Rédaction de Machine Heart
Le nouveau modèle open source de Google, Gemma 4, a offert une belle surprise au secteur il y a quelques jours.
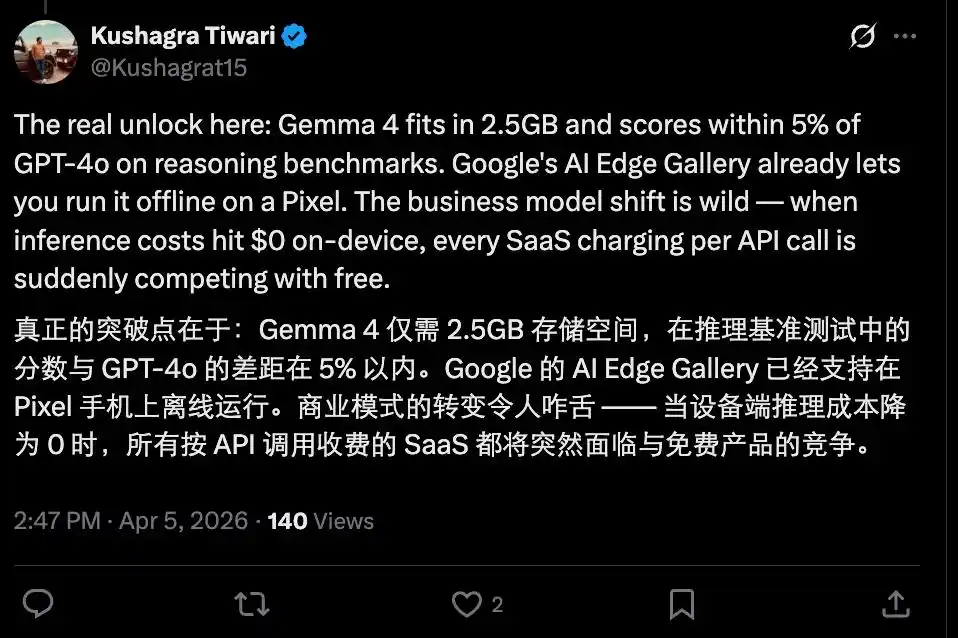
Il adopte une architecture technologique homologue à celle de Gemini 3, prend en charge le multimodal natif, a obtenu la troisième place mondiale au classement Arena AI, et propose plusieurs modèles. Les plus petits modèles — E2B (2,3 milliards de paramètres effectifs) et E4B (4,5 milliards de paramètres effectifs) — peuvent être déployés et exécutés localement sur un téléphone portable, avec une fenêtre contextuelle atteignant 128K. On peut dire que c'est un « substitutif à Gemini qui tient dans la poche ».
Sans surprise, le modèle est rapidement devenu un nouveau jouet pour les utilisateurs de mobiles.
Un post d'un utilisateur de X a notamment été vu des centaines de milliers de fois. Il y a partagé une vidéo montrant comment il exécutait Gemma 4 localement sur son iPhone, y compris le traitement d'images, d'audio et le contrôle de l'interrupteur de la lampe torche. Il a déclaré que Gemma 4 était incroyablement rapide, comme par magie.

Quelqu'un a quantifié cette vitesse sur un iPhone 17 Pro, indiquant que si le téléphone utilise une puce Apple, alors avec l'aide de MLX (le framework d'apprentissage automatique d'Apple) optimisé pour cette puce, la vitesse d'inférence du modèle peut dépasser 40 tokens par seconde.

D'autres ont également obtenu des vitesses similaires sur un Samsung Galaxy, et ce même avec le mode de réflexion activé. Ce qui pousse à s'exclamer que c'est « trop rapide pour être vrai ».
