DeepSeek V4 est enfin en ligne. C’est un moment attendu depuis près de cinq mois. Le modèle principal MoE à 1T de paramètres + la version Flash à 285B de paramètres, la version Pro complète à 1,6T suit de près, entièrement open source sur GitHub, sous licence Apache 2.0, avec les poids et les codes de déploiement publiés simultanément.
Dès la sortie du modèle, le marché des capitaux a réagi de trois manières, indépendantes mais interconnectées, pour donner sa réponse.
Les différentes réactions du marché des capitaux
Du côté de la chaîne de calcul sur le marché A, les cours ont presque tous bondi. Cambricon a enregistré 11 séances consécutives de hausse, avec une progression de 3,7 % sur une journée, et une hausse cumulative mensuelle dépassant 60 %. Hygon Information a touché la limite haussière de 10 % en cours de séance, clôturant à +8,4 %. SMIC A +4,91 %, HK +8,81 %. Huahong HK a grimpé jusqu’à +18 %, clôturant à +12 %. L’ETF科创芯片国泰 a attiré 2,4 milliards de yuans en une seule journée, atteignant un plus haut historique.
Du côté des entreprises de grands modèles sur le marché HK, c’est une autre couleur. Zhipu (02513.HK) a chuté de 8,07 %, avec un taux de vente à découvert de 9,9 %. MiniMax (00100.HK) a chuté de 7,40 %, avec un taux de vente à découvert grimpant à 22,87 %. Ce dernier est la donnée de vente à découvert la plus élevée sur une journée pour le secteur de l’IA à HK au cours des trois derniers mois. Ces deux entreprises sont représentatives de la vague d’introductions en bourse de l’IA à HK prévue pour la seconde moitié de 2025, leur argument de compétitivité dans le prospectus d’IPO étant le même : « grand modèle de base auto-développé ».
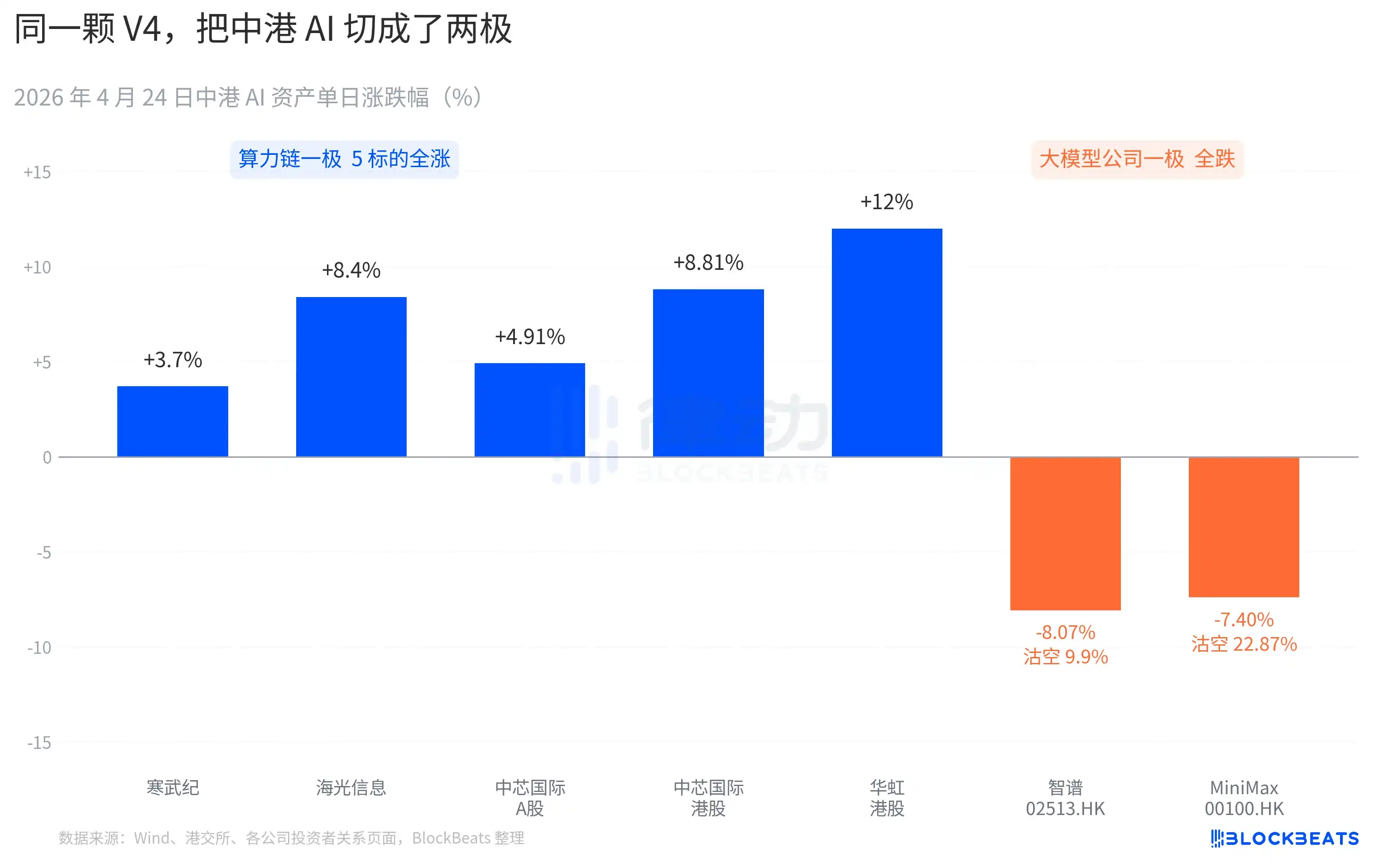
