Author: Matt White, Global AI Chief Technology Officer, Linux Foundation
Compiled by: Felix, PANews

Wang Xingxing (CEO of Unitree) and Matt White
A few weeks ago in Shanghai, a traveling companion (someone intelligent, observant, and who follows the news, but not deeply familiar with robotics) asked a question over dinner that had been anticipated throughout the trip.
"Those robotic dogs we see running around, the humanoid robots performing kung fu on the demo stage at Unitree's office, and the robot arms folding clothes we saw. How do they do it? Are they powered by large language models (LLMs)? How does this actually work? Is there some kind of language model controlling their movements?"
It's a great question, and frankly: yes, in a way, but the real story is far more interesting. The robots you see on social media are not ChatGPT in a metal shell. They run on a technology stack (multiple layers of AI working together). This stack has changed more in the past three years than in the previous thirty. Language models are part of it. Vision models, motion models, behavior trees, classic control loops, and an emerging family of systems called "world models" are also crucial components. And "world models" might be the most significant development of all.
This is a long article. It will start from the beginning, walk through each major transformation step by step, and arrive at the current stage: where robots can not only react to the world but also imagine it.
One: The Pre-LLM Era: When Robots Were Just Software
For decades, building a robot meant writing a massive amount of code, and almost none of it involved learning.
Classic industrial robots were carefully constructed towers of meticulously designed modules. Like the orange robotic arms welding Toyota chassis in the 1990s or Boston Dynamics' BigDog in the early 2000s.
- Perception: Filtering camera feeds, performing edge detection, using geometric matching to identify workpiece positions.
- State Estimation: Combining wheel encoders, gyroscopes, and accelerometers (sensor fusion) to determine the robot's position and speed.
- Planning: Given a target pose, computing a collision-free path within a known map using algorithms like A* or RRT.
- Control: At the lowest level, PID controllers adjusting motor torque hundreds or thousands of times per second to follow that path.
These layers were often written by different people in different labs and painstakingly stitched together. Behaviors (e.g., "if the cup is red, pick it up; otherwise, wait") were encoded as state machines or behavior trees: flowcharts for the robot to follow step-by-step.
