
A recent paper from Google Research has a core idea that can be summarized in one sentence: Instead of stubbornly pursuing "making AI omniscient and omnipotent", it's better to teach it to say "I'm not sure".
This paper, titled "Hallucinations Undermine Trust; Metacognition is a Way Forward", was jointly completed by Google Research and Tel Aviv University and has been accepted by the ICML 2026 Position Track. The paper suggests that the mainstream industry approach to combating "hallucinations" might be fundamentally misguided—everyone is busy pumping more knowledge into models, overlooking a more crucial and underestimated capability: enabling AI to perceive and express its own confidence level for each answer.
(Paper address: [2605.01428] Hallucinations Undermine Trust; Metacognition is a Way Forward)
The Utility Tax: The Real Cost of Eliminating Hallucinations
Let's start with a scenario everyone encounters.
You ask an AI assistant a question, and it gives an answer with an unshakeably confident tone, its wording precise, logic complete, seemingly flawless. Later, you check, and that answer is completely fabricated. What's even more infuriating is that it said it without any hesitation, as if it had witnessed it firsthand.
This is AI "hallucination"—the model outputs factually incorrect content but presents it to the user in an unquestionable manner. This problem is particularly fatal in high-stakes scenarios like healthcare, law, and scientific research.
The industry's approach to hallucinations essentially follows two paths. The first path: Make the AI know more, by expanding training data and increasing model parameters to cover more facts. The second path: Make the AI stay silent when uncertain, refusing to answer questions it's unsure about.
Both paths have obvious shortcomings. Facts in the world are endless; models cannot possibly memorize everything, so the first path will always have uncovered blind spots. The problem with the second path is that once AI starts refusing to answer on a large scale, it turns from a "useful assistant" into a "scaredy-cat that dares not say anything"—users ask ten questions, eight get rejected, leading to a terrible experience.
The paper gives the cost of the second path an apt name: "utility tax"—to reduce the hallucination rate, you must sacrifice a large amount of information that could have been answered correctly.
Why is this tax so heavy? The root cause is the lack of a key ability in AI. For the "refuse-to-answer" strategy to work precisely, the model needs to accurately distinguish between "I got this question right" and "I got this question wrong"—refusing only the wrong ones while keeping the right ones. But in reality, models cannot make this precise distinction. The paper distinguishes two easily confused but fundamentally different concepts to illustrate this problem.
Calibration measures whether the AI's overall confidence level matches its overall accuracy. For example, the AI answers 100 questions, each time saying "I'm 60% confident," and exactly 60 out of 100 are correct—this is perfect calibration.
Discrimination measures whether the AI can accurately distinguish "I'm right" from "I'm wrong" on each specific question. An AI that gives 60% confidence for all questions, with an overall accuracy of exactly 60%, is perfectly calibrated but has zero discrimination—it completely fails to distinguish which ones to trust and which to guard against. Good calibration does not equal strong discrimination, and this is precisely the crux of the problem.
After reviewing extensive literature, the paper finds that current mainstream large models' discrimination metric AUROC on factual question-answering tasks is concentrated between 0.70 and 0.85. This number might sound decent but is far from sufficient. Using AUROC=0.71 as a parameter, the paper conducts a set of simulations with startling results: assuming a base error rate of 25%, to reduce the error rate to 5%, the AI must refuse to answer over 52% of correct questions. Even if discrimination improves to 0.85, which is near the literature ceiling, it still requires sacrificing 28% of correct answers. Only when discrimination reaches above 0.95 does the cost become negligible—and currently, no method comes close to this number on knowledge-intensive tasks.