La réaction de l’autre côté du Pacifique est tout aussi concrète. Nvidia a ouvert en baisse de 1,8 % hier soir, tombant jusqu’à -2,6 % en cours de séance, clôturant stable sur la journée. Le commentaire marché de Bloomberg a comparé cette consolidation au « moment DeepSeek » du V3 du 27 janvier. La différence est qu’en janvier, il s’agissait d’une vente de panique, avec une évaporation de 600 milliards de dollars de valorisation en une journée. Cette fois, c’est plutôt une réévaluation, d’ampleur modérée mais de direction claire. Les comptes-rendus de recherche des institutions acheteuses contiennent une nouvelle formulation : « La demande d’inférence IA en Chine commence à se découpler de la demande d’inférence IA en Amérique du Nord ».
En superposant ces trois tableaux de marché, on obtient le premier verdict écrit par le marché dans les 24 heures suivant le déploiement de V4. Après la victoire de l’open source, l’argent commence à choisir son camp, ce qui peut être valorisé n’est plus le modèle lui-même, mais sur quelle carte il tourne, dans quelle chaîne d’approvisionnement il est intégré.
11 nouveaux modèles en 30 jours, V4 ajoute de l’huile sur le feu du camp open source
La fenêtre de publication de V4 est en elle-même une partie de la raison pour laquelle cette réaction a été amplifiée.
En regardant les 30 derniers jours. Entre le 26 mars et le 24 avril, au moins 11 grands modèles d’influence significative ont été publiés ou ont connu une mise à jour majeure dans le monde, la liste couvrant presque tous les acteurs principaux. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonlight Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, et enfin DeepSeek V4 publié à l’aube du 23 avril.
En moyenne, un nouveau modèle est sorti tous les 2,7 jours. C’est une vitesse que même les gestionnaires de fonds ont du mal à suivre. Mais en parcourant les graphiques K线 des actifs IA en Chine et à HK sur ces 30 jours, un seul nom a laissé une trace durable sur le marché. Le GPT-5.5 du 8 avril a entraîné une hausse de 4,2 % de Nvidia en une journée, culminant en une séance. Puis le DeepSeek V4 des 23-24 avril, qui a provoqué une hausse continue de la chaîne de calcul sino-hongkongaise.