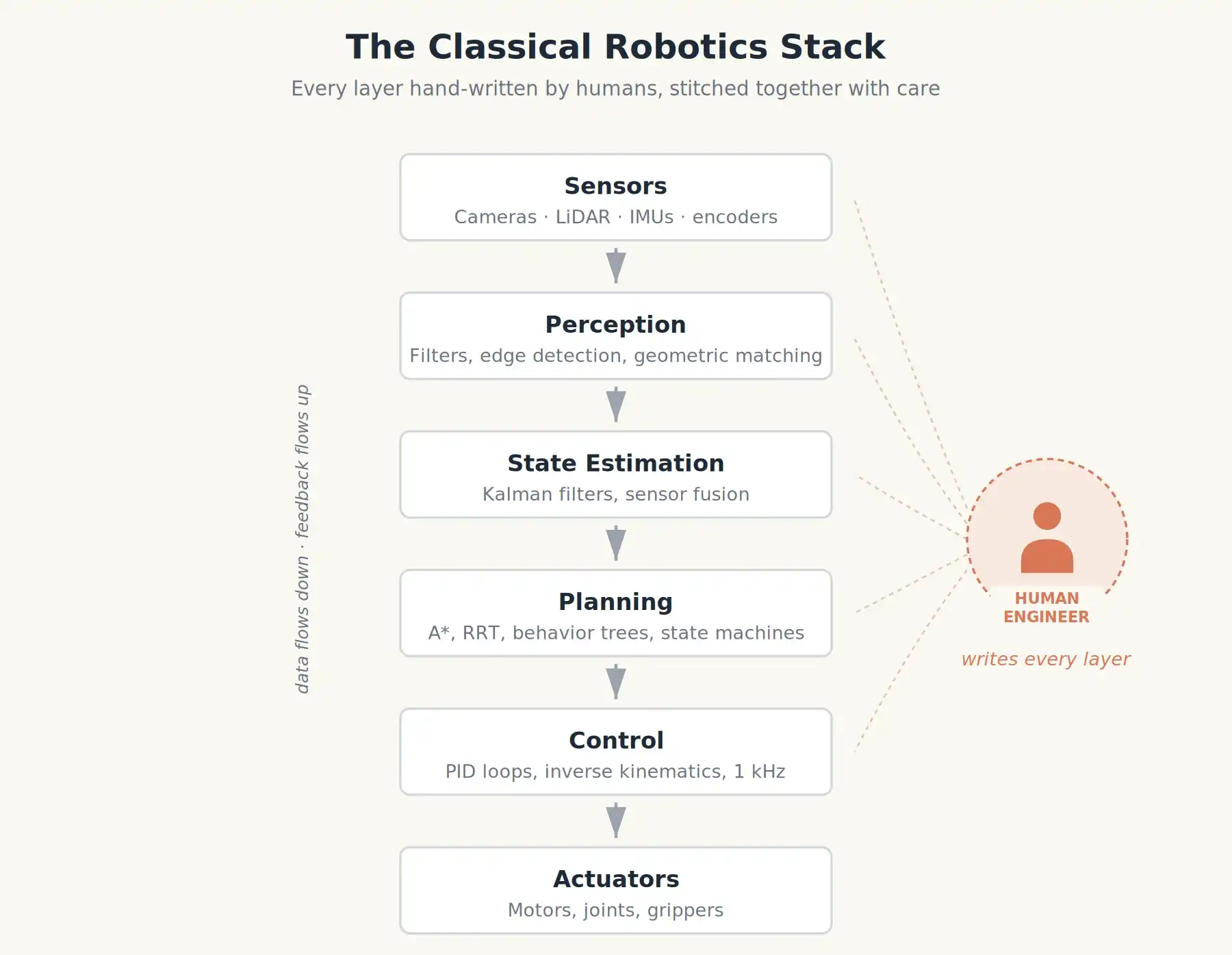
The advantages of this approach are obvious. It's predictable and meets safety standards. This is why your car has functional ABS brakes.
The disadvantages are equally obvious. Such a robot is only as smart as the scenarios the engineer envisioned. Put it in a new factory, under new lighting, or with a new cup color, and it breaks. Its ability to generalize is almost zero.
Two: Machine Learning Quietly Steps In
In the 2010s, deep learning began tackling the perception layer. Convolutional neural networks (CNNs) that beat humans at ImageNet image classification could be retrained to detect grasp points on objects, segment furniture in a room, or recognize human poses. Suddenly, the top "perception" layer of the stack didn't need handcrafting; you could just train it.
Then, learning crept into the "control" layer. Researchers from UC Berkeley, DeepMind, and OpenAI showed that reinforcement learning (letting a robot agent try millions of times in simulation and reinforcing what works) could produce surprisingly dexterous gaits, hand-object manipulation (OpenAI's one-handed Rubik's Cube solve in 2019 was a milestone), and locomotion strategies adaptable to different terrains.
A parallel line of research was imitation learning, often called behavior cloning: record hundreds of attempts of a human teleoperating a robot on a task, then train a neural network to predict what action the human would take given what the robot sees.
The key point in all this: each learned policy was too narrow. Train a network to pick up a red block, and it doesn't know what to do with a yellow cup. Train it to walk on grass, and it falls on tile. Generalization remained the unsolved problem.
It's worth noting that an infrastructure emerged during this period that still underpins almost everything today: ROS, the Robot Operating System (first released in November 2007). ROS is not an operating system in the Windows or Linux sense, but a middleware framework, a universal robot plumbing system. It allows "camera nodes," "navigation nodes," "arm controller nodes," and dozens of others to publish and subscribe to messages over a shared bus.
The current version, ROS2, runs at the bottom layer of the vast majority of research and commercial robots worldwide, from Stanford labs to Chinese humanoid robot startups. When people talk about a robot's "operating system," they almost always mean ROS2 plus the various perception, planning, and control packages running on top of it.