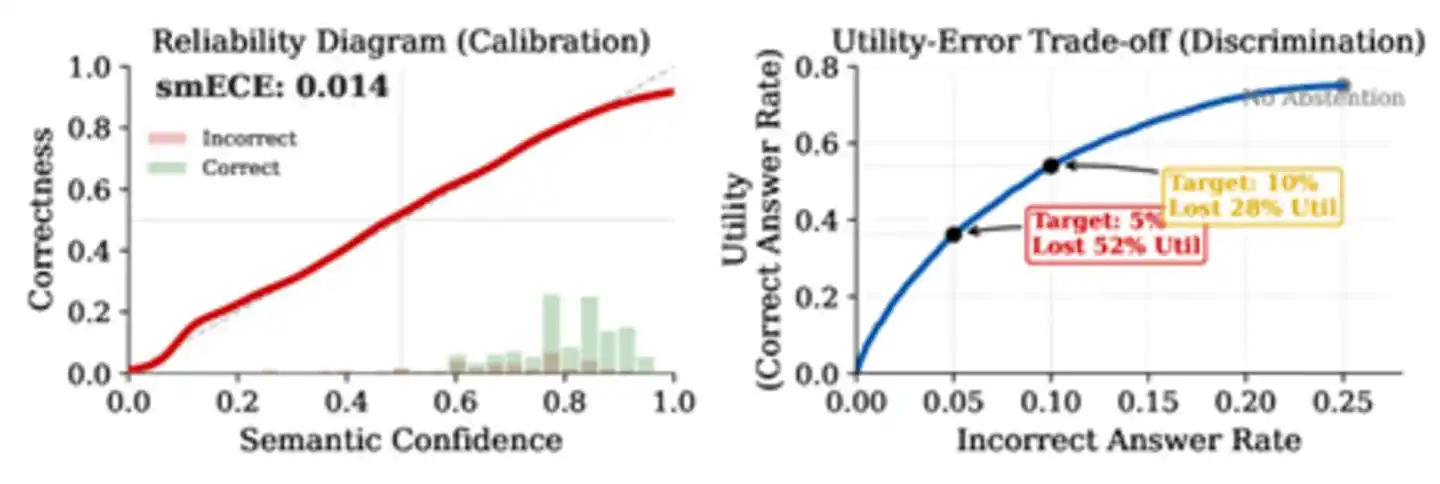
Figure: The difference between calibration and discrimination. The left plot shows the model is well-calibrated (red line close to the diagonal), while the right plot reveals the harsh reality—even with perfect calibration, to reduce the error rate from 25% to 5%, 52% of correct answers must be sacrificed.
Real data confirms this assessment. The paper analyzes the performance of various state-of-the-art models on the SimpleQA Verified benchmark, with results clear and somewhat brutal: most models distribute along the "answer more, err more" diagonal, while a few models pursuing high accuracy achieve higher per-question accuracy by refusing many answers, but at the expense of a huge utility cost. That ideal "upper-right corner" region—answering many and erring few—is currently empty. This blank space is precisely the "discrimination gap" mentioned in the paper.