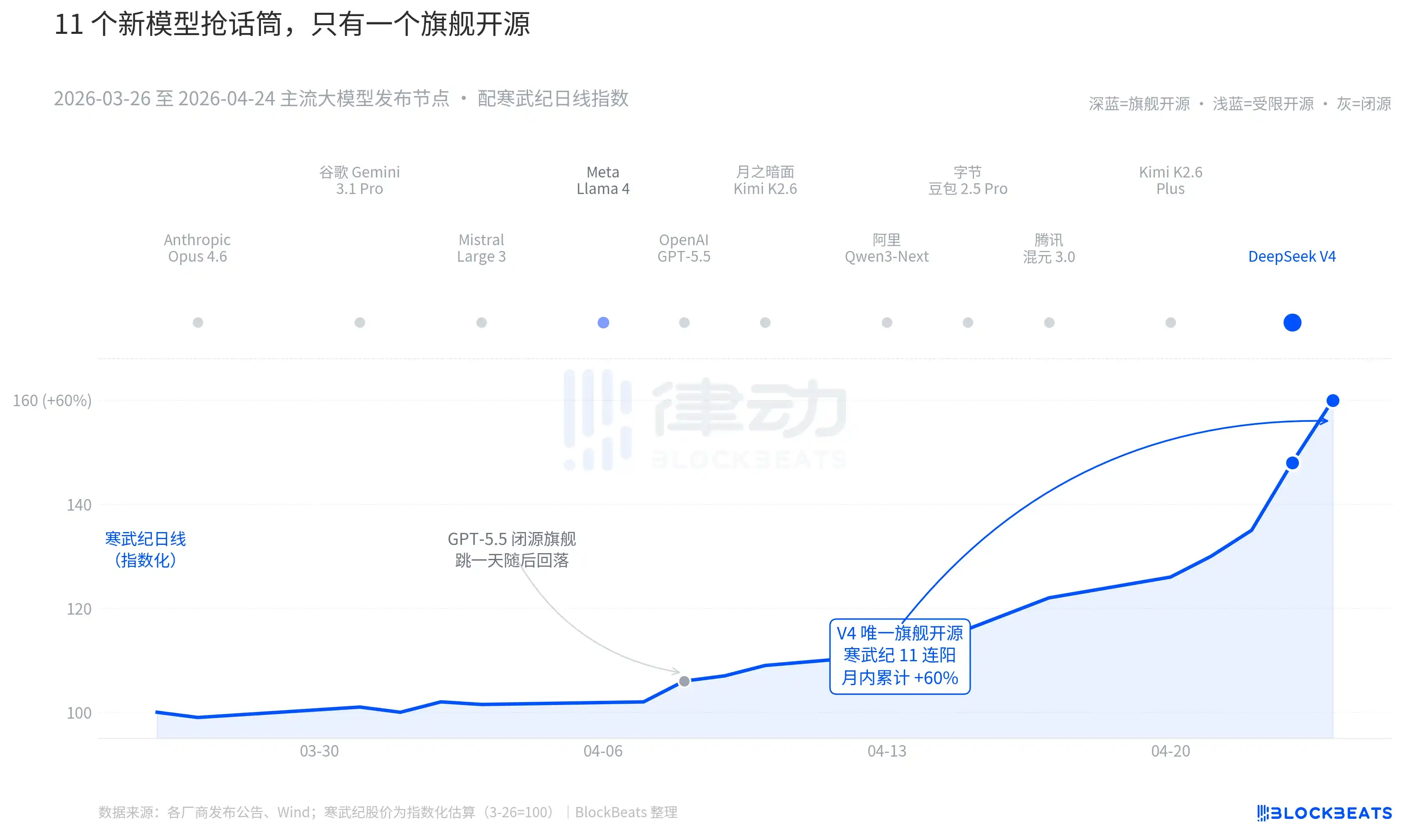
La différence ne réside pas dans les capacités des modèles eux-mêmes. L’écart entre ces 11 modèles dans le classement LMArena, dans la plupart des cas, ne dépasse pas 50 points, se situant dans une bande étroite de « même niveau ». La différence vient de la superposition de deux choses.
La première est l’open source. Parmi les 10 premiers modèles, seul Llama 4 est open source, mais le contrat de poids de Llama 4 comporte une longue liste de restrictions commerciales, la communauté des développeurs occidentaux l’a accueilli froidement, OpenRouter est tombé hors du top 10 dès le troisième jour. Le contrat de V4 est Apache 2.0, sans seuil d’accès aux poids, sans restriction commerciale, avec le code d’inférence publié simultanément. C’est le premier modèle open source phare des six derniers mois à exercer une pression simultanée sur les trois dimensions que sont les performances, le prix et l’ouverture, sur le camp closed source.
