
Auteur | ZeR0 骏达, 智东西
Éditeur | 漠影
LAS VEGAS, 5 janvier (智东西) — À l'instant, Jensen Huang, fondateur et PDG de NVIDIA, a prononcé le premier discours d'ouverture de 2026 lors du Consumer Electronics Show (CES) 2026. Vêtu de son habituelle veste en cuir, Huang Renxun a annoncé 8 lancements majeurs en 1,5 heure, couvrant des puces aux baies de serveurs en passant par la conception réseau, détaillant toute la nouvelle génération de plateformes.
Dans le domaine de l'infrastructure d'IA et de calcul accéléré, NVIDIA a présenté le supercalculateur d'IA NVIDIA Vera Rubin POD, le dispositif à optique co-emballée Ethernet NVIDIA Spectrum-X, la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA, et le NVIDIA DGX SuperPOD basé sur DGX Vera Rubin NVL72.

Le NVIDIA Vera Rubin POD utilise 6 puces conçues sur mesure par NVIDIA, couvrant le CPU, le GPU, la montée en charge (Scale-up), l'extension (Scale-out), le stockage et la capacité de traitement. Toutes les parties sont conçues en synergie pour répondre aux besoins des modèles avancés et réduire les coûts de calcul.
Le CPU Vera utilise une architecture de cœur personnalisée Olympus, le GPU Rubin introduit un moteur Transformer offrant des performances d'inférence NBFP4 allant jusqu'à 50 PFLOPS, une bande passante NVLink par GPU allant jusqu'à 3,6 To/s, et prend en charge la troisième génération de calcul confidentiel universel (premier TEE au niveau du baie), réalisant un environnement d'exécution de confiance complet entre les domaines CPU et GPU.

Ces puces ont déjà fait l'objet de retours de silicium (tape-out), NVIDIA a validé l'ensemble du système NVIDIA Vera Rubin NVL72, et les partenaires ont commencé à exécuter leurs modèles et algorithmes d'IA intégrés en interne. L'ensemble de l'écosystème se prépare au déploiement de Vera Rubin.
Parmi les autres annonces, le dispositif à optique co-emballée Ethernet NVIDIA Spectrum-X optimise considérablement l'efficacité énergétique et le temps de fonctionnement des applications ; la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA redéfinit la pile de stockage pour réduire les calculs redondants et améliorer l'efficacité de l'inférence ; le NVIDIA DGX SuperPOD basé sur DGX Vera Rubin NVL72 réduit le coût par token des grands modèles MoE d'un facteur 10.

Concernant les modèles ouverts, NVIDIA a annoncé l'extension de sa gamme de modèles open source, avec de nouveaux modèles, ensembles de données et bibliothèques, y compris l'ajout d'un modèle Agentic RAG, d'un modèle de sécurité et d'un modèle vocal à la série de modèles open source NVIDIA Nemotron, ainsi que le lancement de nouveaux modèles ouverts pour tous les types de robots. Cependant, Huang Renxun n'a pas détaillé ces points dans son discours.
Dans le domaine de l'IA physique, le moment ChatGPT de l'IA physique est arrivé. La pile technologique complète de NVIDIA permet à l'écosystème mondial de transformer les industries grâce à la robotique pilotée par l'IA ; la vaste bibliothèque d'outils d'IA de NVIDIA, y compris la nouvelle combinaison de modèles open source Alpamayo, permet à l'industrie mondiale des transports d'atteindre rapidement une conduite de niveau L4 sécurisée ; la plateforme de conduite autonome NVIDIA DRIVE est désormais en production, équipant toutes les nouvelles Mercedes-Benz CLA pour une conduite définie par l'IA de niveau L2++.

