【Insight】Too crazy! The AI evolution data recently measured by Meta and METR perfectly aligns with the "Density Law" proposed by a Chinese team two years ago. Silicon Valley suddenly realized that Chinese researchers have been leading this path for two years!
Three of the world's most serious AI research institutions collectively collided in the past week!
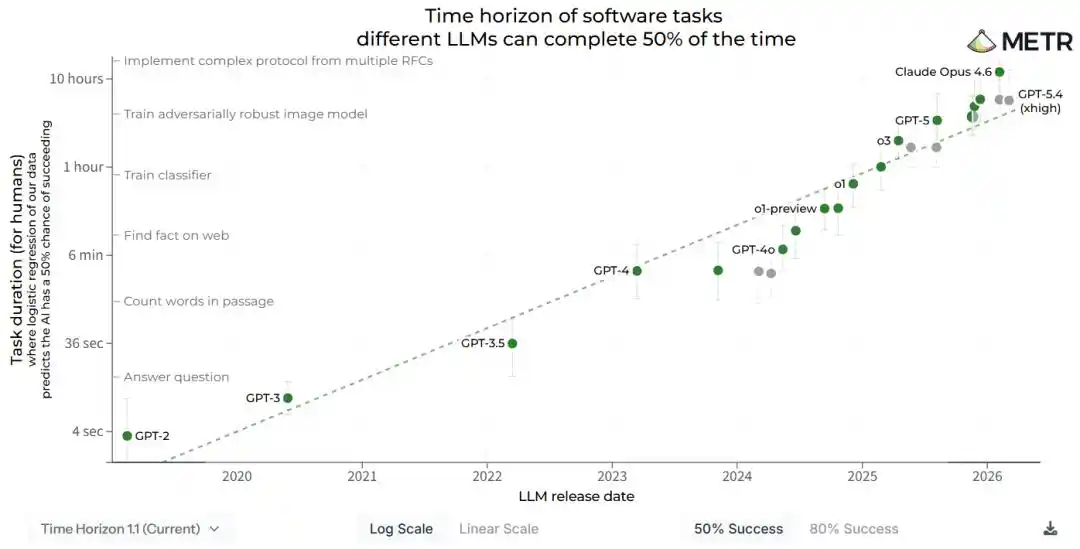
On April 3, the American research institution METR quietly updated a technical report, with the core conclusion compressed into one sentence.
AI capabilities double every 88.6 days.
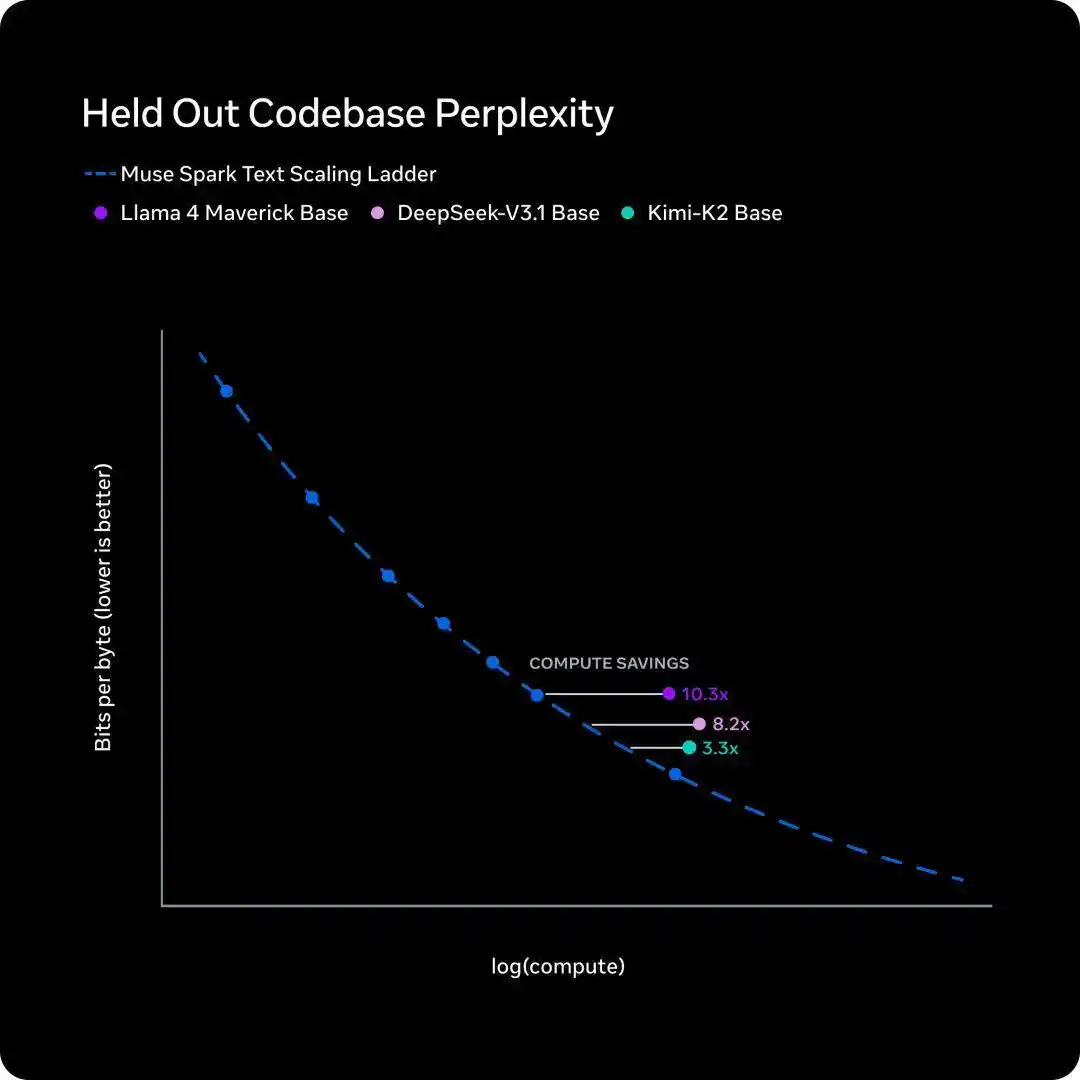
Five days later, on April 8, Meta's Super Intelligence Lab released a new model, Muse Spark, and disclosed an internal training efficiency curve called the scaling ladder, with the conclusion also being one sentence.
