
Imagine a scenario: you have three AI assistants collaborate to solve a math problem.
The traditional approach is: the first AI "writes" out the solution idea, the second AI "reads" it and writes a new idea, and the third AI "reads" and "writes" again.
This process is like three people taking turns using walkie-talkies to relay information, each time having to "translate" thoughts in their mind into language, and the other party "translating" the language back into thoughts. Is it slow? Yes. Is it costly? Yes. Even worse, this "translation" process loses information—what you think in your mind and what you say are often not the same thing.
This is the core dilemma faced by current multi-agent AI systems: "Language Tax."
Recently, a joint team from UIUC, Stanford, NVIDIA, and MIT proposed a new approach—RecursiveMAS. It allows AIs to skip the "speaking" step and communicate directly with "thoughts." In tests, reasoning speed increased by 2.4x, and token consumption was reduced by 75%.
(Paper link: https://arxiv.org/abs/2604.25917)
The Dilemma of AI Meetings: Efficiency Wasted on "Talking"
Over the past two years, multi-agent systems have become one of the hottest research directions in the AI field. From OpenAI's Swarm to Microsoft's AutoGen, from LangGraph to CrewAI, various players are exploring how to make multiple AIs collaborate to solve complex tasks that a single model cannot handle alone. However, in these systems, the collaboration efficiency of multiple agents is always constrained by a fundamental assumption—agents must communicate through natural language text.
When you have a "math expert" and a "code reviewer" collaborate, the whole process seems "reasonable," but breaking it down reveals many problems:
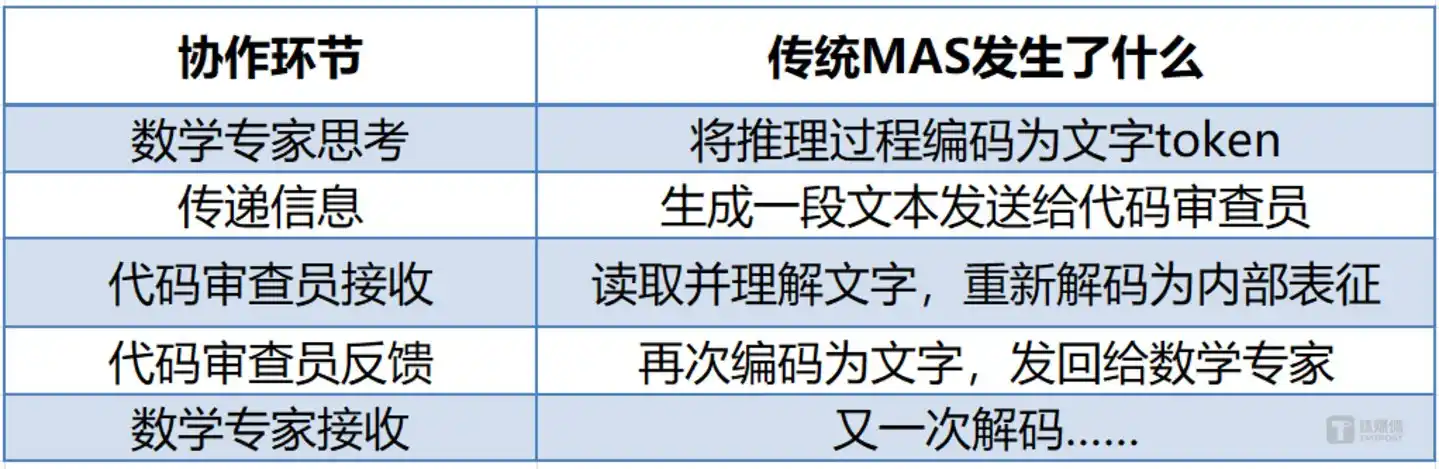
Each information transfer involves a double conversion: internal thought → text → internal thought. The tokens consumed in this process are not just money, but also precious computational resources and time. More crucially, this "write-out then read-in" process loses information—the rich semantics the model compresses into text during decoding cannot be fully recovered by the next model upon re-decoding. In a workflow involving five Agents, the time overhead for text encoding/decoding often accounts for over 60% of the total latency.
