Original | Odaily Planet Daily (@OdailyChina)
Author | Asher (@Asher_ 0210)

Prediction markets are arguably the hottest topic in Web3 right now.
Trading on predictions surrounding macroeconomic events, the crypto industry, and even entertainment topics continues to heat up, with discussion fervor and participation numbers constantly rising. However, as the market develops rapidly, some discordant voices have gradually emerged—some events, upon settlement, deviate from user expectations based on common sense or "real-world understanding," sparking controversies about rule design, fairness, and even platform credibility.
Recently, two highly controversial events occurred in quick succession within prediction markets. Below, Odaily Planet Daily will summarize and discuss them.
Polymarket: US Rescue of Downed Pilot in Iran Judged as US Invasion of Iran
On April 3rd, a US F-15E Strike Eagle fighter jet was shot down by Iranian air defense systems in southwestern Iran. The two crew members (one pilot, one Weapon Systems Officer/WSO) ejected; one was quickly rescued, while the other was missing for several days, hiding in the Iranian mountains.
- The US military subsequently launched a Search and Rescue (SAR) operation involving armed aircraft, helicopters, etc., ultimately rescuing the second, severely injured crew member (Trump personally announced "WE GOT HIM").
- The rescue operation involved US forces entering Iranian territory (mountain search and rescue, possible ground or low-altitude operations), which drew attention given the current sensitive geopolitical conflict backdrop.
Since the US military entering Iranian territory could, in a way, be considered a US invasion of Iran, it directly affected the prediction event on the Polymarket platform regarding when US forces would enter Iran (US forces enter Iran by?).
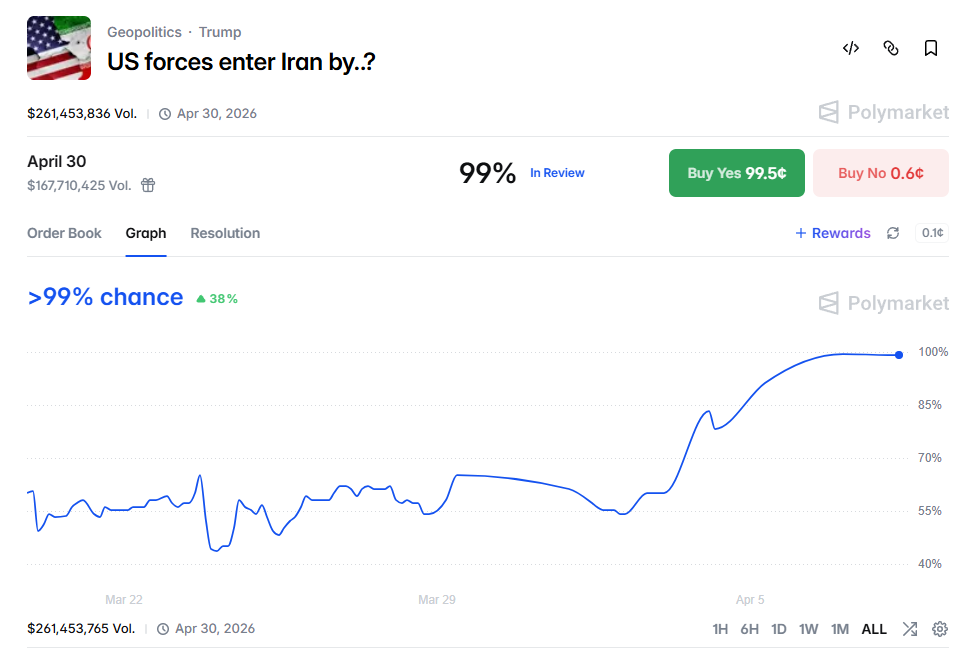
According to the settlement rules, active US military personnel (including special operations forces) entering Iranian land territory before the specified date counts as an invasion. Downed pilots do not count as invasion, but the special forces sent by the US military did indeed enter Iranian territory to rescue the pilot. Therefore, the special forces entering Iran for the rescue mission met the criteria for a Yes判定 on the US invasion of Iran.
Polymarket's判定 of the "pilot rescue" event as a US invasion of Iran has sparked strong community controversy.
Those supporting "counts as entry" (Yes side) argue that this operation符合 the definition of "entry" in the rules. The US special forces deliberately entered Iranian territory to execute a mission, and the rules explicitly state "special operation forces will qualify", also covering "for operational purposes (including humanitarian)". Objectively, this is the first confirmed ground infiltration by US forces in the current conflict context; US personnel did set foot on Iranian soil, so it should be considered "entry".