01. Nouveau supercalculateur d'IA : 6 puces conçues sur mesure, une puissance de calcul de 3,6 EFLOPS par baie
Jensen Huang estime que l'industrie informatique connaît une refonte complète tous les 10 à 15 ans, mais cette fois, deux transformations de plateforme se produisent simultanément : du CPU au GPU, de la « programmation logicielle » à la « formation logicielle ». Le calcul accéléré et l'IA remodèlent toute la pile informatique. L'industrie du calcul, d'une valeur de 10 000 milliards de dollars au cours de la dernière décennie, subit une modernisation.
Simultanément, la demande en puissance de calcul augmente considérablement. La taille des modèles augmente d'un facteur 10 chaque année, le nombre de tokens utilisés par les modèles pour « penser » augmente d'un facteur 5 chaque année, tandis que le coût par token diminue d'un facteur 10 chaque année.
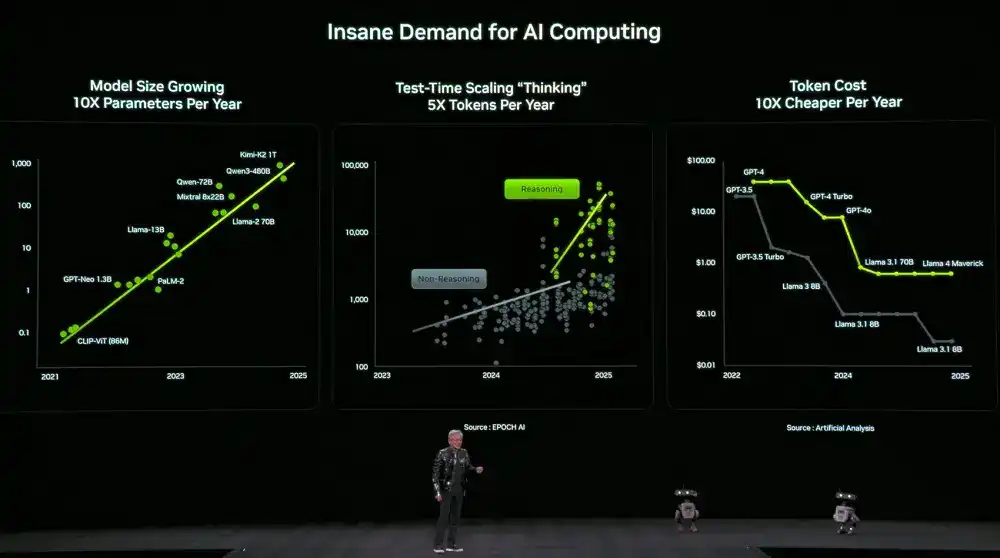
Pour répondre à cette demande, NVIDIA a décidé de publier de nouveaux matériels de calcul chaque année. Huang Renxun a révélé que Vera Rubin est déjà entièrement en production.
Le nouveau supercalculateur d'IA NVIDIA Vera Rubin POD utilise 6 puces conçues sur mesure : le CPU Vera, le GPU Rubin, le commutateur NVLink 6, la carte réseau intelligente ConnectX-9 (CX9), le DPU BlueField-4, et le CPO Spectrum-X 102.4T.
CPU Vera : Conçu pour le mouvement des données et le traitement des agents, il dispose de 88 cœurs Olympus personnalisés NVIDIA, 176 threads de multithreading spatial NVIDIA, 1,8 To/s de NVLink-C2C prenant en charge une mémoire unifiée CPU:GPU, une mémoire système de 1,5 To (3 fois celle du CPU Grace), une bande passante mémoire LPDDR5X SOCAMM de 1,2 To/s, et prend en charge le calcul confidentiel au niveau du baie, doublant les performances de traitement des données.

GPU Rubin : Introduit un moteur Transformer, avec des performances d'inférence NVFP4 atteignant 50 PFLOPS, soit 5 fois celles du GPU Blackwell, rétrocompatible, améliorant les performances au niveau BF16/FP4 tout en maintenant la précision de l'inférence ; les performances d'entraînement NVFP4 atteignent 35 PFLOPS, soit 3,5 fois celles de Blackwell.
Rubin est également la première plateforme à prendre en charge HBM4, avec une bande passante HBM4 de 22 To/s, 2,8 fois celle de la génération précédente, capable de fournir les performances nécessaires pour les modèles MoE exigeants et les charges de travail d'IA.

Commutateur NVLink 6 : Le débit par lane augmente à 400 Gbps, utilisant la technologie SerDes pour une transmission de signal à haute vitesse ; chaque GPU peut atteindre une bande passante de communication interconnectée complète de 3,6 To/s, soit le double de la génération précédente, avec une bande passante totale de 28,8 To/s, des performances de calcul in-network en précision FP8 atteignant 14,4 TFLOPS, et prend en charge le refroidissement liquide à 100%.

NVIDIA ConnectX-9 SuperNIC : Fournit 1,6 Tb/s de bande passante par GPU, optimisé pour l'IA à grande échelle, avec un chemin de données entièrement logiciel, programmable et accéléré.