La seconde est le timing. Dans un contexte où le camp closed source enchaîne les annonces majeures, le récit open source est constamment mis sous pression. Opus 4.6 a porté SWE-Bench pour les tâches de code à un nouveau niveau, GPT-5.5 a fixé le prix par million de tokens à un point d’ancrage bas de 1,25 dollar. L’open source peut-il rattraper le closed source, ce débat dure depuis deux ans dans la Silicon Valley. V4, avec un modèle phare open source dont l’estimation d’utilisation mensuelle atteint 90 millions, a mis ce débat en pause.
Selon les propos d’un grand gestionnaire de fonds chinois lors d’une roadshow, « Avant V4, nous avions laissé une décote pour la valorisation des grands modèles open source, après V4, cette décote commence à se resser dans l’autre sens. »
DeepSeek a changé la table des prix de la chaîne d’approvisionnement en calcul
Le communiqué de V4 contient une phrase qui n’avait jamais figuré auparavant dans aucun document officiel de grand modèle chinois : « Day 0 adaptation full stack pour le Cambricon Siyuan 590 et le Huawei Ascend 950PR, code de déploiement open source simultané. » Le poids de cette phrase ne devient clair qu’en reliant trois lignes souterraines qui se sont déployées en parallèle au cours des 12 derniers mois. Ces trois lignes concernent respectivement le matériel, le logiciel et la réaction de la Silicon Valley.
La première ligne souterraine est du côté des puces. Le Huawei Ascend 950PR a été mis en production en masse en décembre 2025, avec une puissance de calcul FP4 de 1,56 PFLOPS, une capacité HBM de 112 Go, c’est la première fois qu’une puce IA chinoise rivalise avec la série B de Nvidia sur les spécifications techniques. Dans des tâches d’inférence MoE à 1T de paramètres comme V4, le débit par carte est amélioré de 2,87 fois par rapport au H20. La stack logicielle CANN 8.0 associée optimise le framework d’inférence LLM jusqu’au niveau des opérateurs. Les benchmarks publics de DeepSeek montrent que la latence d’inférence de bout en bout de V4 sur un super nœud Ascend (8 cartes 950PR) est inférieure de 35 % à celle d’un cluster H100 de taille équivalente. Les données du Cambricon Siyuan 590 sont encore plus agressives, avec une puissance de calcul FP8 par puce comparable au H100, pour un prix inférieur de moitié.
La deuxième ligne souterraine est du côté logiciel. vLLM a fusionné le backend MLU de Cambricon sur la branche principale le 22 avril, c’est la première fois qu’un framework d’inférence open source prend en charge nativement des GPU chinois non-Nvidia. Le DCU de Hygon Information emprunte une autre voie via l’écosystème ROCm, mais peut exécuter complètement la couche de routage MoE de V4. Cela signifie que le déploiement de V4 n’est plus « fonctionne uniquement sur telle carte chinoise », mais « peut être choisi parmi plusieurs cartes chinoises ». La dépendance de l’écosystème à un fournisseur unique est brisée, c’est un point d’inflexion crucial pour la production.
La troisième ligne souterraine vient de la Silicon Valley. Le 15 avril, Jensen Huang, lors de la conférence téléphonique de TSMC, a été interrogé par un analyste sur les progrès du calcul made in China, ses propos étaient froids et précis : « S’ils parviennent vraiment à libérer les LLM de CUDA, ce sera une catastrophe (a disaster) pour nous ». Neuf jours plus tard, DeepSeek a donné la réponse avec une annonce Day 0.