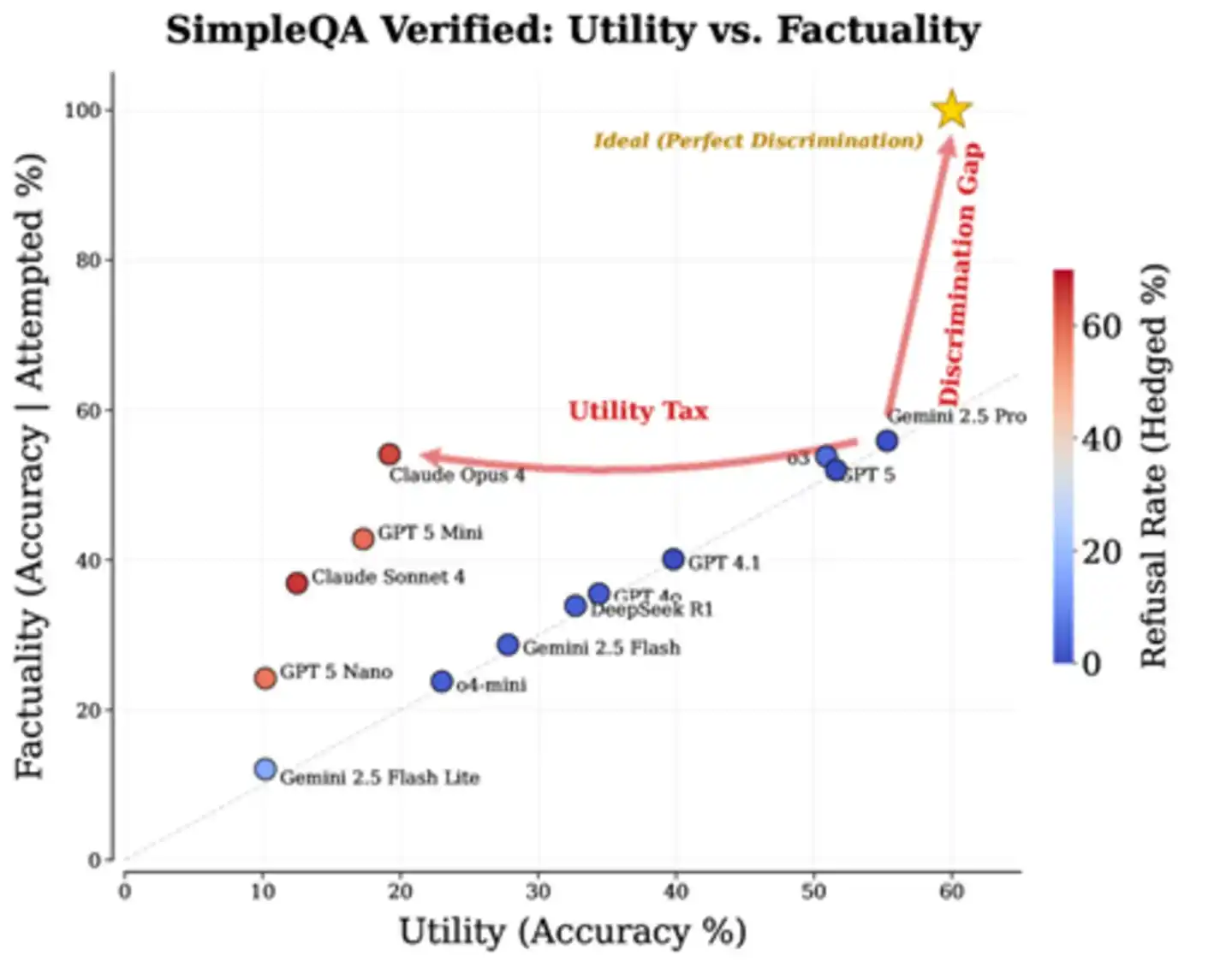
Figure: Measured performance of mainstream models on SimpleQA Verified. The five-pointed star in the upper right is the ideal target, "Discrimination Gap" marks the chasm between current models and the ideal, and "Utility Tax" indicates the utility price Claude Opus 4 pays for its high accuracy.
Since "stuffing more knowledge" has blind spots, and "staying silent when unsure" is too costly, is there a third way?
Redefining Hallucination: Not "Saying It Wrong", but "Claiming Certainty Without the Right to Be Certain"
The paper's core contribution lies not in diagnosing the problem, but in redefining the problem itself.
For a long time, the industry has defined "hallucination" as "AI outputting wrong information," implying a premise: eliminating hallucinations = eliminating all errors. But the paper proposes looking at it from another angle—hallucination is not "AI saying something wrong," but "AI having no right to be certain, yet giving wrong information with a tone of certainty".
This distinction seems subtle but has profound implications. For example: A doctor looks at test results and says, "You have disease X." If he's just guessing based on intuition, this is irresponsible. But if he says, "Current symptoms point to X, but further tests are needed for confirmation," even if the initial assessment direction is slightly off, this way of expression is honest in itself—he's telling the patient, "Please treat this judgment with caution." Errors are not unacceptable; what's unacceptable is pretending to be certain when uncertain.
