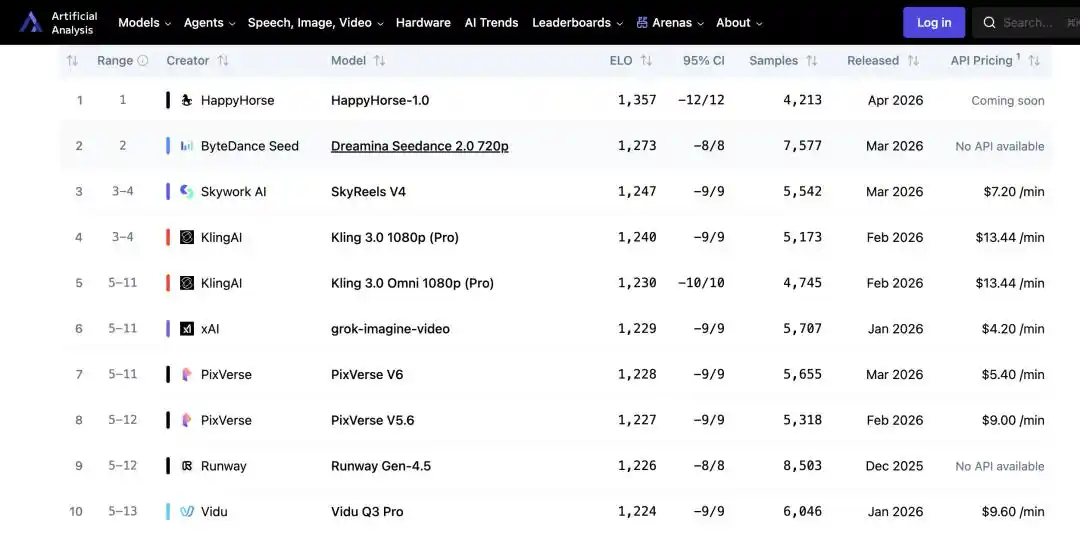
Aucune conférence de presse, aucun blog technique, aucun soutien d'entreprise – un modèle de génération de texte en vidéo nommé HappyHorse-1.0 a discrètement atteint la première place du classement AI Video Arena de la plateforme d'évaluation IA authoritative Artificial Analysis, dépassant avec un score Elo plus élevé Seedance 2.0 et laissant derrière lui des acteurs majeurs comme Kling et Tian Gong, déclenchant instantanément une "course au décryptage" dans les cercles technologiques.
Le classement d'Artificial Analysis n'est pas une évaluation de paramètres techniques, mais un résumé des résultats de tests en aveugle par des utilisateurs réels sous forme de score Elo, reflétant la perception réelle après visionnage. Cela rend ce classement plus difficile à remettre en question qu'un simple benchmark, et fait de "qui est derrière cela" une question impossible à ignorer.
Le "Cheval Heureux" atteint discrètement le sommet, déclenchant un jeu de devinettes dans le milieu technologique
Les spéculations sur X sont arrivées rapidement. La première chose remarquée fut l'ordre des langues sur le site officiel : le mandarin et le cantonais précèdent l'anglais. Pour un produit destiné aux utilisateurs mondiaux, cet ordre est quelque peu inhabituel – si une équipe américaine était aux commandes, l'anglais serait presque invariablement en première position. Une équipe originaire de Chine est pratiquement confirmée.
Le nom lui-même est aussi un indice. 2026 est l'année du Cheval selon le calendrier lunaire, le nom "HappyHorse" cache un clin d'œil peu subtil à l'année du Cheval, une tactique similaire avait été employée plus tôt dans l'année par "Pony Alpha". La liste des suspects s'est donc allongée rapidement : les fondateurs de Tencent et d'Alibaba portent le nom de famille Ma (cheval), ils y figurent naturellement ; certains ont parié sur Xiaomi, estimant que Lei Jun est traditionnellement discret et aime dévoiler ses cartes soudainement ; d'autres ont trouvé que le style ressemblait plus à DeepSeek, car DS avait précédemment lancé discrètement un modèle visuel, puis l'avait retiré tout aussi discrètement. Les spéculations étaient nombreuses et animées, mais aucune n'avait de preuve tangible.