Those opposing "counts as entry" (No side) believe this definition is an overextension. The action was essentially a short-term, limited-scale humanitarian rescue, not a combat invasion (invasion), nor did it have an intent to occupy,不符合 the public's common-sense understanding of "US forces entering Iran". Furthermore, the rules explicitly exclude "pilots who are shot down... will not qualify", and this operation was precisely centered around a downed pilot, possessing a "forced entry" nature, logically falling under a similar exception. Referencing past cases (e.g., similar regional actions not deemed invasions), rescue operations should not be equated with military entry;判定 it as Yes might encourage marginal interpretations of the rules, weakening the market's seriousness and consistency. The Chinese community also普遍 believes "entering Iran" should refer more to large-scale ground or amphibious warfare, not a short-term "rescue and leave" operation.
Predict.fun: Polymarket Issuing Stablecoin Judged as Token Launch
On the evening of April 6th, Polymarket官方 announced on X a comprehensive exchange upgrade:
- Rebuilding the trading engine, upgrading smart contracts;
- Launching a new native collateral token, Polymarket USD (1:1 pegged to USDC, intended to replace USDC.e and reduce bridging risks).
The second point, mentioning the launch of the native collateral token Polymarket USD, directly affected the probability of two related prediction events on the Predict.fun platform: one关于 token launch; the other about post-launch market cap:
1. When will Polymarket launch a token? (Will Polymarket launch a token by ___?)
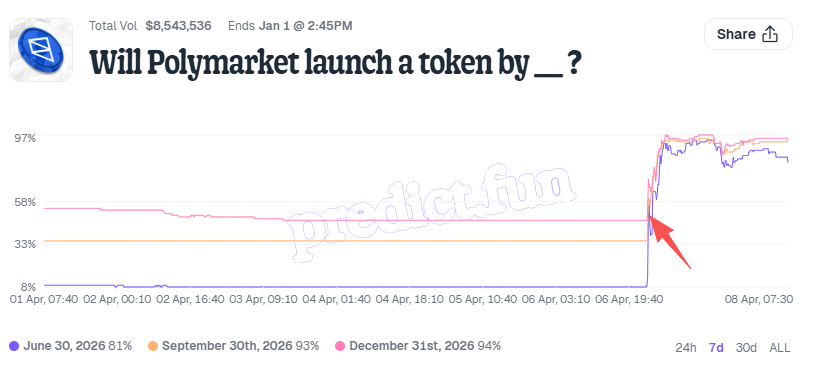
2. Polymarket's FDV one day after launch (Polymarket FDV above ___ one day after launch?);
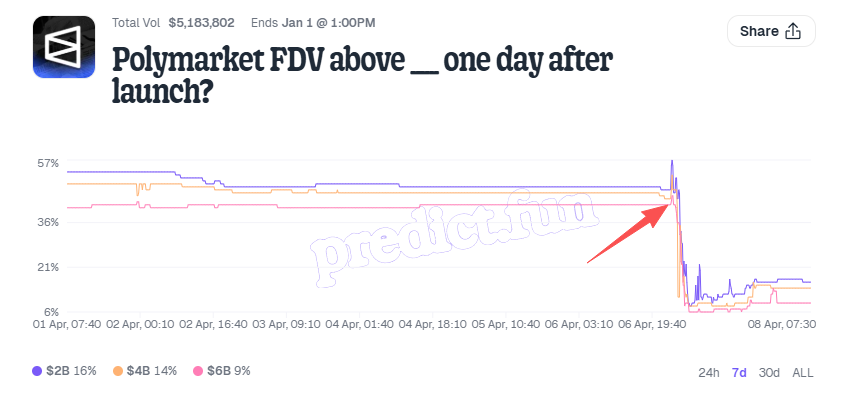
According to the settlement rules document, it clearly states that "Any fungible token issued by Polymarket counts as a 'token launch' for this event", and stablecoins are certainly no exception. Therefore, the Polymarket stablecoin meets the criteria for a Yes判定.