Based on this new definition, the third way emerges: faithful uncertainty—enabling AI to express confidence levels at the linguistic level that truly correspond to its internal state's confidence level.
Specifically, an AI's "internal uncertainty" can be objectively measured through repeated sampling: ask the same question a hundred times; if it gives the same answer every time, it's internally certain; if answers vary widely, it's internally uncertain. "Linguistic uncertainty" is the sense of confidence reflected in the AI's wording—"August 4, 1961" versus "I seem to recall it was 1961, but I'm not entirely sure" give readers completely different signals.
Faithful uncertainty requires aligning the two: using tentative wording when internally uncertain, and using a definite tone only when internally certain. The paper emphasizes that this goal is more feasible than "eliminating all errors." The reason is that faithful uncertainty only requires the AI's language output to correspond to its own internal state—this is a closed-loop problem, the signal is inside the model, not dependent on external truth. Eliminating errors requires the AI's output to completely correspond to the truth of the external world; the paper cites the Halting Problem and computational theory, indicating this has fundamental theoretical limits.
The paper summarizes this capability into a higher-level concept: metacognition—AI can both perceive its own uncertainty and adjust its behavior based on that perception. This concept is borrowed from psychology, originally meaning "cognition about one's own cognitive processes." In the AI context, it means AI has a clear awareness of what it knows and what it doesn't know.
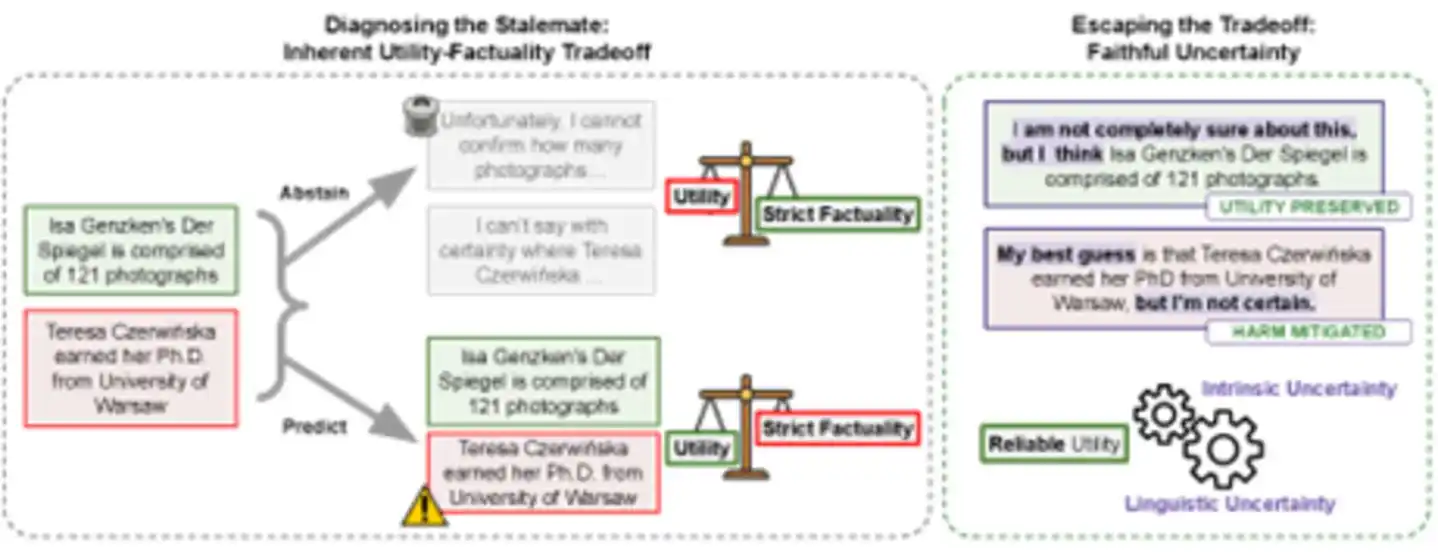
Figure: The left side shows the traditional dilemma—"answering" risks hallucinations, "refusing to answer" imposes a utility cost. The right side shows the new path—by faithfully expressing uncertainty, both retaining useful information and minimizing the harm of wrong information, achieving "reliable utility."