Ce qui a véritablement identifié la cible, c'est une comparaison point par point au niveau technique. L'utilisateur X Vigo Zhao a comparé les données de benchmark publiques de HappyHorse-1.0 avec celles de modèles connus un par un, et a trouvé une correspondance très forte : daVinci-MagiHuman, le modèle open source "Da Vinci Magic Human" mis en ligne sur Github en mars.
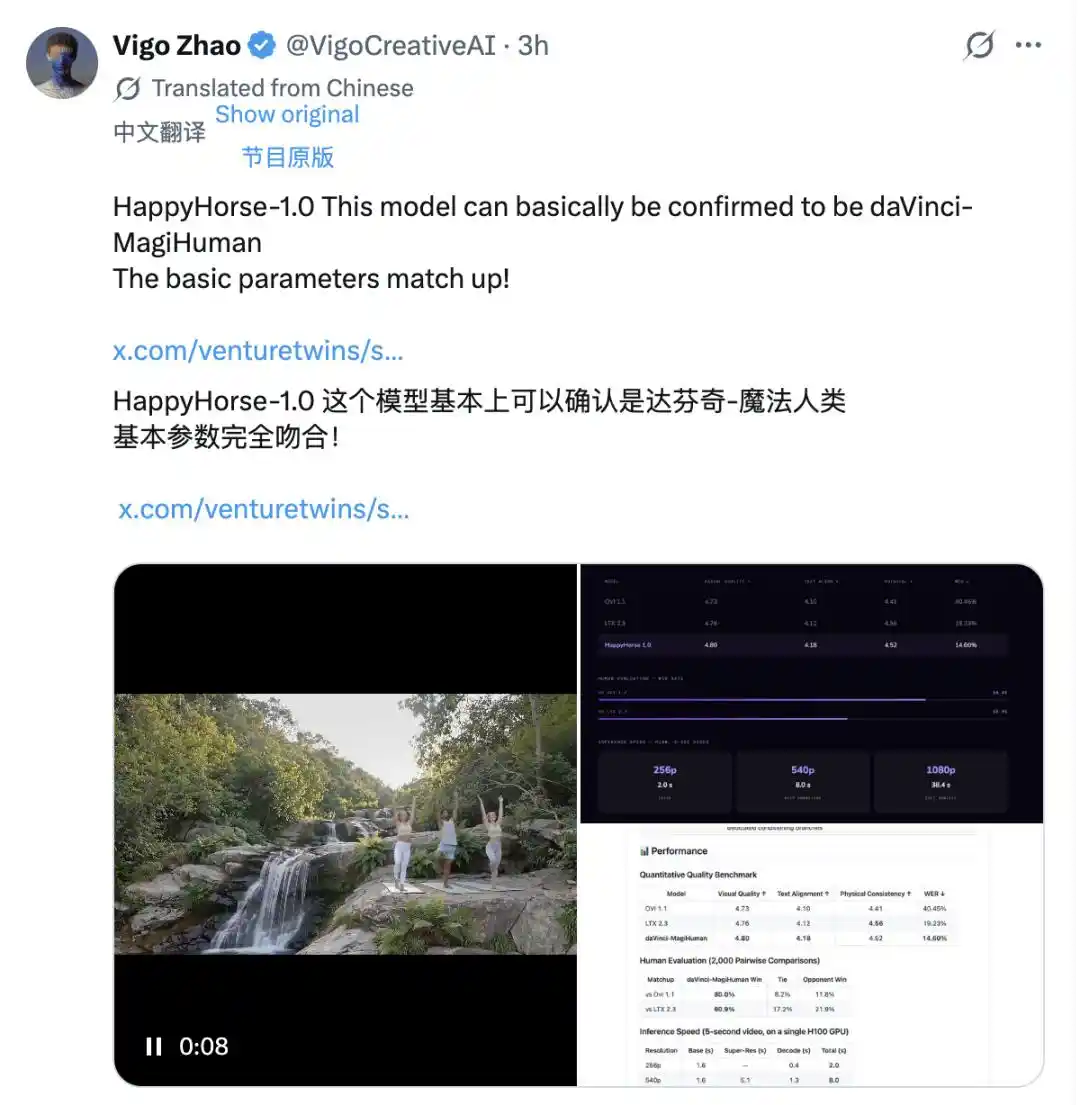
Qualité visuelle 4.80, alignement texte 4.18, cohérence physique 4.52, taux d'erreur de mots dans la parole 14.60% – les données correspondent point par point. La structure du site officiel est aussi presque identique : la description de l'architecture, le tableau des performances, le style de présentation des vidéos de démonstration, tout semble provenir du même modèle. Les deux partagent la même architecture Transformer à flux unique, la même génération conjointe audio-vidéo, et la même liste de langues prises en charge. Un tel degré de coïncidence est difficile à expliquer par le hasard.