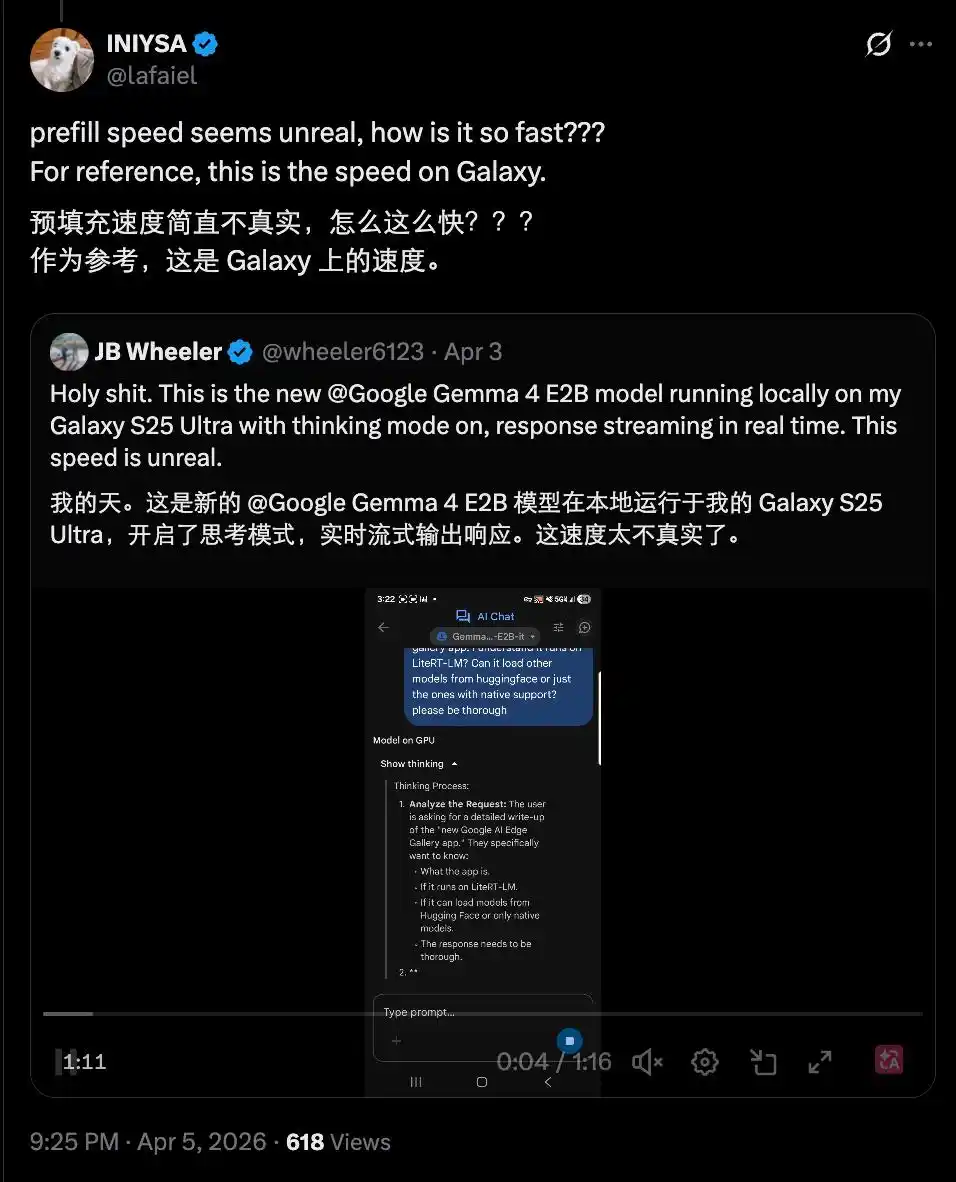
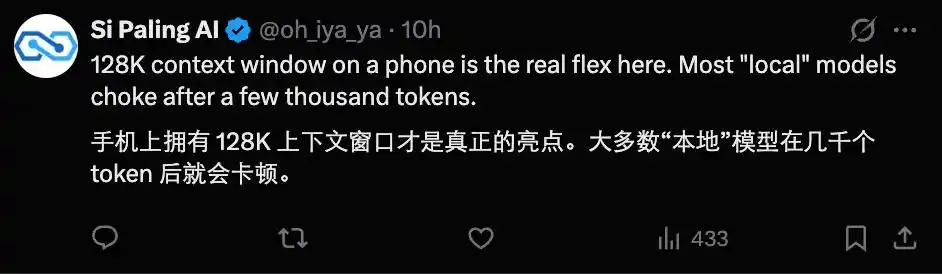
Une telle vitesse fait de l'exécution de modèles d'IA sur appareil mobile une option viable pour l'avenir, et elle est très utile dans des scénarios sensibles comme la santé.