The Agent Era: Agents Without Metacognition Are "Flying Blind"
The value of metacognition is not limited to conversational scenarios. In the era of AI Agents, it becomes even more critical.
On the surface, equipping AI with a search engine seems to solve the lack of knowledge problem—just look it up when you don't know, what's there to fear about hallucinations? But the paper points out that tools introduce not a "storage solution," but a "control problem".
With tools, AI faces a series of new decisions: Do I know this myself, or do I need to search? Is the information found credible? If search results contradict what I know, which do I trust? When should I stop searching?
All these decisions depend on the AI's accurate perception of its own internal confidence level. An AI agent without metacognitive ability is like a pilot without an instrument panel—the engine is already alarming, and he's still accelerating.
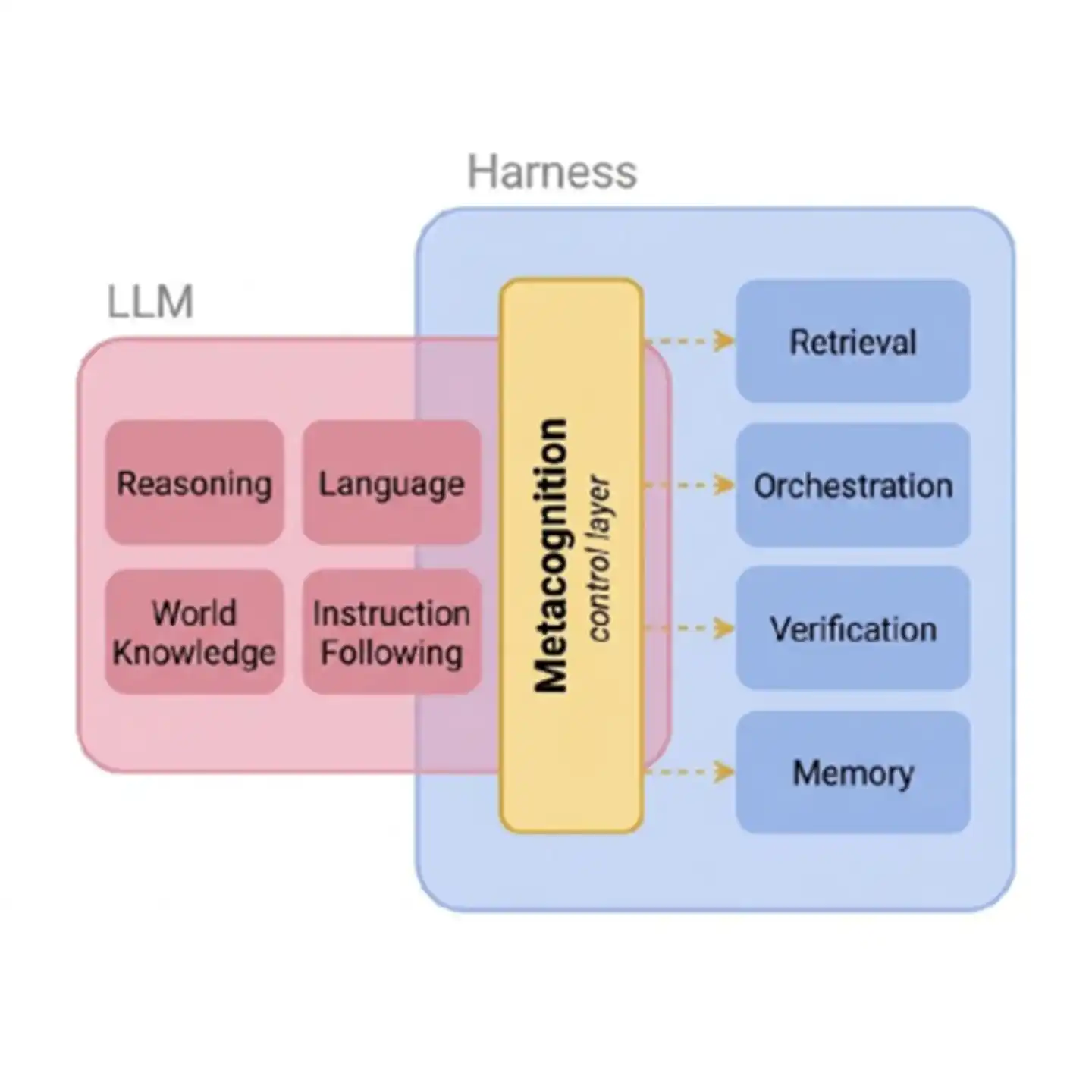
Figure: The metacognitive control layer serves as a bridge between the AI's foundational capabilities and the external tool system. Without this layer, an Agent's scheduling of external tools is like "flying blind"—not knowing whether to search, whether to believe the results, or to what extent.
Research cited by the paper indicates that current search-enhanced AI agents commonly suffer from tool overuse—searching for questions that don't need searching at all, leading to inefficiency and introducing unnecessary noise. The reason is simple: AI without metacognition simply cannot judge "Do I need extra information?"
On the Road to Metacognition, Several Hard Challenges Remain
The paper also frankly points out key challenges on the path to realization.
"Bootstrapping Paradox": Teaching AI to express uncertainty requires training data demonstrating "when to hesitate," but the AI's knowledge boundaries are dynamic. A training sample labeled "I'm not sure" might become something the model confidently knows after evolution. Using static data to teach a dynamic ability would train AI that "pretends to be uncertain." This requires developing dynamic data infrastructure that reflects the model's current knowledge boundaries.