Even more troubling is that this paradigm lacks a clear "knob" for systematic optimization—add more agents? Marginal returns diminish, and communication overhead increases exponentially. Increase context window? Token costs explode. Increase model parameters? Individual agents become stronger, but collaboration efficiency doesn't improve fundamentally—it's like giving a group of people better walkie-talkies each, but they still have to read text aloud one by one; the communication method hasn't changed, so even if everyone is smarter, overall efficiency cannot have a breakthrough. Industry solutions, whether prompt engineering or LoRA fine-tuning, can only alleviate symptoms to some extent, unable to cure this fundamental architectural problem.
RecursiveMAS: Replacing "Walkie-Talkies" with "Telepathy"
The core idea of RecursiveMAS is very clever: since language is the bottleneck, then don't use language.
It draws inspiration from the idea of Recursive Language Models. In traditional language models, data flows from the first layer to the last, linearly; the more layers, the more parameters. Recursive language models do the opposite—instead of adding layers, they repeatedly cycle the same set of layers, letting data "circulate" back and forth between layers. Each pass through this set of layers is equivalent to an additional round of "thinking," deepening the reasoning depth without increasing parameter count.
RecursiveMAS extends this idea from "within a single model" to "multi-agent systems":
Each agent is like a layer in a recursive language model; they no longer generate text but pass "thoughts"—a continuous, vector representation existing in the latent space.
The researchers used a poetic analogy: "agents communicating telepathically as a unified whole."
Specifically, Agent A1 processes and passes its latent representation to Agent A2, A2 processes and passes to A3... until the last Agent processes, and its latent output is directly fed back to A1, starting a new round of recursive iteration. The entire process occurs entirely in latent space; only at the last Agent of the final round is the final latent representation decoded into text output. This is like a group of experts sitting around a table, not speaking, not writing notes; each person simply thinks silently and directly passes the "thought result" in their mind to the next person—the whole process is quiet and efficient.
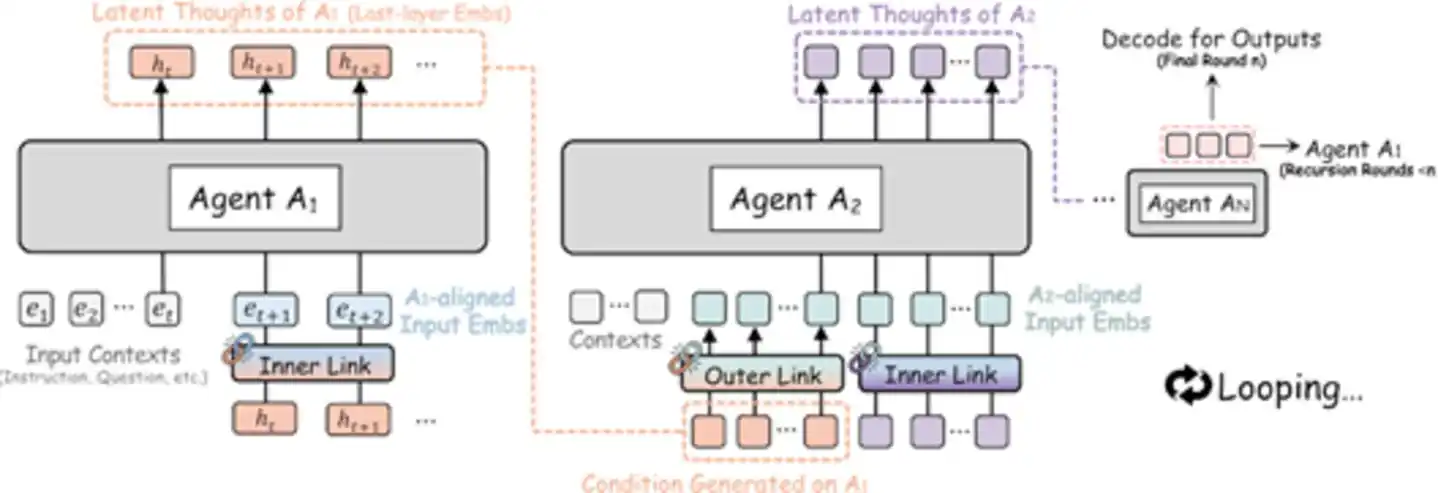
Figure: RecursiveMAS architecture schematic—Multi-Agents achieve closed-loop recursive collaboration via embedding space (Source: arXiv)
A key component of this system is called RecursiveLink, a lightweight two-layer residual module responsible for preserving and transforming a model's latent layer representation and passing it to the next model's embedding space. The latent state of the language model's last layer already encodes rich semantic reasoning information; what RecursiveLink does is completely "move" these high-dimensional information over, rather than first translating it into text and then interpreting it. It comes in two versions: inner and outer.