La fenêtre contextuelle de 128k rend également ces petits modèles plus attractifs.
Alors, comment l'exécuter ? C'est en fait très simple, ce n'est pas réservé aux geeks, car Google a publié une application officielle — Google AI Edge Gallery. Les personnes souhaitant l'expérimenter sur leur téléphone peuvent simplement télécharger cette application, puis télécharger la version du modèle qu'ils souhaitent exécuter, l'ouvrir et c'est parti.

De plus, comme c'est une publication officielle de Google, les problèmes de sécurité ne sont pas vraiment à craindre.
Outre ces petits modèles exécutés sur mobile, certains ont testé des versions plus grandes de Gemma 4 sur du matériel plus puissant, comme l'exécution de Gemma 4 Mixture-of-Experts 26B sur un MacBook Pro version M5 Pro.

Pour une conversation directe, ce modèle est encore rapide, la génération de texte et l'explication de code sont fluides.

Mais lorsqu'il a vraiment utilisé Gemma 4 comme agent de codage, les problèmes sont apparus. Car exécuter un agent nécessite un grand contexte (Gemma 4 26B a une fenêtre contextuelle de 256k), des prompts complexes et des appels d'outils stables. Gemma 4 a clairement du mal à tenir le coup sur ces aspects, plantant souvent, générant des erreurs, ou produisant une structure de sortie incorrecte.

Le point de basculement est survenu lorsqu'il a remplacé le modèle par qwen3-coder. Dans le même environnement, la création de fichiers, l'exécution de commandes et les tâches à plusieurs étapes fonctionnaient normalement. Il estime que le problème ne vient pas du framework d'agent, mais du modèle lui-même et de son éventuelle optimisation pour les « appels d'outils + sortie structurée ». Sur ce point, Gemma 4 n'est peut-être pas encore assez abouti, ou peut-être que ce développeur n'a tout simplement pas encore trouvé la bonne méthode.

De plus, certains disent que le niveau intellectuel de Gemma 4 est encore un peu limité.
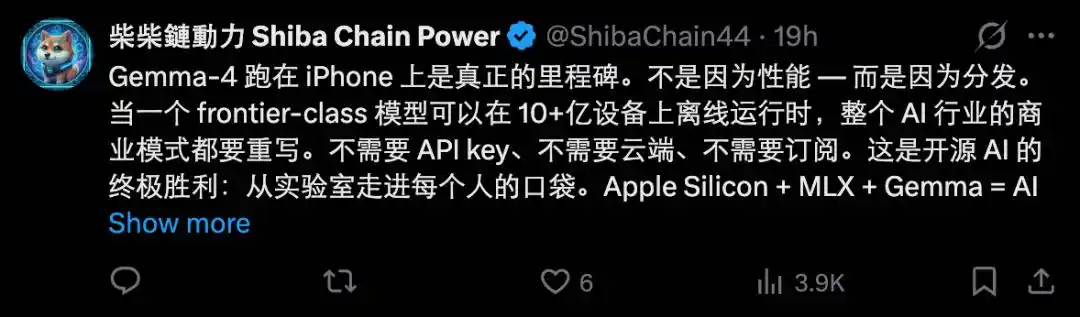
Malgré cela, l'émergence de Gemma 4, cette « petite bombe de performances », ne doit pas être sous-estimée. Si à l'avenir, une grande partie des requêtes quotidiennes, des discussions, des raisonnements simples, de la génération de code et des tâches de compréhension d'images peuvent être exécutées localement, sans avoir à acheter de tokens, les vendeurs de tokens ne se retrouveraient-ils pas dans une position délicate ?