NVIDIA BlueField-4 : DPU 800 Gbps, utilisé pour les cartes réseau intelligentes et les processeurs de stockage, équipé d'un CPU Grace 64 cœurs, combiné avec la ConnectX-9 SuperNIC, pour décharger les tâches de calcul liées au réseau et au stockage, tout en améliorant les capacités de sécurité réseau. Les performances de calcul sont 6 fois supérieures à la génération précédente, la bande passante mémoire est multipliée par 3, et la vitesse d'accès du GPU au stockage de données est doublée.

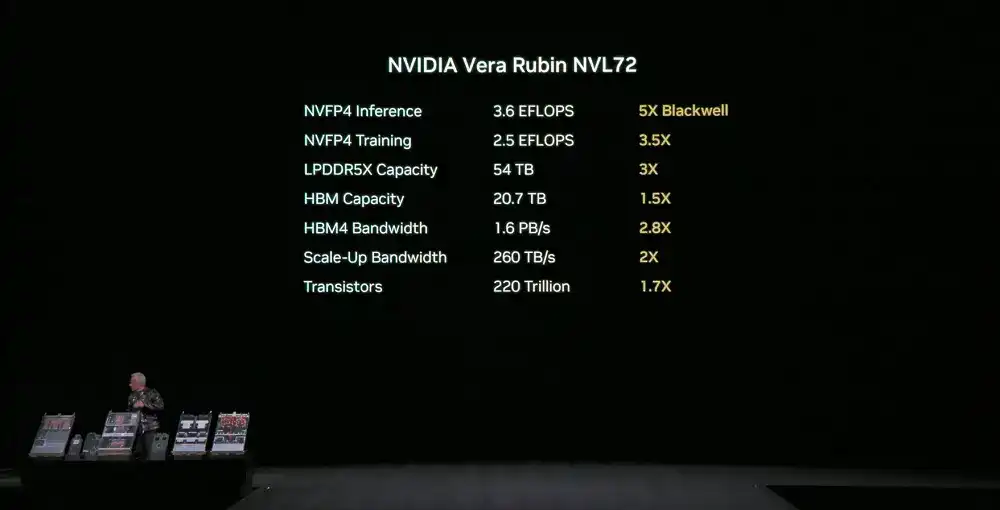
NVIDIA Vera Rubin NVL72 : Au niveau du système, intègre tous ces composants en un système de traitement à baie unique, contenant 2 billions de transistors, avec des performances d'inférence NVFP4 atteignant 3,6 EFLOPS et des performances d'entraînement NVFP4 atteignant 2,5 EFLOPS.
Ce système a une capacité mémoire LPDDR5X de 54 To, 2,5 fois celle de la génération précédente ; une mémoire HBM4 totale de 20,7 To, 1,5 fois celle de la génération précédente ; une bande passante HBM4 de 1,6 Po/s, 2,8 fois celle de la génération précédente ; une bande passante d'extension verticale totale atteignant 260 To/s, dépassant l'échelle de la bande passante Internet mondiale totale.
Ce système est basé sur la conception de baie MGX de troisième génération, le plateau de calcul utilise une conception modulaire, sans hôte, sans câble, sans ventilateur, rendant l'assemblage et la maintenance 18 fois plus rapides que le GB200. Un travail d'assemblage qui prenait 2 heures ne prend maintenant qu'environ 5 minutes, et alors que le système utilisait environ 80% de refroidissement liquide, il utilise maintenant 100% de refroidissement liquide. Un seul système pèse à lui seul 2 tonnes, et avec le liquide de refroidissement, il peut atteindre 2,5 tonnes.

Le plateau de commutateur NVLink permet une maintenance avec zéro temps d'arrêt et une tolérance aux pannes, le baie pouvant fonctionner même lorsqu'un plateau est retiré ou partiellement déployé. Le moteur RAS de deuxième génération permet des contrôles de santé avec zéro temps d'arrêt.
Ces caractéristiques améliorent le temps de fonctionnement et le débit du système, réduisant davantage les coûts d'entraînement et d'inférence, répondant aux exigences de haute fiabilité et de haute maintenabilité des centres de données.
Plus de 80 partenaires MGX sont déjà prêts à supporter le déploiement de Rubin NVL72 dans les réseaux hyperscale.
02. Trois nouveaux produits révolutionnent l'efficacité de l'inférence IA : Nouveau dispositif CPO, nouvelle couche de stockage contextuel, nouveau DGX SuperPOD
Simultanément, NVIDIA a lancé 3 nouveaux produits importants : le dispositif à optique co-emballée Ethernet NVIDIA Spectrum-X, la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA, et le NVIDIA DGX SuperPOD basé sur DGX Vera Rubin NVL72.
1. Dispositif à optique co-emballée Ethernet NVIDIA Spectrum-X
Le dispositif à optique co-emballée Ethernet NVIDIA Spectrum-X est basé sur l'architecture Spectrum-X, utilisant une conception à 2 puces, avec des SerDes 200 Gbps, chaque ASIC pouvant fournir une bande passante de 102,4 Tb/s.
Cette plateforme de commutation comprend un système haute densité à 512 ports et un système compact à 128 ports, chaque port ayant un débit de 800 Gb/s.