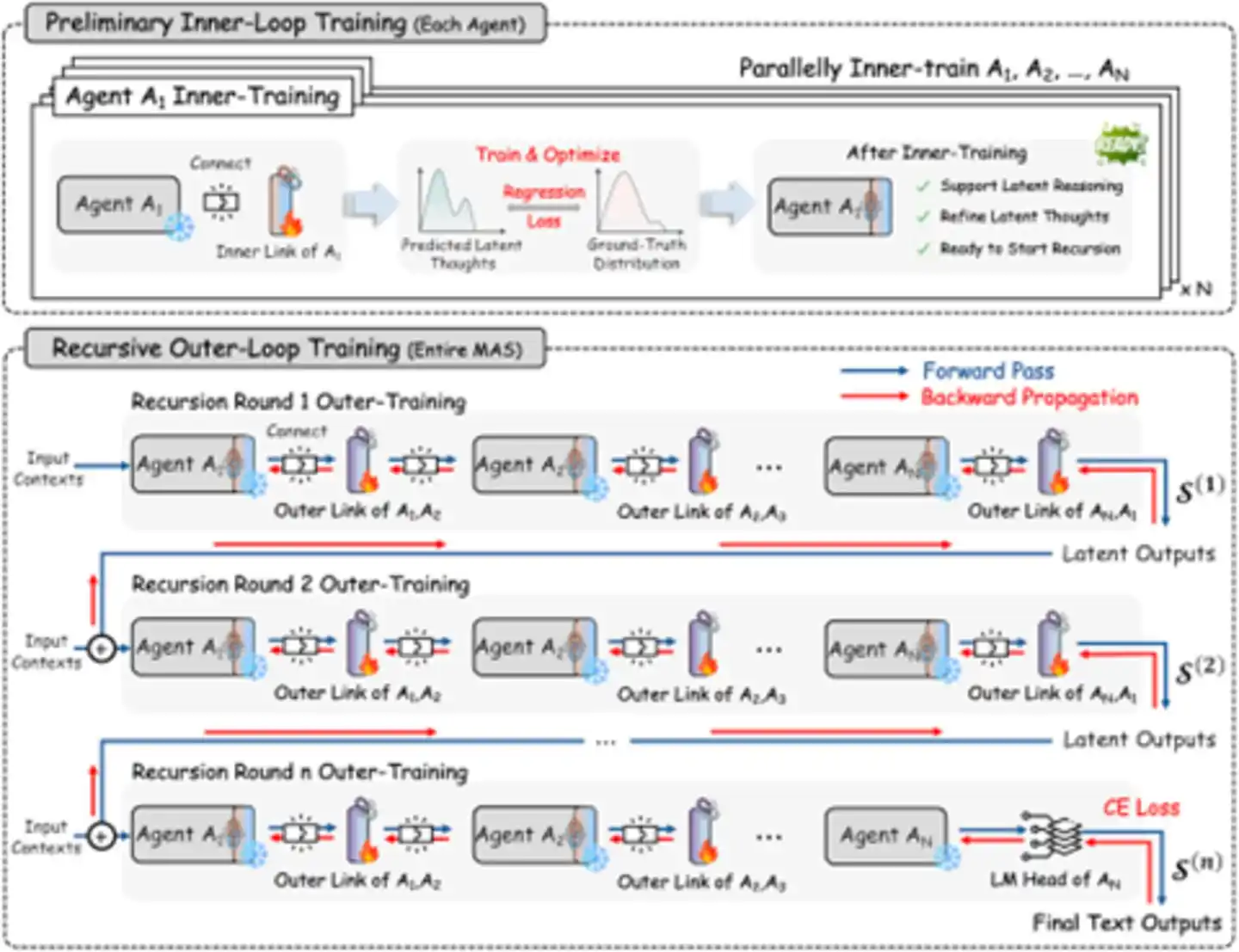
Figure: Recursive learning process—Inner and outer links co-train (Source: arXiv)
In terms of training strategy, RecursiveMAS has a clever design: the backbone model weights are completely frozen; only the RecursiveLink modules need training. This shares a similar spirit with LoRA (Low-Rank Adaptation), but RecursiveLink is even lighter: the entire system only needs to update about 13 million parameters, accounting for only 0.31% of the total trainable parameters. Peak GPU memory requirement is the lowest among all compared methods, and training cost is reduced by over 50% compared to full fine-tuning. You can think of it as a "lightweight adapter" that plugs directly into the existing Agent ecosystem without needing to train new models from scratch. If multiple Agents are based on the same base model (e.g., all using Qwen), they can even share the same model weights, further saving memory.