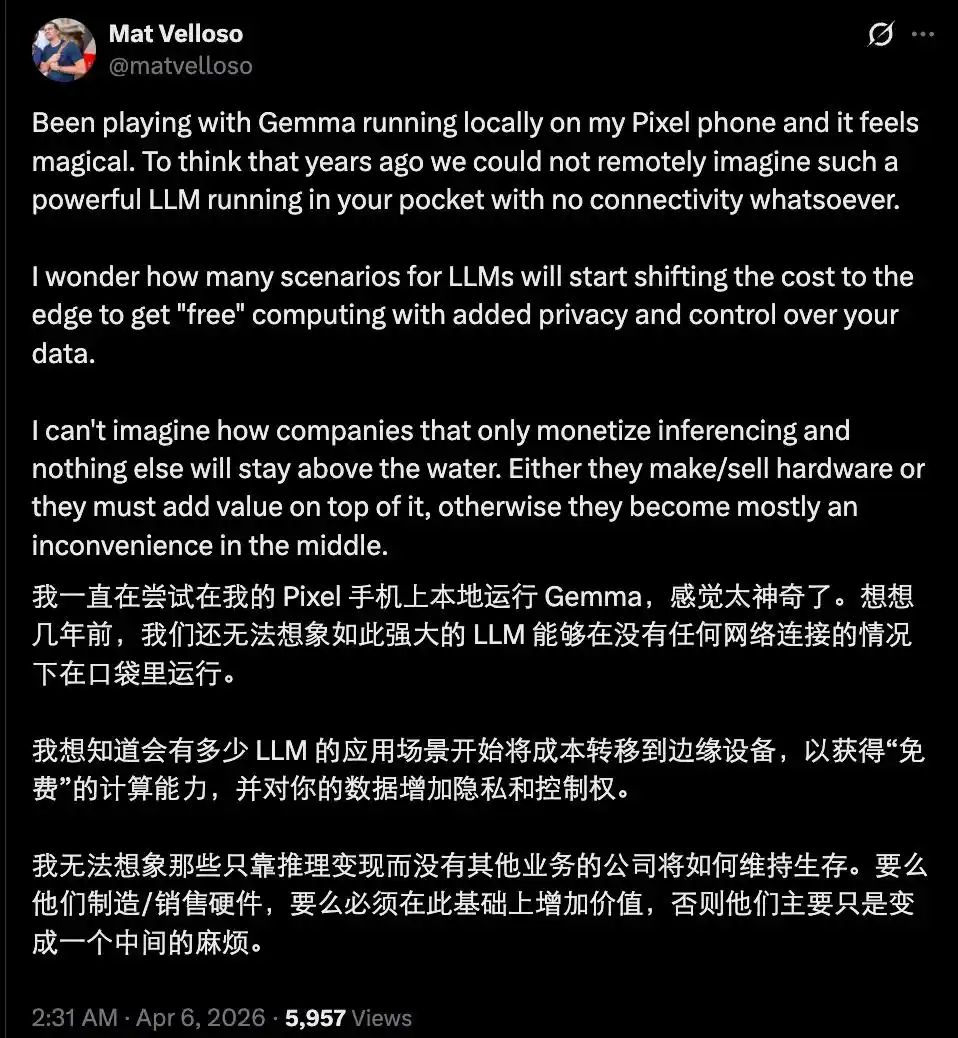
Bien sûr, la situation actuelle n'est pas encore si pessimiste, car il existe encore un écart entre les modèles open source disponibles et les modèles propriétaires de pointe, et la plupart des modèles open source performants sont encore limités par les capacités matérielles, ne pouvant temporairement pas atteindre un niveau utilisable sur les appareils.