Le système de commutation CPO (Co-Packaged Optics) permet une amélioration de l'efficacité énergétique par 5, une fiabilité multipliée par 10, et un temps de fonctionnement des applications multiplié par 5.
Cela signifie que plus de tokens peuvent être traités chaque jour, réduisant ainsi le coût total de possession (TCO) du centre de données.
2. Plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA
La plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA est une infrastructure de stockage IA native au niveau POD, utilisée pour stocker le Cache KV, basée sur BlueField-4 et l'accélération Ethernet Spectrum-X, étroitement couplée avec NVIDIA Dynamo et NVLink, réalisant une planification contextuelle collaborative entre la mémoire, le stockage et le réseau.
Cette plateforme traite le contexte comme un type de données de premier ordre, permettant des performances d'inférence multipliées par 5 et une efficacité énergétique 5 fois meilleure.

Ceci est crucial pour améliorer les applications à contexte long comme les conversations multi-tours, le RAG, l'inférence multi-étapes Agentic, ces charges de travail dépendant fortement de la capacité du contexte à être stocké, réutilisé et partagé efficacement dans l'ensemble du système.
L'IA évolue des chatbots vers l'IA Agentic (agents intelligents), qui raisonnent, appellent des outils et maintiennent un état à long terme. La fenêtre contextuelle s'est étendue à des millions de tokens. Ce contexte est sauvegardé dans le Cache KV, et le recalculer à chaque étape gaspillerait du temps GPU et entraînerait une latence énorme, d'où la nécessité de le stocker.
Mais la mémoire GPU, bien que rapide, est rare, et le stockage réseau traditionnel est trop inefficace pour le contexte à court terme. Le goulot d'étranglement de l'inférence IA passe du calcul au stockage contextuel. Ainsi, une nouvelle couche mémoire, située entre le GPU et le stockage, optimisée pour l'inférence, est nécessaire.