Training is conducted in two stages:
Inner Loop Warm-up: Each agent independently trains its own Inner RecursiveLink, teaching it to "think" in latent space rather than "write" problems. This stage can be parallelized, like having each person practice "inner monologue" first.
Outer Loop Training: All agents are connected into a complete recursive chain, optimizing all RecursiveLinks jointly via shared gradients with the goal of final text output quality. This stage addresses the "credit assignment" problem—how to accurately attribute the success or failure of the final result to each Agent's contribution. This staged strategy avoids potential training instability issues from attempting everything at once.
The researchers theoretically proved that the gradients of recursive training remain stable, avoiding the gradient explosion or vanishing problems common in RNNs, while also having better runtime complexity than traditional text-based MAS.
Measured Performance: "Triple Kill" in Accuracy, Speed, and Cost
No matter how good the theory sounds, it ultimately comes down to data. The research team conducted a comprehensive evaluation on 9 mainstream benchmarks covering mathematics, science & medicine, code generation, search Q&A, and 4 collaboration modes (sequential reasoning, mixture-of-experts, knowledge distillation, negotiative tool usage). The open-source models used in the experiments were quite "luxurious"—Qwen, Llama-3, Gemma3, Mistral—assigned different roles to form various collaboration modes.
The baseline lineup was equally formidable: LoRA fine-tuning, full fine-tuning (SFT), Mixture-of-Agents, TextGrad, LoopLM, and Recursive-TextMAS, which uses the same recursive loop structure but forces text communication. This last control is especially crucial—it proves that RecursiveMAS's advantages indeed come from "skipping text decoding," not from the recursive structure itself. All comparisons were conducted under the same training budget, ensuring fairness.
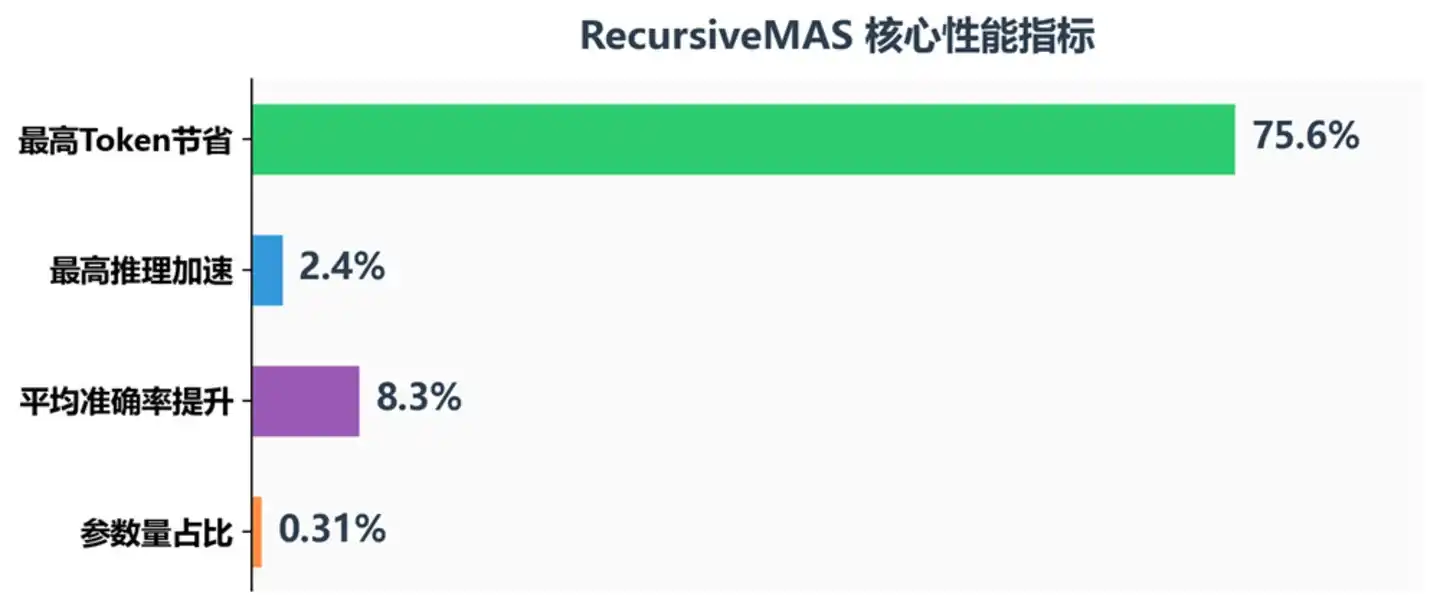
RecursiveMAS Core Performance Metrics
The results show that RecursiveMAS achieved consistent improvements across all metrics:
Accuracy: Average accuracy increased by 8.3%; it outperformed TextGrad by 18.1% on the AIME2025 math competition and by 13% on AIME2026. Skipping text decoding not only did not lose information but allowed the model to retain richer latent semantics—after all, the information loss in the process of compressing thoughts into text and then decompressing is far greater than we imagine.