To catch up with the performance of Llama 4 Maverick from a year ago, the new model requires less than one-tenth of the training compute.
One measured task duration, the other measured training compute. The two institutions had no interaction, and their research methods had no overlap.
But when the two curves were converted to the same coordinate system, their slopes were almost identical.
At this point, things were already bizarre enough.
Even more bizarre is that this curve was completely drawn by a Chinese team two years ago and even published in a Nature sub-journal.
It's called the Density Law.

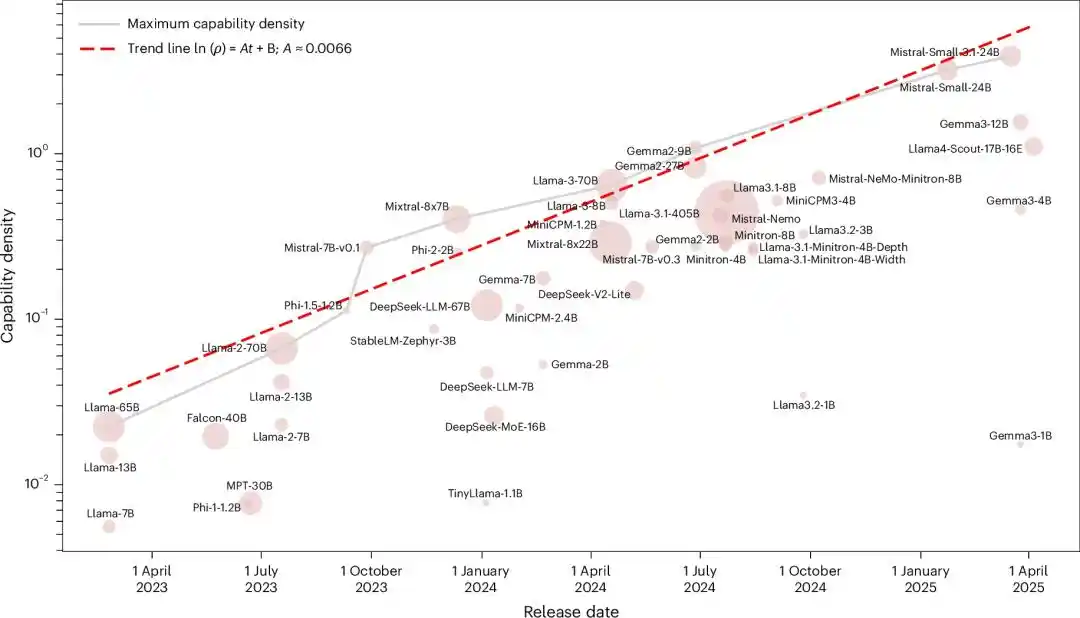
Two Years Ago, Someone Drew This Line in Advance
This concept first appeared in a paper called "Densing Law of LLMs".