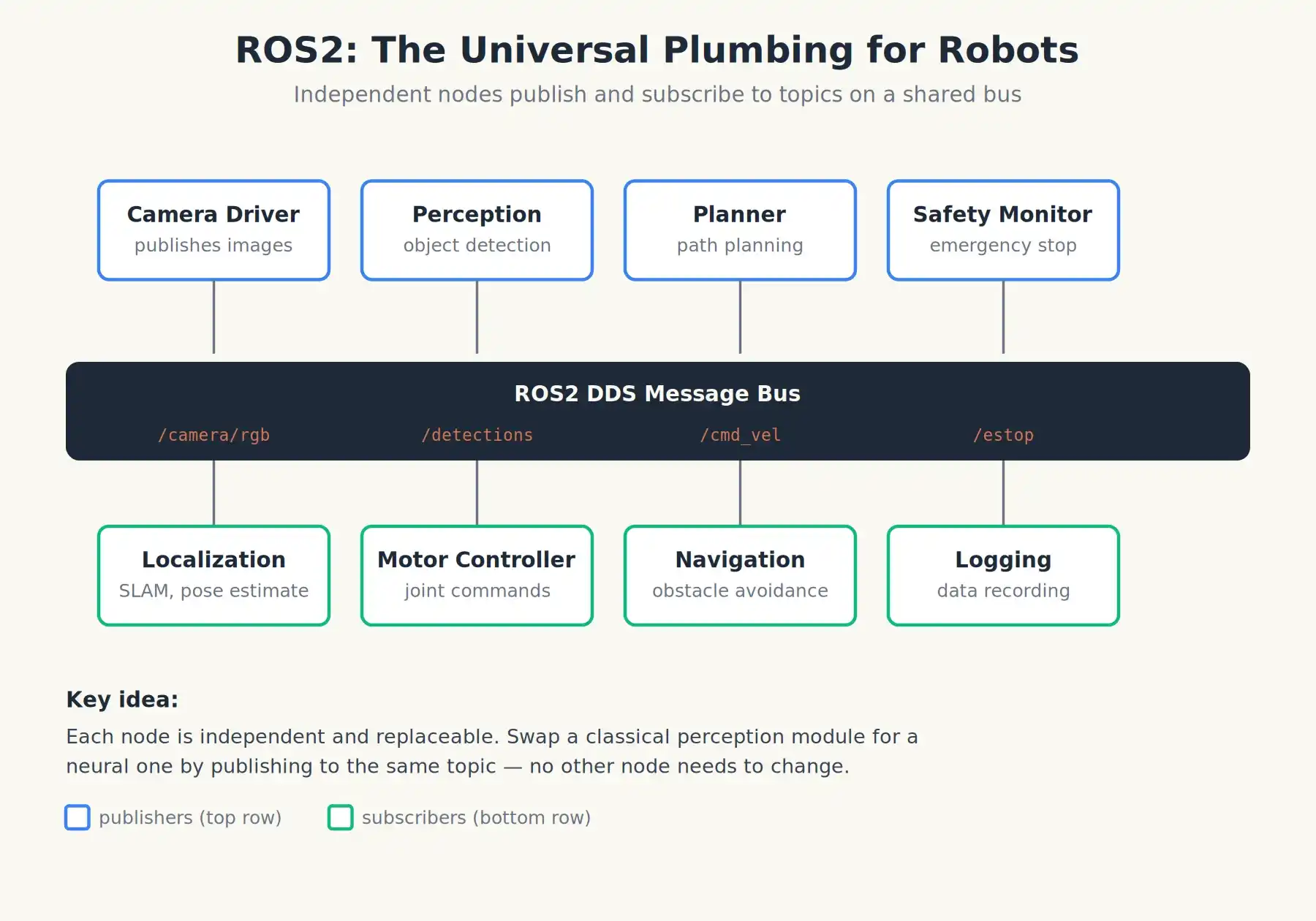
ROS2: It's not the OS, but the universal plumbing that lets disparate robot software talk to each other
Three: LLMs for Robotics
Then came ChatGPT.
Suddenly there was this thing: the LLM. It could read simple English instructions, do multi-step reasoning, write code, and call functions. Roboticists realized almost instantly: this was the missing piece they had struggled with for years. The hardest part of getting a robot to do something useful in a home or office often wasn't motor control, but human-robot interaction: how does a human tell the robot what to do, and how does the robot decompose that goal into atomic actions it already knows how to perform?
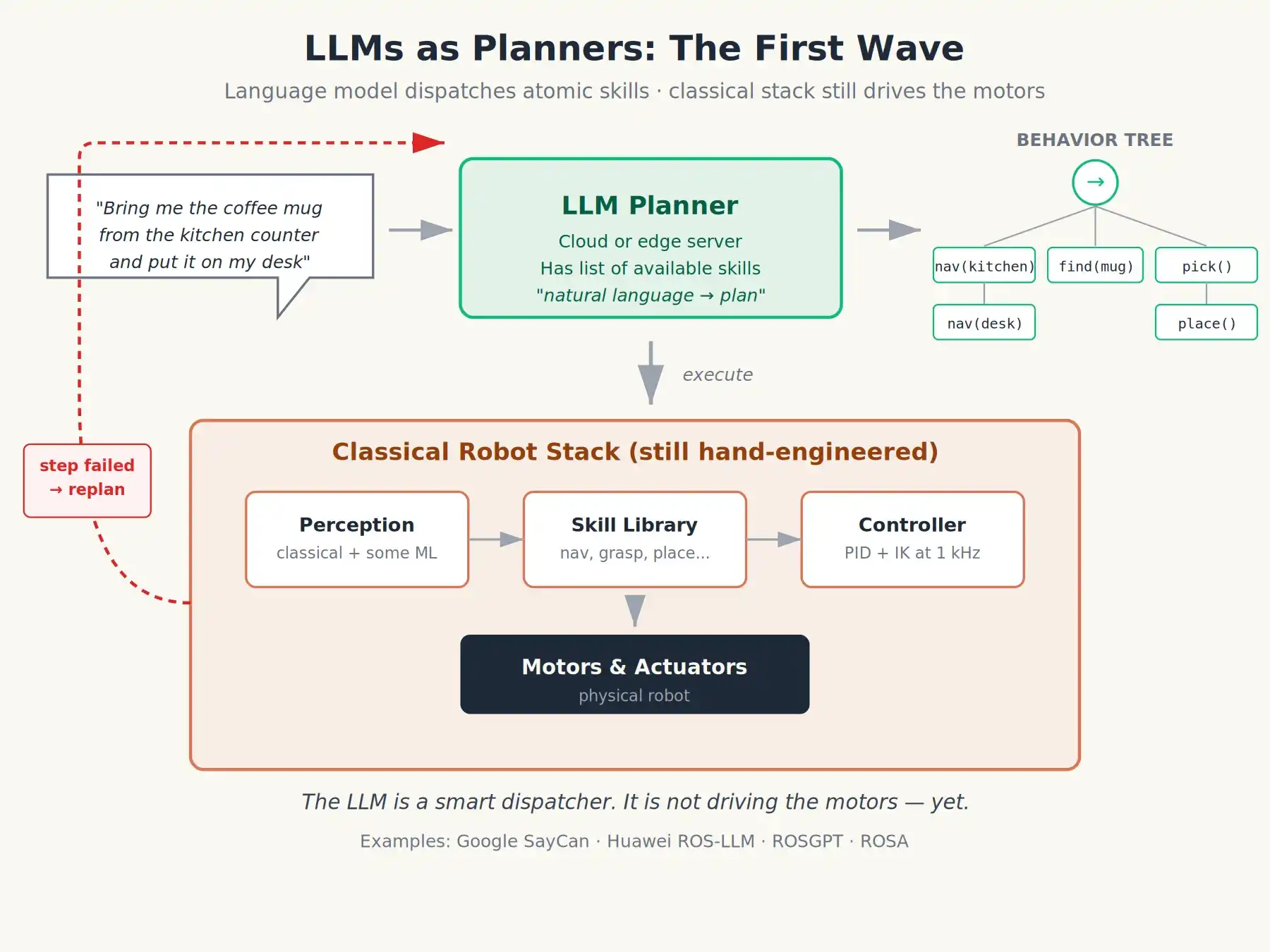
The first wave of applying LLMs to robotics was to treat the language model as a natural language compiler sitting on top of ROS. The pattern:
-
User says in English: "Bring the coffee mug from the kitchen counter to my desk."
-
LLM generates a plan based on a list of available atomic skills for the robot: a sequence of function calls, a state machine, or a behavior tree written in XML.
-
ROS2 nodes execute the plan step by step. If a step fails, the failure is reported back to the LLM for re-planning.
Google's SayCan project in 2022 was a very clean version of this idea: the LLM proposed skills, a separate "affordance" model scored the likelihood of each skill succeeding right now, and the robot picked the combination with the highest joint score. Open frameworks like ROS-LLM, ROSGPT, and ROSA, led by Huawei Research labs, popularized this pattern.
