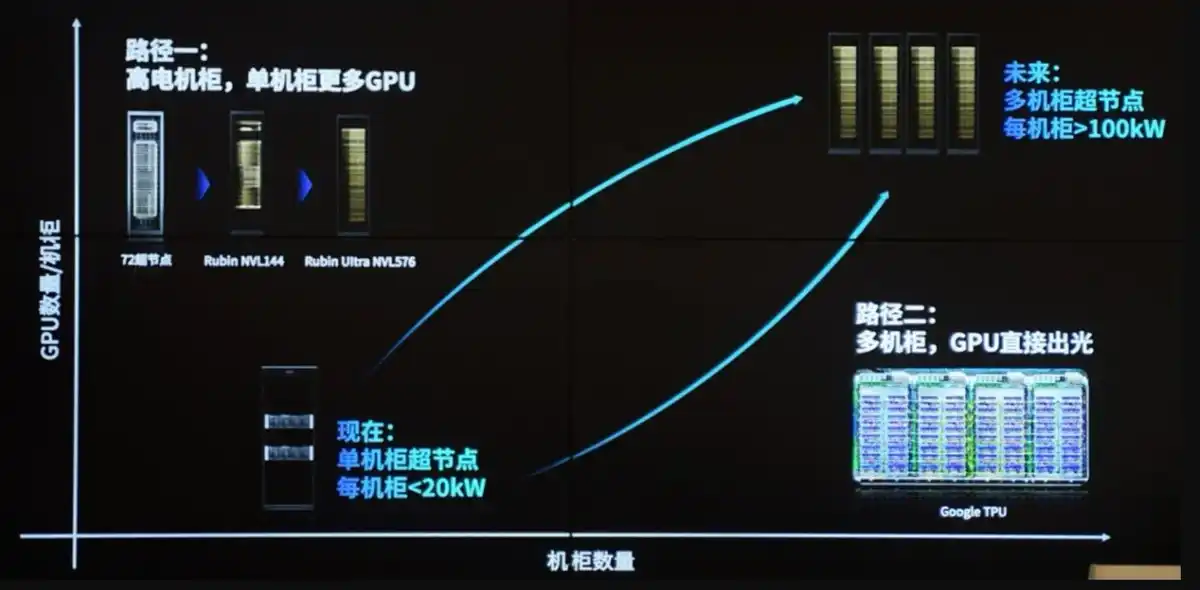
Logique fondamentale de la transmission des goulots d'étranglement dans la chaîne industrielle de la puissance de calcul IA La puissance de calcul IA n'est pas un problème « ponctuel », mais une fonction de production systémique de type Leontief – les GPU, HBM, interconnexions, électricité et refroidissement doivent correspondre au maillon le plus faible. Les hyperscalers (Google, Microsoft, Meta, etc.) résolvent un problème, puis dirigent immédiatement leur capital et leur innovation vers le maillon suivant.
Actuellement (2026), nous sommes dans une période de transition « déploiement accéléré de l'interconnexion optique + commercialisation à grande échelle de l'électricité/du refroidissement liquide ». De nouveaux goulots d'étranglement pourraient apparaître à l'avenir (comme les lasers, les matériaux de fibre optique ou les transformateurs de réseau électrique), mais cette chaîne « Calcul → Mémoire → Optique → Électricité/Refroidissement » est désormais une voie reconnue par le secteur.
Cela explique également pourquoi la logique d'investissement passe de NVIDIA/TSMC aux trois géants du HBM (SK Hynix, etc.), aux fabricants d'optique (Lumentum, Coherent), et aux infrastructures de refroidissement liquide/électricité (Vertiv, sociétés d'alimentation électrique associées).
Chaque transmission de goulot d'étranglement redéfinit la répartition de la valeur dans toute la chaîne industrielle des semi-conducteurs + centres de données.
![Derive [DRV] gagne 40 % suite à l'annonce d'Upbit – CETTE zone constitue le prochain obstacle majeur](https://d1x7dwosqaosdj.cloudfront.net/images/2026-07/eaae977149b14ebfb52e436d178595ee.jpg)