The authors were a joint team from ModelBest and Tsinghua University, led by Professors Sun Maosong and Liu Zhiyuan, with doctoral student Xiao Chaojun as the first author.
The paper was posted on arXiv in December 2024 and accepted by Nature Machine Intelligence in November 2025.

Paper address: https://arxiv.org/abs/2412.04315

Paper address: https://www.nature.com/articles/s42256-025-01137-0
The core assertion of the paper is just one sentence.
Model intelligence density increases exponentially over time, and the number of parameters required to reach a specific intelligence level halves every 3.5 months.
Back in late 2024, this sounded a bit radical.
At that time, the entire industry was worshipping the scaling law. OpenAI was scaling models, Anthropic was scaling models, Meta was scaling models.
Everyone thought that bigger parameters meant stronger intelligence, and burning GPUs to the extreme was the right way.
But the research team didn't see it that way.
They put all influential open-source foundation models at the time, from Llama-1 all the way to Gemma-2 and MiniCPM-3, a total of 51 models, into the same ruler to measure.
After running five major benchmarks, the result was an almost perfect exponential relationship, with an R² of 0.934.
Considering that LLM evaluation is easily contaminated by data pollution, they retested using a newly constructed contamination-filtered dataset, MMLU-CF. R²=0.953.
Both fits achieved an R² close to 1. Statistically, this is almost impossible to be a coincidence.
In other words, every mainstream open-source model released in these two years, regardless of which team it came from or what architecture it used, fell on the same exponential line of "doubling every 3.5 months".
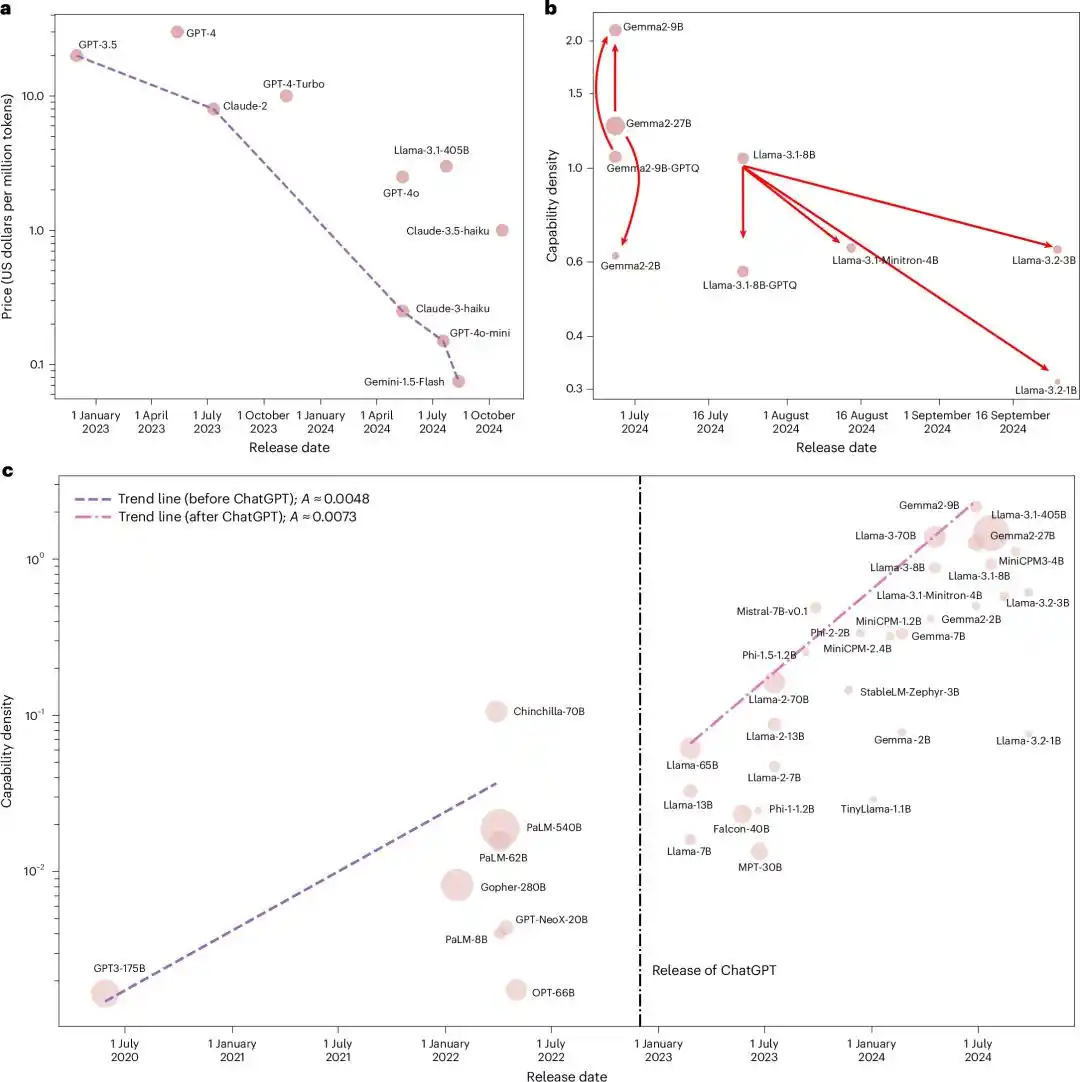
Up to this point, the story was just "a Chinese team proposed a seemingly radical empirical rule".