La conclusion la plus largement acceptée dans les cercles techniques est que HappyHorse est une version itérative optimisée par Sand.ai, l'un des co-développeurs de daVinci-MagiHuman, basée sur le modèle open source, dans le but principal de vérifier les limites des performances du modèle sous les préférences réelles des utilisateurs et de préparer le terrain pour sa commercialisation future.
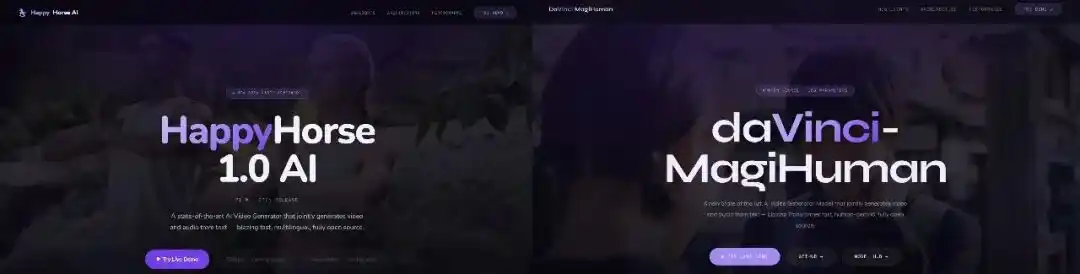
daVinci-MagiHuman a été officiellement open source le 23 mars 2026, fruit de la collaboration de deux jeunes équipes. L'une provient du laboratoire de recherche sur l'intelligence artificielle générative (GAIR) du Shanghai Institute of Intelligence (SII), dirigé par le chercheur Liu Pengfei ; l'autre est Sand.ai (Sand Technology) basée à Pékin, dont le fondateur Cao Yue a également un background académique, et dont l'orientation de l'entreprise est les modèles de monde auto-régressifs.
Le modèle utilise un Transformer à flux unique pur à attention de 15 milliards de paramètres, fourrant les tokens de texte, vidéo et audio dans une même séquence pour une modélisation conjointe – l'open source n'avait jamais réalisé auparavant un pré-entraînement conjoint audio-vidéo véritablement from scratch, la plupart se contentant de coller des bases mono-modales.
Comment un modèle vidéo open source a-t-il réalisé une remontée éclair en deux semaines ?
Une fois l'identité clarifiée, une autre question devient plus difficile à répondre : daVinci-MagiHuman n'est open source que depuis fin mars, comment HappyHorse-1.0 a-t-il pu obtenir un score Elo plus élevé que Seedance 2.0 en seulement deux semaines ?
D'après les informations divulguées sur le site officiel, HappyHorse n'a pas modifié l'architecture sous-jacente de manière significative. L'hypothèse la plus raisonnable est qu'il a effectué des ajustements ciblés sur la stratégie de génération par défaut pour le scénario d'évaluation.