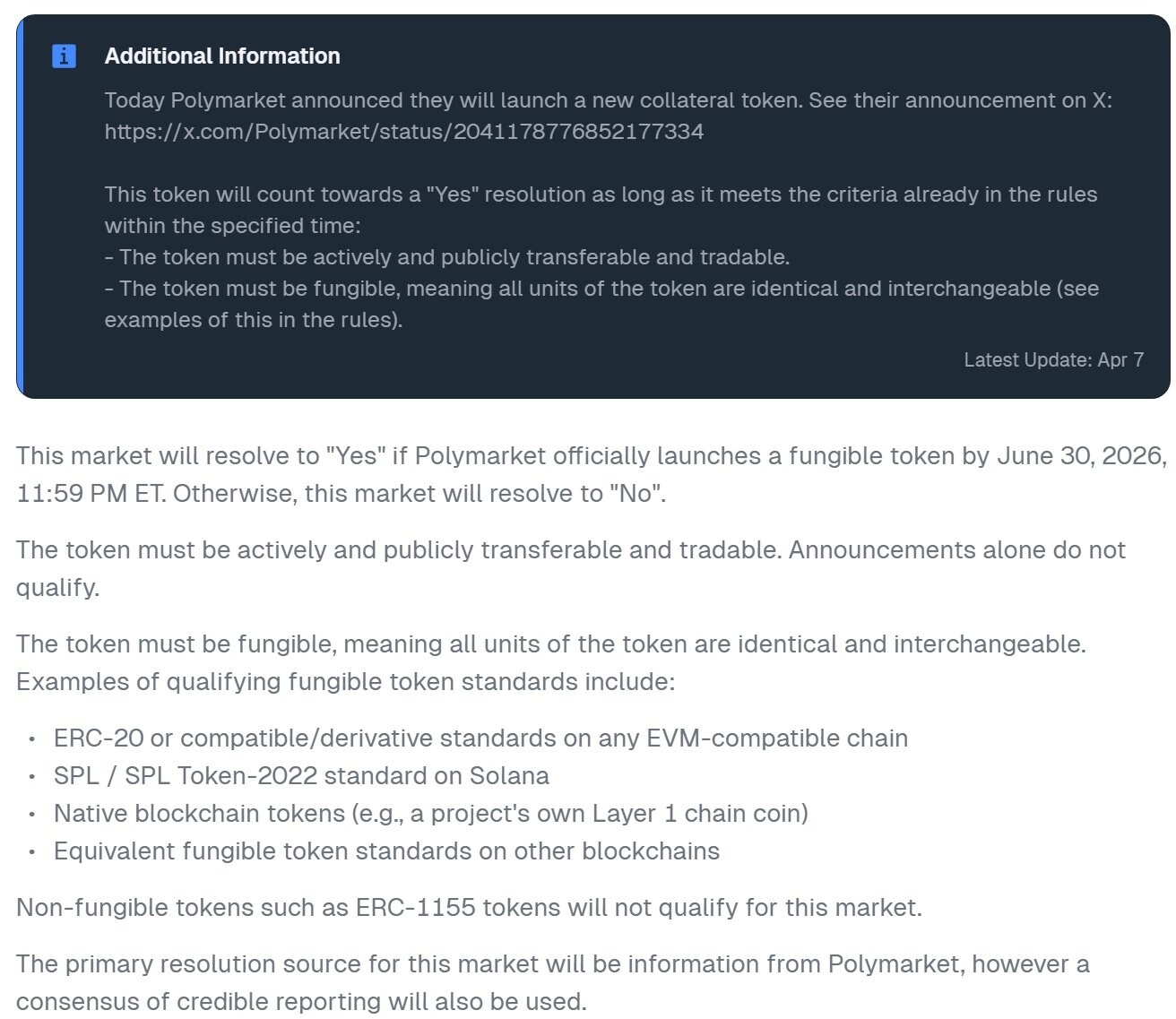
Relevant settlement rule说明
The community debated this.
Supporters argue that, literally from the rules, "issuing a token" is not limited to必须是 a "governance token" but is a general term for all tokens. Under this premise, Polymarket USD, as a fungible token (ERC20/SPL, etc.) issued by Polymarket,本质上符合 the definition of a "token launch". Additionally, the subsequent official clarification was more a reiteration of the existing rules rather than a临时 modification, so it has some legitimacy in terms of compliance.
However, skeptics do not accept this explanation. On one hand, they believe including stablecoins in the "token launch" category is an overinterpretation of the rules, a typical play on words; on the other hand, even if stablecoins are acknowledged as "token launches", the core of this prediction market is "Polymarket FDV", not "Polymarket USD FDV". Stablecoins serve more as collateral or settlement tools; their market cap structure is fundamentally different from that of a project's main token (e.g., a POLY governance token), and therefore should not be directly equated or substitute for the project's overall valuation logic.
Which Side Are You On?
Looking at the整体 picture, controversial events in prediction markets ultimately revolve around a core question: are you betting on "reality" or are you betting on "rules". Often, these two do not completely overlap.
For those of us participating in prediction markets, understanding the rules themselves might be more important than judging the direction of the event. How the information source is defined, whether there are exception clauses, whether there is room for interpretation—these details can directly determine win or loss at critical moments.
Precisely because of this, some high-probability events that look like "sure bets" are not without risk; they might instead be potential "lose-everything bets". Many reversals happen precisely in these overlooked details. Rather than betting blindly, taking an extra look at the rules is more useful than complaining after losing money.