Cette couche n'est plus une rustine ajoutée après coup, mais doit être conçue en synergie avec le stockage réseau pour déplacer les données contextuelles avec une surcharge minimale.
En tant que nouveau niveau de stockage, la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA n'existe pas directement dans le système hôte, mais est connectée via BlueField-4 en dehors des dispositifs de calcul. Son avantage clé est de pouvoir étendre plus efficacement la taille du pool de stockage, évitant ainsi le recalcul redondant du Cache KV.
NVIDIA collabore étroitement avec des partenaires de stockage pour intégrer la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA dans la plateforme Rubin, permettant aux clients de la déployer comme partie intégrante d'une infrastructure IA complète.
3. NVIDIA DGX SuperPOD construit sur Vera Rubin
Au niveau système, le NVIDIA DGX SuperPOD sert de plan directeur pour les déploiements d'usines IA à grande échelle, utilisant 8 systèmes DGX Vera Rubin NVL72, avec le réseau d'extension verticale NVLink 6, le réseau d'extension horizontale Ethernet Spectrum-X, intégrant la plateforme de stockage mémoire contextuelle pour l'inférence NVIDIA, et validé par l'ingénierie.
L'ensemble du système est géré par le logiciel NVIDIA Mission Control, pour une efficacité maximale. Les clients peuvent le déployer comme une plateforme clé en main, accomplissant les tâches d'entraînement et d'inférence avec moins de GPU.
Grâce à la conception synergique extrême au niveau des 6 puces, des plateaux, des baies, des Pod, des centres de données et des logiciels, la plateforme Rubin a réalisé une baisse significative des coûts d'entraînement et d'inférence. Par rapport à la génération précédente Blackwell, pour entraîner un modèle MoE de même taille, seulement 1/4 du nombre de GPU est nécessaire ; à latence égale, le coût par token des grands modèles MoE est réduit d'un facteur 10.
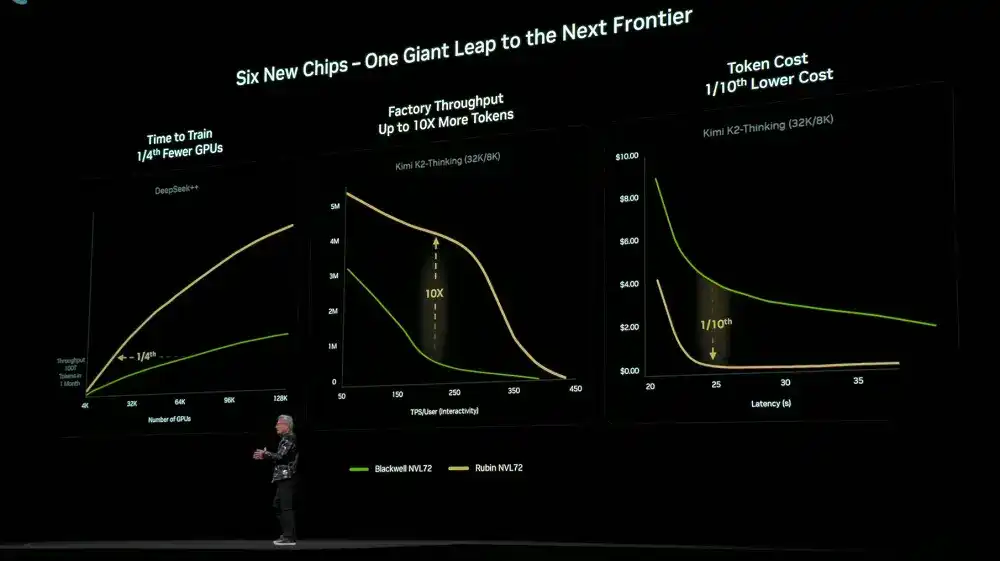
Le NVIDIA DGX SuperPOD utilisant le système DGX Rubin NVL8 a également été annoncé.
Avec l'architecture Vera Rubin, NVIDIA, avec ses partenaires et clients, construit les systèmes d'IA les plus grands, les plus avancés et au coût le plus bas au monde, accélérant l'adoption grand public de l'IA.

L'infrastructure Rubin sera disponible au second semestre de cette année via les CSP et les intégrateurs de systèmes, Microsoft étant parmi les premiers déployeurs.
03. L'univers des modèles ouverts s'étend : Nouveaux modèles, données, contributeur majeur à l'écosystème open source
Au niveau des logiciels et des modèles, NVIDIA continue d'intensifier ses investissements dans l'open source.
Les principales plateformes de développement comme OpenRouter montrent qu'au cours de l'année écoulée, l'utilisation des modèles d'IA a été multipliée par 20, environ 1/4 des tokens provenant de modèles open source.
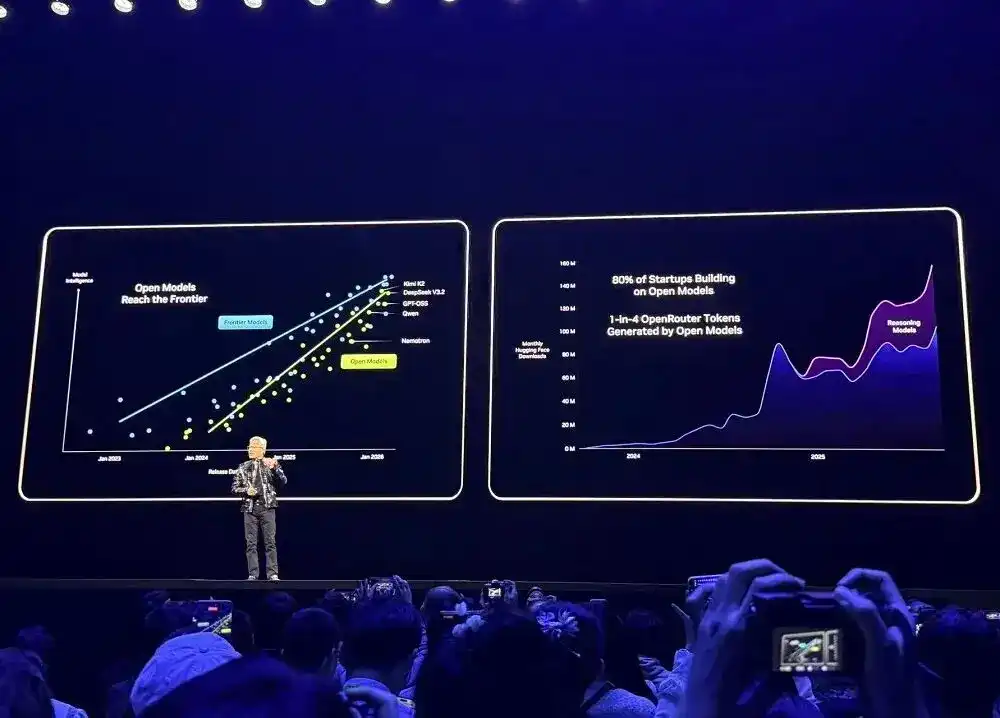
En 2025, NVIDIA a été le plus grand contributeur de modèles open source, de données et de recettes sur Hugging Face, publiant 650 modèles open source et 250 ensembles de données open source.