Le système Elo est essentiellement une accumulation des préférences des utilisateurs. Améliorer légèrement les éléments sensibles à la perception comme la stabilité des expressions faciales, l'alignement audio-vidéo, ou l'esthétique visuelle, permet d'être plus facilement choisi dans les tests en aveugle. La limite supérieure des capacités du modèle n'a pas changé, mais les "performances en évaluation" peuvent être polies.
En fait, dans les échantillons de test en aveugle d'Artificial Analysis, la génération de portraits et les contenus de type narration" représentaient plus de 60%, et daVinci-MagiHuman s'est concentré sur la performance de portraits dès la phase d'entraînement, lui conférant un avantage naturel dans ce type de scénario, ce qui est la raison principale de son taux de victoire en aveugle ; si l'échantillon de test en aveugle est principalement composé de gros plans sur des personnages, les modèles spécialisés dans les portraits bénéficieront systématiquement d'un avantage, sans rapport direct avec leurs performances réelles dans des scénarios complexes impliquant plusieurs personnages, des mouvements de caméra complexes ou des narrations temporelles longues.
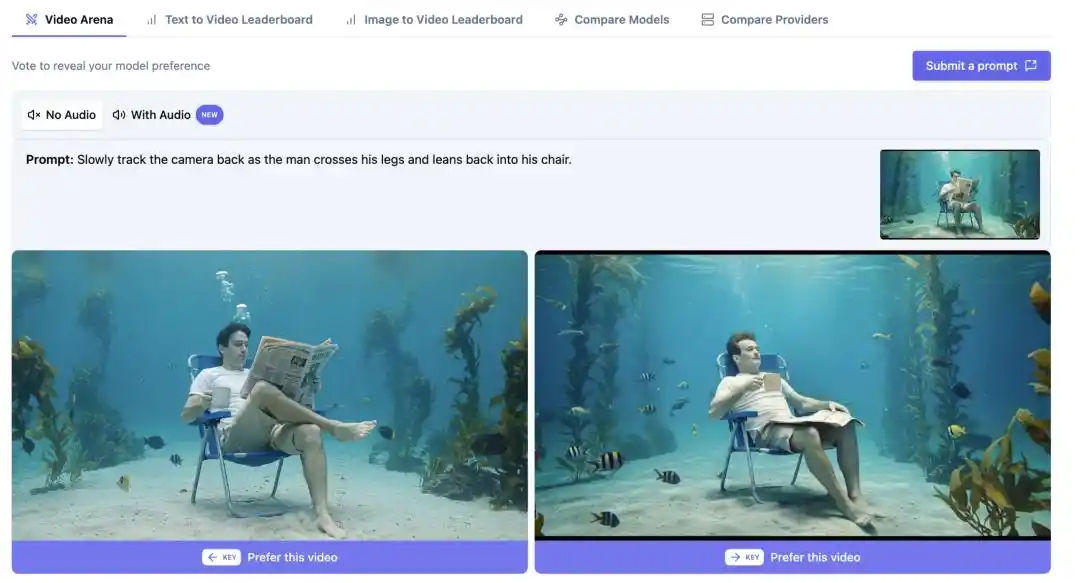
Le résultat est qu'un écart notable est apparu entre les chiffres du classement et l'expérience de test, divisant les commentateurs sur X en deux camps. Les sceptiques, après tests, estiment que HappyHorse-1.0 présente encore un écart visible avec Seedance 2.0 en termes de détails des personnages et de cohérence dynamique, et remettent en question la représentativité du score Elo lui-même.
Les partisans, quant à eux, placent de grands espoirs dans le potentiel de HappyHorse, espérant qu'il pourra résoudre le point sensible de l'industrie qu'est la "cohérence de la qualité d'image dans les séquences multi-plans", car c'est un problème que les modèles vidéo grand public actuels n'ont pas bien résolu. Si daVinci-MagiHuman parvient réellement à faire une percée ici, cela pourrait être bien plus important qu'une place dans un classement.