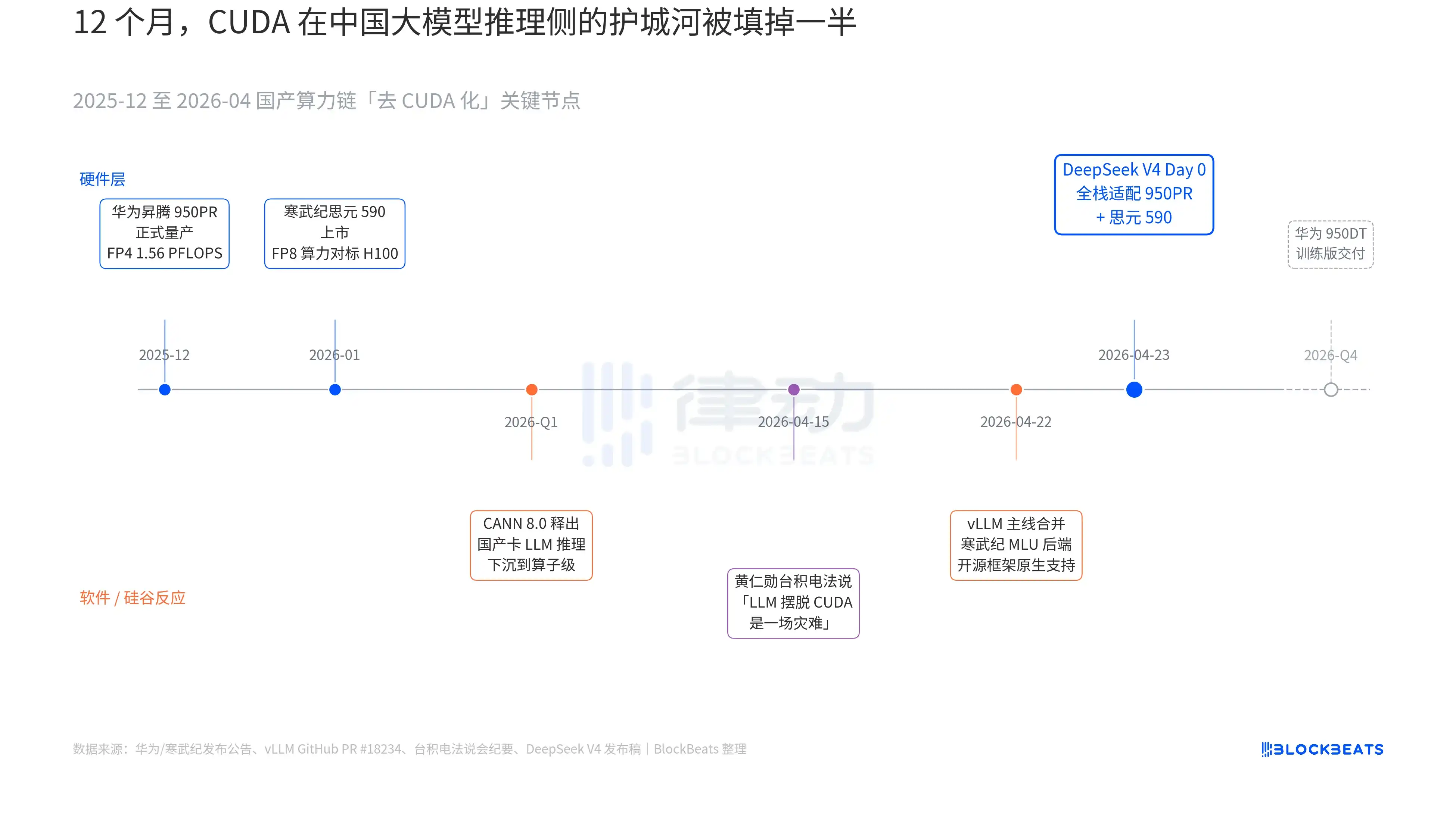
Les quatre caractères « remplacement domestique » (国产替代) ont été tellement galvaudés au cours des trois dernières années qu’ils ont perdu leur sens. Mais après la matinée du 24 avril, cette chose a pour la première fois des données concrètes pouvant être valorisées par le marché des capitaux. Débit par carte, latence d’inférence de bout en bout, coût d’inférence, code de déploiement utilisable commercialement, ont silencieusement poussé cette longue guerre de communication au seuil de la production.
La logique derrière les 11 séances haussières consécutives de Cambricon se cache ici. Ce n’est plus une « action concept GPU chinois », mais un « fournisseur d’infrastructure d’inférence pour DeepSeek V4 ». La même logique explique la hausse de 12 % de Huahong HK, qui foundry le procédé 7nm équivalent du 950PR. Chaque token V4 exécuté sur un Ascend chinois signifie qu’une partie de la capacité de production qui devait aller vers Nvidia et TSMC est désormais retenue dans le delta de la Rivière des Perles.
Et la prochaine étape est déjà préparée. Dans la feuille de route de Huawei, le 950DT (version entraînement) est prévu pour le quatrième trimestre 2026, l’objectif correspondant étant « l’entraînement full stack de V5 ou d’un modèle de calibre équivalent sur un cluster de 10 000 cartes ». Si cette voie fonctionne, le fossé de CUDA côté entraînement des grands modèles en Chine passerait de « nécessaire » à « optionnel ».