What truly made this a "moment" was what happened in the next half year.
Three Institutions, Three Methods, One Slope
Laying out the conclusions from ModelBest, Meta, and METR:
- ModelBest's Density Law measures "how many parameters are needed for the same intelligence level". The conclusion is that the parameter requirement halves every 3.5 months.
- Meta's scaling ladder measures "how much training compute is needed for the same intelligence level". The conclusion is that Muse Spark saves an order of magnitude compared to Llama 4 Maverick from a year ago.
- METR's time horizon report measures "how long a task a model can handle". The conclusion is that the task length doubles every 88.6 days.
Three rulers. Three academic institutions. Three research paths with no overlap whatsoever.
But when all the numbers are converted and viewed in the same coordinate system, the slopes of their curves are almost identical.
The most easily overlooked point about this is that the Density Law was the first proposed among these three. It was nearly two years earlier than Meta's scaling ladder and more than a year earlier than METR's complete modeling.
And when Meta drew that scaling ladder in their early April blog post, they probably didn't realize it themselves. The shape of this graph was almost the same line as the curve on a PPT from an academic conference in Beijing in 2024.
What Kind of Observation Deserves to Be Called a "Law"
In the scientific community, there is an unwritten standard to judge whether an empirical observation qualifies as a "law".
It's not about how beautiful the data is, but whether it holds true across multiple independent measurement systems.
The reason Moore's Law is a law is because the semiconductor industry has verified it over decades from three completely different dimensions: lithography precision, transistor density, and cost per unit of computing power.
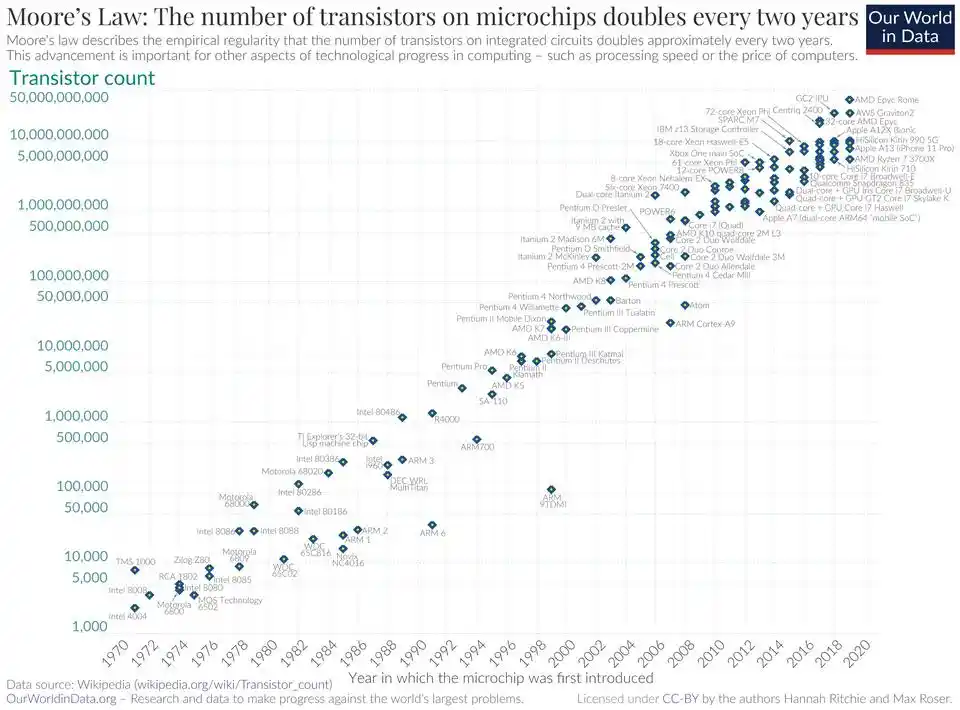
The Density Law follows the same path.