Les limites du modèle lui-même ne doivent pas non plus être masquées par les chiffres. Le blogueur Xiaohongshu @JACK's AI World a déployé et testé daVinci-MagiHuman dès sa sortie. Il a constaté qu'il nécessitait un H100 pour fonctionner, les cartes graphiques grand public sont基本 exclues, et bien que la communauté travaille sur des solutions de quantification, le déploiement local pour les utilisateurs individuels restera difficile à court terme.
En termes de scénarios, il excelle actuellement principalement pour les personnages uniques ; dès que plusieurs personnages apparaissent ou que la scène devient complexe, la qualité chute – ce n'est pas un problème réglable par paramétrage, c'est directement lié à son orientation de conception axée sur les portraits. La durée de génération est généralement d'environ 10 secondes, au-delà cela devient désordonné, et une sortie haute définition nécessite encore des plugins de super-résolution.
La conclusion de @JACK's AI World est : la facilité d'utilisation globale de daVinci-MagiHuman est inférieure à celle de LTX 2.3, il faudra attendre que la communauté améliore la quantification avant qu'il ne soit adapté à un usage quotidien.
La course à la génération vidéo attend-elle un véritable "poisson-chat" ?
Bien sûr, une première place dans un classement ne signifie pas grand-chose. Ensuite, HappyHorse devra subir des tests plus complets sur la stabilité, la vitesse d'accès en concurrence élevée, la cohérence inter-scénarios, la précision du contrôle des personnages, ainsi que la capacité de généralisation au-delà de l'ensemble d'évaluation. Ce sont là les indicateurs clés qui déterminent si un modèle peut véritablement entrer dans le flux de travail des créateurs.
Mais si l'on élargit le champ de vision à la structure industrielle globale, le signal envoyé par cet événement est déjà suffisamment clair.
Les modèles vidéo open source en eux-mêmes ne sont pas nouveaux. Mais un écart visible au niveau de l'effet a toujours persisté entre l'open source et le闭源 (closed source) – dans les scénarios nécessitant une livraison au client, la qualité de génération des modèles open source n'a pas réussi à franchir durablement le seuil de "utilisable" à "livrable". Le pouvoir de fixation des prix des produits闭源 comme Kling ou Seedance est, dans une large mesure, construit sur cet écart.
Cette fois, la signification réside dans le fait qu'un produit basé sur un modèle open source a, pour la première fois, rivalisé de front avec les principaux concurrents闭源 actuels sur un classement de test en aveugle basé sur la perception réelle des utilisateurs. Quelles que soient les composantes d'optimisation pour le scénario d'évaluation, pour les fabricants闭源 qui dépendent de cet écart pour construire leur pouvoir de fixation des prix, c'est au moins un signal qui mérite d'être pris au sérieux.
Pour les développeurs, la signification de ce point d'inflexion est plus concrète. Dans les scénarios verticaux comme les portraits, les humains numériques, les streamers virtuels, etc., une fois que la qualité de génération de la base open source atteint le seuil "livrable", la structure des coûts du déploiement autonome subira un changement substantiel – non seulement une compression des coûts d'appel d'API, mais surtout l'intégration complète des données, du modèle et de la chaîne d'inférence sous son propre contrôle, obtenant une flexibilité en termes de profondeur de personnalisation et de conformité à la vie privée que les solutions闭源 peinent à offrir.
HappyHorse-1.0 n'ébranlera pas à court terme la position de marché de Seedance 2.0 ou de Kling, mais une fois la cognition établie que les modèles open source peuvent rivaliser avec les闭源, les optimisations de quantification, les微调 (fine-tuning) verticaux et l'accélération de l'inférence seront poursuivies par la communauté à un rythme d'itération dépassant de loin celui des produits闭源.
En cette année du Cheval, ce qui mérite vraiment d'être suivi, ce n'est peut-être pas quel cheval court le plus vite, mais la piste elle-même qui s'élargit.
Cet article provient du compte WeChat officiel "AI价值官" (AI Value Officer), auteur : Xing Ye, éditeur : Mei Qi