Speed: End-to-end inference speed increased by 1.2x to 2.4x, and continued to grow with increasing recursive rounds. This is significant for real-world application scenarios: in AI customer service or code assistance systems requiring real-time response, a 2x+ speed increase means a qualitative leap in user experience.
Cost: Compared to Recursive-TextMAS, token consumption decreased by 34.6% to 75.6%. This is not just cost savings; it means deeper reasoning can be attempted under the same token budget.
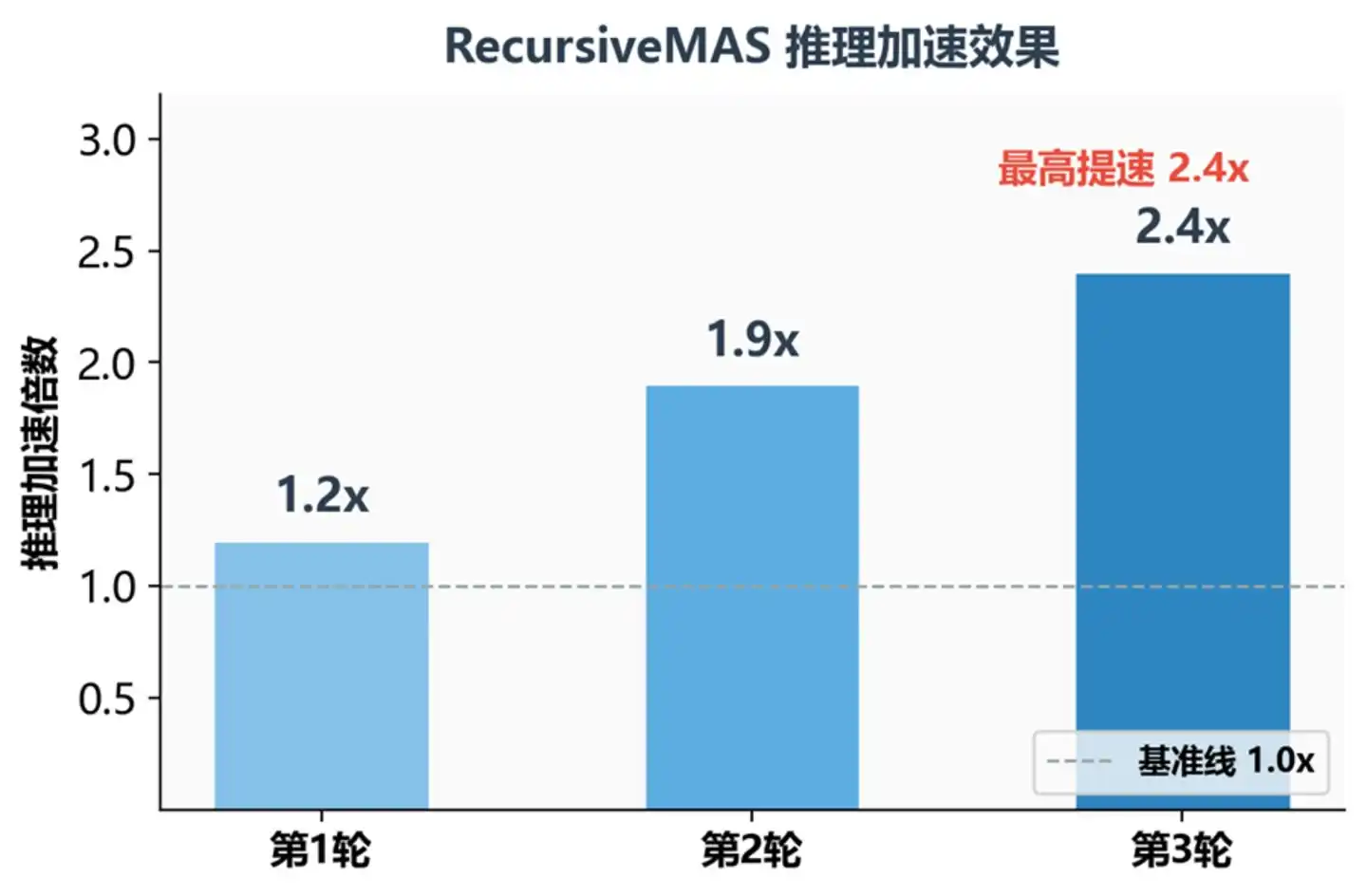
Inference Speedup Multiplier at Different Recursive Rounds