Les modèles open source de NVIDIA se classent en tête de nombreux classements. Les développeurs peuvent non seulement utiliser ces modèles open source, mais aussi apprendre d'eux, effectuer un apprentissage continu, étendre les ensembles de données et utiliser des outils open source et des techniques documentées pour construire des systèmes d'IA.

Inspiré par Perplexity, Huang Renxun observe que les Agents devraient être multi-modèles, multi-cloud et hybrides, ce qui est également l'architecture fondamentale des systèmes d'IA Agentic, adoptée par presque toutes les startups.
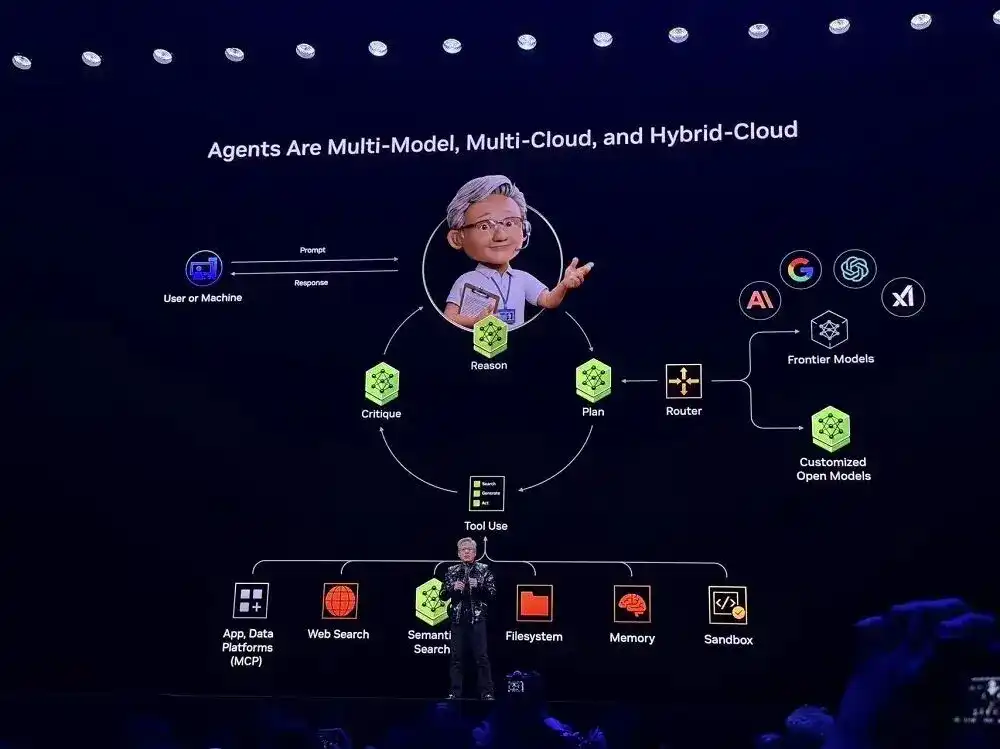
Grâce aux modèles et outils open source fournis par NVIDIA, les développeurs peuvent maintenant personnaliser les systèmes d'IA et utiliser les capacités de modèles les plus avancées. NVIDIA a intégré ce cadre sous forme de « plans directeurs » (blueprints) dans des plateformes SaaS. Les utilisateurs peuvent ainsi déployer rapidement à l'aide de ces plans directeurs.
Dans la démonstration en direct, ce système peut automatiquement déterminer, en fonction de l'intention de l'utilisateur, si une tâche doit être traitée par un modèle privé local ou un modèle de pointe cloud, peut également appeler des outils externes (comme une API email, une interface de contrôle robotique, un service calendrier, etc.), et réaliser une fusion multimodale, traitant de manière unifiée des informations textuelles, vocales, visuelles, des signaux de capteurs robotiques, etc.
Ces capacités complexes étaient absolument inimaginables par le passé, mais sont maintenant devenues banales. Des capacités similaires sont disponibles sur des plateformes d'entreprise comme ServiceNow, Snowflake, etc.
04. Modèle open source Alpha-Mayo, pour faire "penser" les voitures autonomes
NVIDIA croit que l'IA physique et la robotique finiront par devenir le plus grand segment de l'électronique grand public au monde. Tout ce qui peut bouger finira par être entièrement autonome, piloté par l'IA physique.