"Alignment Destroys the Signal": Research finds that AI after pre-training actually has decent internal uncertainty signals—its internal state can distinguish "confident about this question" from "unsure about this question." But alignment training like RLHF erases this signal. The reason is that humans prefer answers with a certain tone, forcing the AI to learn to appear confident externally no matter how uncertain it is internally.
"Causality in Evaluation": A deeper challenge is ensuring the AI is genuinely reading internal signals, not just learning superficial patterns like "say I'm unsure when encountering rare words." Distinguishing "real metacognition" from "performance of metacognition" is a fundamental scientific evaluation problem.
The paper also offers specific suggestions to the research community: Stop evaluating anti-hallucination methods with only a single accuracy number. Instead, visualize the complete "utility-error rate trade-off curve" to see clearly whether a method genuinely improves underlying discrimination ability or merely raises the refusal threshold on the same curve. Simultaneously, detect "collateral damage"—whether reducing error rates in knowledge Q&A comes at an unexpected cost to tasks like reasoning, coding, and writing.
Ultimately, the core message this paper wants to convey is: AI doesn't have to be omniscient and omnipotent, but it must have an honest understanding of what it knows and doesn't know, and communicate that understanding to the user.
We trust professionals not because they never make mistakes, but because they can honestly distinguish "I'm certain" from "I'm guessing"—it is this distinction that separates the professional from the unprofessional. AI should also move down this road. Instead of endlessly chasing the illusion of perfect infallibility, it's more practical to teach AI one more thing: knowing when it's talking nonsense, and honestly telling the user. (This article first appeared on Titanium Media APP, author | Silicon Valley Tech_news, editor | Jiao Yan)