A key insight here: the greater the recursive depth, the higher the gain. The speedup effect grows with recursive rounds: average 1.2x at round 1, 1.9x at round 2, 2.4x at round 3. The reason is simple—what's saved is the time each Agent spends "writing thoughts into text"; the more Agents and rounds, the more time saved.
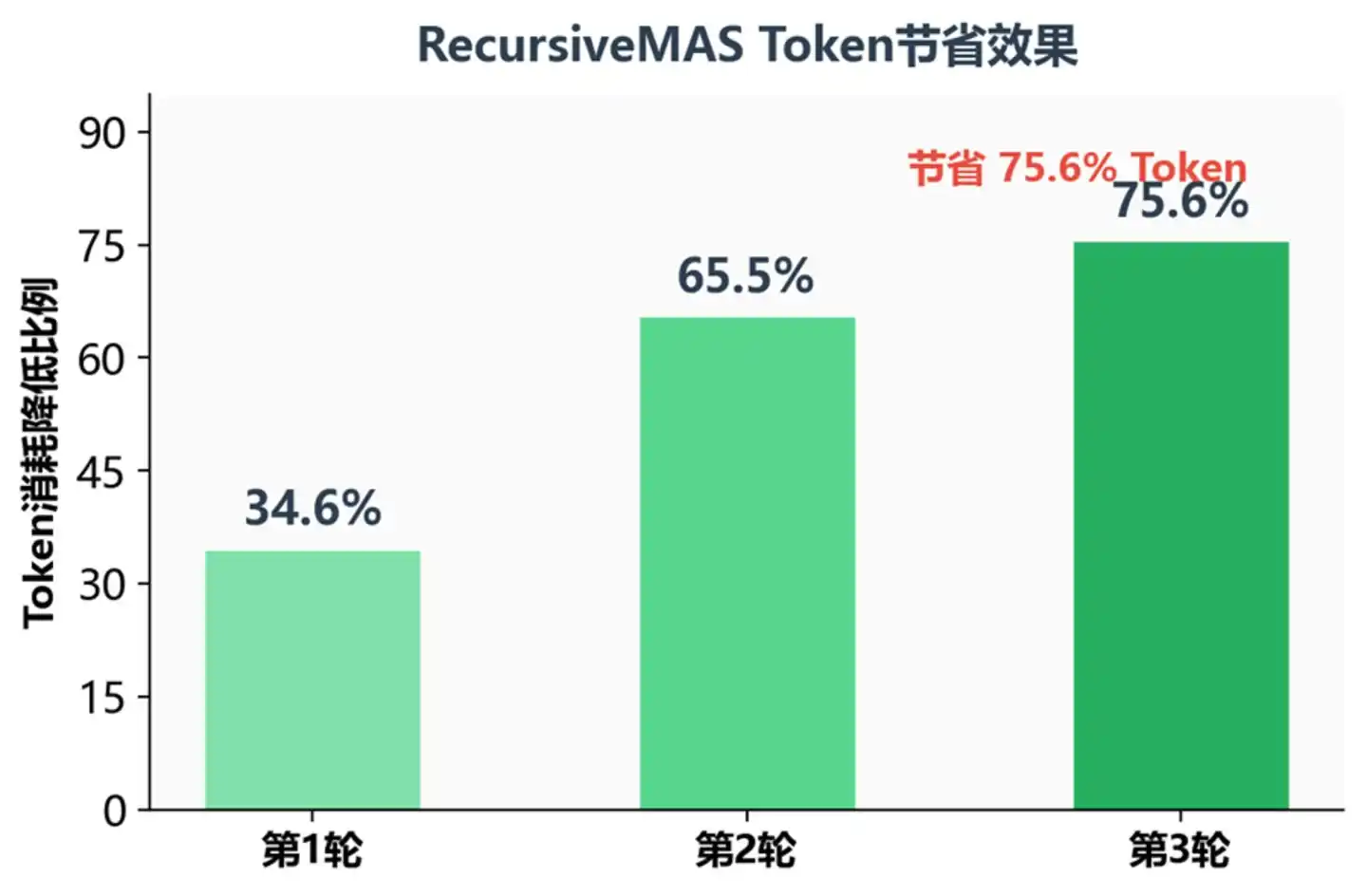
Token Saving Ratio at Different Recursive Rounds
At the third recursive round, token consumption decreased by 75.6%—meaning that at equal performance, operating costs can be compressed to about one-quarter. For production environments requiring complex multi-step reasoning, this is undoubtedly a huge attraction.