L'IA a traversé les phases de l'IA perceptive, de l'IA générative, de l'IA Agentic, et entre maintenant dans l'ère de l'IA physique, où l'intelligence entre dans le monde réel. Ces modèles peuvent comprendre les lois physiques et générer des actions directement à partir de la perception du monde physique.
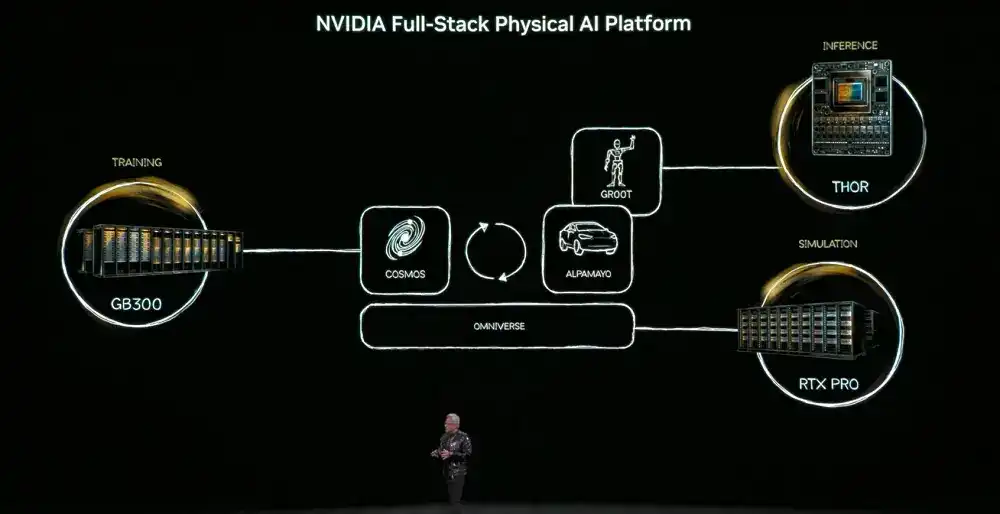
Mais pour atteindre cet objectif, l'IA physique doit apprendre le bon sens du monde — la permanence de l'objet, la gravité, la friction. L'acquisition de ces capacités dépendra de trois ordinateurs : l'ordinateur d'entraînement (DGX) pour créer les modèles d'IA, l'ordinateur d'inférence (puce embarquée robotique/voiture) pour l'exécution en temps réel, et l'ordinateur de simulation (Omniverse) pour générer des données synthétiques et valider la logique physique.
Et le modèle central est le modèle fondamental du monde Cosmos, qui aligne le langage, l'image, la 3D et les lois physiques, soutenant la chaîne complète de génération de données d'entraînement à partir de la simulation.
L'IA physique apparaîtra dans trois types d'entités : les bâtiments (comme les usines, les entrepôts), les robots, les voitures autonomes.
Huang Renxun estime que la conduite autonome sera le premier cas d'utilisation à grande échelle de l'IA physique. De tels systèmes doivent comprendre le monde réel, prendre des décisions et exécuter des actions, avec des exigences extrêmement élevées en matière de sécurité, de simulation et de données.
Pour cela, NVIDIA lance Alpha-Mayo, un système complet composé de modèles open source, d'outils de simulation et d'ensembles de données d'IA physique, pour accélérer le développement d'une IA physique sûre et basée sur le raisonnement.
Sa combinaison de produits fournit les modules de base aux constructeurs automobiles mondiaux, fournisseurs, startups et chercheurs pour construire des systèmes de conduite autonome de niveau L4.

Alpha-Mayo est le premier modèle qui fait véritablement "penser" une voiture autonome, et ce modèle est open source. Il décompose les problèmes en étapes, raisonne sur toutes les possibilités et choisit le chemin le plus sûr.