It was initially just a fitting curve from a single team. By the time it was accepted by the Nature sub-journal, it could already be reproduced on contamination-filtered datasets. And this month, it was independently verified twice more in Meta's training data and METR's task evaluations.
Viewed in a larger coordinate system, this moment is very much like when electricity first entered New York in the 1880s.
Back then, it was also different inventors, different engineers, different cities, each working on their own power grids. It wasn't until someone plotted the development curves of all the projects on one sheet of paper that people realized. This wasn't a few scattered engineering advances; this was a new era quietly unfolding.
Only this time, it took less than a year from the paper's publication to its verification by global peers.
Three Inferences, Each Rewriting Industry Assumptions
If the Density Law holds, it will rewrite many things simultaneously.
First, inference costs will crash faster than anyone expected.
One inference of the Density Law is that the inference cost for LLMs achieving the same performance roughly halves every 2.6 months.
Today, this rate of decline has already been exceeded by reality.
The latest tracking data from Epoch AI shows that the token price for LLMs achieving Claude 3.5 Sonnet performance level has dropped 400 times in the past year. The fastest decline for the same performance tier reached 900x/year.
The level that GPT-3.5 priced at $20 per million tokens in late 2022, today Mistral Nemo charges only $0.02, 1000 times cheaper, and the model is even stronger.
In retrospect, the prediction in the paper was conservative.
Second, the explosion point for on-device AI is closer than anyone thought.
Multiplying the Density Law by Moore's Law yields an even more exciting number.
According to current estimates, the maximum effective model size that can run on chips at the same price roughly doubles every 88 days.
This number is almost identical to the 88.6 days calculated by METR. Two completely different calculation paths collided after the decimal point.
In the next three to five years, running a current top-tier GPT-level model on an ordinary laptop or even a mobile phone may no longer be science fiction.
Third, the optimal strategy for the large model industry is quietly reversing.
For the past three years, the industry's understanding of the scaling law has remained at "stack parameters, stack data."
But the Density Law offers a counterintuitive judgment. Given the continuous exponential growth in density, any state's strongest model only has an optimal window of a few months.
Throwing all resources into training a larger model, only to be surpassed by a new model half the size three months later, is economically unwise.
The truly sustainable path is to invest resources in improving the density itself. Better architectures, higher quality data, smarter training algorithms.
ModelBest, Has Been Walking Along the Ruler They Drew
It's worth mentioning that the Density Law is not a paper that ended after publication.
ModelBest, which proposed this theory, has been verifying it with their own "Small Cannon" MiniCPM series models for the past two years.
When MiniCPM-1-2.4B was released in February 2024, its benchmark scores could match or exceed Mistral-7B from September 2023. That is, in four months, with 35% of the parameters, it achieved equivalent performance.
This number was directly written into the Nature sub-journal paper as the first empirical case of the Density Law.
Since then, the Small Cannon series has been open-sourced all the way, covering four major directions for parameters below 10B: text, multimodal, speech, and full-modality. This level of open-source completeness domestically, besides Alibaba, only ModelBest has achieved.
So far, the global open-source downloads of the Small Cannon series have exceeded 24 million.
It is not the largest model in the industry. But it is the first team in the industry to implement "density first" as a company methodology.
And when Meta and METR verified the Density Law in their respective ways in April 2026, this Chinese company that started training models using this methodology back in 2024 actually had a two-year lead in engineering experience.
This Time, Chinese Researchers Are at the Starting Point of the Curve
A theoretical framework proposed by a Chinese research team two years ago is being rediscovered, in their own ways, by overseas institutions like Meta and METR, the most serious players.
The weight of this matter may take some time to fully understand.
It is not a "we can do it too" story. It is a "we saw it a bit earlier" story.
There aren't many such moments in the history of science. A judgment doubted in 2024 became the same curve pointed to by multiple independent pieces of evidence in 2026.
This kind of "coincidence" across regions, methods, and institutions has happened a few times in physics, each time marking the end of an old paradigm and the beginning of a new one.
This time, Chinese AI researchers are standing at that starting point.
And that curve is still rising, doubling every 88 days.
References:
The "Density Law"首创 (first proposed) by ModelBest gains recognition from top overseas institutions like Meta
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
This article is from the WeChat public account "新智元" (New Zhiyuan), edited: 好困 (Hao Kun) 桃子 (Tao Zi)