Why is This Research Worth Attention?
If it were just numerical improvements, this paper might not have attracted such attention. What truly makes it noteworthy is its potential to redefine the Scaling direction of multi-agent systems.
Over the past few years, Scaling attempts in the multi-agent field have mainly revolved around three paths: increasing the number of agents, expanding context windows, and stacking larger models. But each of these methods faces its own bottleneck—more agents lead to communication explosion, larger windows lead to cost explosion, and larger models lead to training explosion.
RecursiveMAS offers a new path: deepening recursive depth. It transforms "multi-agent collaboration" from a parallel, text-interaction paradigm into a deep, latent-space recursive paradigm. Just as recursive language models deepen reasoning by repeatedly processing the same problem, RecursiveMAS allows multiple agents to repeatedly "deliberate" each other's "thoughts" without having to "speak and listen back" each time.
The core question posed by the researchers in the paper is: "Can agent collaboration itself be scaled through recursion?" The answer seems to be yes.
When the system no longer needs to "translate" internal representations into human-readable intermediate formats, the upper limit of collaboration efficiency can potentially be further unlocked.
The current industry backdrop also provides practical landing scenarios for this research. Baidu's 2026 Developer Conference themed "Agents at Scale," Anthropic launching Claude Managed Agents, OpenAI advancing real-time GPT-5-level reasoning—the entire industry is seeking ways to move Agent collaboration from demos to production environments. And the three major hurdles—computation cost, inference latency, memory limits—are precisely what RecursiveMAS attempts to leverage with a 0.31% parameter overhead.
Of course, this research is still in its early stages, and several issues deserve attention:
Data credibility needs verification. The current results are self-reported by the authors; independent teams have not yet completed replication. The academic community's attitude towards new technology is often "bold hypotheses, careful verification." In this era of "paper explosion," independent replication is the best way to test a technology's true value.
Compatibility of heterogeneous agents. Although the Outer RecursiveLink is designed to connect models of different architectures, the paper does not detail the specifics of transferring latent representations across architectures. If it can only be used for homogeneous agents, its practical application scope will be greatly limited. After all, real-world scenarios often require mixing closed-source APIs like GPT-4o and Claude.
Decreased interpretability. When agents pass not readable text but a bunch of vector representations, the entire collaboration process becomes a "black box." In production environments where AI decisions need to be accountable, this opacity may pose compliance and auditing challenges.
Complexity of production environments. The paper tests relatively clean collaboration scenarios; real production environments often involve complex factors like external tool usage, human-computer interaction, and dynamic workflows.
The proposal of RecursiveMAS essentially introduces "recursion," a Scaling strategy proven effective in the single-model era, into the multi-agent era, challenging the default assumption that "agents must pass information through natural language." If the data is reproducible, the next-stage Scaling axis in the MAS field may shift from "stacking agent count" to "deepening recursive depth."
Certainly, this research still needs validation on more independent benchmarks, requires solving the issue of heterogeneous model interconnection, and needs to prove itself in real production environments. But at least, it shows us a possibility—
Collaboration between AI agents doesn't always have to be "like chickens talking to ducks."
((This article was first published on Titanium Media APP, Author: Silicon Valley Tech_news, Editor: Jiao Yan))