Ce modèle de tâche-action raisonné permet au système de conduite autonome de résoudre des scénarios complexes de bord qu'il n'a jamais rencontrés auparavant, comme un feu de circulation en panne à une intersection très fréquentée.
Alpha-Mayo possède 10 milliards de paramètres, une taille suffisante pour traiter les tâches de conduite autonome, tout en étant suffisamment léger pour fonctionner sur les stations de travail conçues pour les chercheurs en conduite autonome.
Il peut recevoir des entrées texte, des caméras à 360°, l'état historique du véhicule et la navigation, et produire une trajectoire de conduite et un processus de raisonnement, permettant aux passagers de comprendre pourquoi le véhicule a pris une certaine action.
Dans la bande-annonce diffusée en direct, pilotée par Alpha-Mayo, la voiture autonome peut effectuer des manœuvres comme éviter un piéton, anticiper un véhicule tournant à gauche et changer de voie pour l'éviter, sans intervention.

Huang Renxun a déclaré que la Mercedes-Benz CLA équipée d'Alpha-Mayo est déjà en production et vient d'être classée par le NCAP comme la voiture la plus sûre au monde. Chaque ligne de code, puce et système est certifiée pour la sécurité. Le système sera lancé sur le marché américain et proposera des capacités de conduite encore plus avancées plus tard cette année, incluant la conduite mains libres sur autoroute et la conduite autonome de bout en bout en environnement urbain.

NVIDIA a également publié une partie des ensembles de données utilisés pour entraîner Alpha-Mayo, et le framework de simulation d'évaluation de modèles d'inférence open source Alpha-Sim. Les développeurs peuvent fine-tuner Alpha-Mayo avec leurs propres données, ou utiliser Cosmos pour générer des données synthétiques, et entraîner et tester des applications de conduite autonome sur une combinaison de données réelles et synthétiques. De plus, NVIDIA a annoncé que la plateforme NVIDIA DRIVE est maintenant en production.
NVIDIA a annoncé que des leaders mondiaux de la robotique comme Boston Dynamics, Franka Robotics, Surgical (robot chirurgical), LG Electronics, NEURA, XRLabs, et 智元机器人 (Agibot) construisent tous sur NVIDIA Isaac et GR00T.

Huang Renxun a également officialisé la nouvelle collaboration avec Siemens. Siemens intègre CUDA-X de NVIDIA, les modèles d'IA et Omniverse dans sa suite d'outils et de plateformes EDA, CAE et de jumeaux numériques. L'IA physique sera largement utilisée dans le flux complet, de la conception et la simulation à la production manufacturière et aux opérations.
05. Conclusion : Embrasser l'open source d'une main, rendre le système matériel indispensable de l'autre
Alors que le centre de gravité de l'infrastructure IA passe de l'entraînement à l'inférence à grande échelle, la concurrence des plateformes a évolué de la puissance de calcul ponctuelle à l'ingénierie système couvrant les puces, les baies, le réseau et les logiciels, l'objectif étant de fournir le plus grand débit d'inférence au TCO le plus bas. L'IA entre dans une nouvelle phase de "fonctionnement en usine".
NVIDIA accorde une grande importance à la conception au niveau système. Rubin améliore simultanément les performances et l'économie à la fois pour l'entraînement et l'inférence, et peut servir de remplacement plug-and-play pour Blackwell, permettant une transition transparente depuis Blackwell.
En termes de positionnement de plateforme, NVIDIA considère toujours l'entraînement comme crucial, car seule une formation rapide des modèles les plus avancés profite réellement à la plateforme d'inférence, d'où l'introduction de l'entraînement NVFP4 dans le GPU Rubin, améliorant encore les performances et réduisant le TCO.
Simultanément, ce géant du calcul IA continue de renforcer considérablement les capacités de communication réseau sur les architectures d'extension verticale et horizontale, et considère le contexte comme un goulot d'étranglement clé, réalisant une conception collaborative du stockage, du réseau et du calcul.
NVIDIA, tout en adoptant massivement l'open source, rend le matériel, l'interconnexion et la conception système de plus en plus "indispensables". Cette boucle stratégique consistant à élargir continuellement la demande, à stimuler la consommation de tokens, à pousser la mise à l'échelle de l'inférence et à fournir une infrastructure rentable, construit pour NVIDIA une barrière défensive de plus en plus impénétrable.