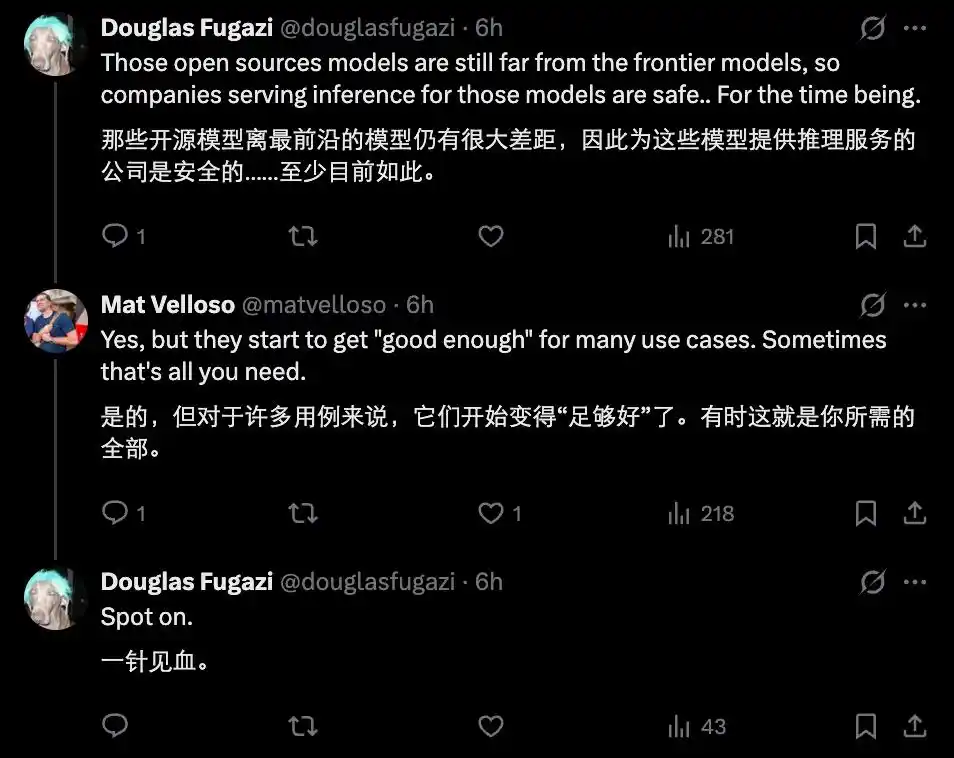
Mais la tendance future est claire. À court terme, les modèles propriétaires cloud conservent leur avance sur le raisonnement complexe de pointe et la collaboration multi-agents à très grande échelle ; mais à long terme, avec la progression du matériel et l'optimisation continue des techniques de quantification, les modèles on-device grignoteront progressivement les tâches simples et fréquentes du cloud.
Les acteurs qui ne vivent que de la vente de tokens et d'abonnements API devront se concentrer plus intensément sur les parties « vraiment difficiles » — les agents ultra-puissants, les contextes longs et fiables, et les capacités spécialisées nécessitant des données massives en temps réel.
Gemma 4 n'est qu'un début. La prochaine surprise pourrait bien être qu'un modèle on-device rende l'utilisateur totalement incapable de sentir la différence entre « local » et « cloud » lors d'une utilisation quotidienne. Le jour où cela arrivera, l'ensemble du modèle économique de l'industrie de l'IA connaîtra un véritable bouleversement.
Cet article provient du compte WeChat officiel « Machine Heart » (ID: almosthuman2014), auteur : Machine Heart