This was indeed a huge leap. Suddenly, you could tell a robot "clean the table, put recyclables in the blue bin," and it would attempt something sensible. But note the remaining issues: the language model is still at the planning layer. The actual motion commands are still generated by those painstakingly designed or narrowly trained controllers underneath. The LLM is just an intelligent dispatcher; it's not driving.
Four: Vision-Language-Action Models (VLA), When the Brain Starts Driving

Keenon XMAN-R1 robot picking medicine from shelves in an automated pharmacy at Beijing Galbot. For just $100k
The next leap was harder and more important. Researchers asked a more ambitious question: What if the model could not just plan but also directly generate actions? What if you fed camera images and language instructions directly into a neural network and got back the next millisecond's joint movements?
This is the Vision-Language-Action model (VLA). It is now the dominant paradigm for humanoids and quadrupeds.
The first widely known vision-language robot was Google DeepMind's RT-2 in 2023. The cleverness was this: take a large vision-language model (trained for image captioning and Q&A) and continue training it on robot demonstration data, but treat robot actions as just another token to predict. The same neural network that could output "cat sits on mat" could now output a series of tokens encoding "move right paw forward 3 cm, close gripper, lift 5 cm." Reasoning and action were in the same model.
Then, in mid-2024, a team led by Stanford released OpenVLA, an open-source 7-billion-parameter VLA model trained on the Open X-Embodiment dataset, a collection of over a million training episodes from 21 different research labs across 22 different robot bodies. For the first time, someone outside Google could download a generalist robot model and start hacking. It changed the field overnight.
Today, leading VLAs, though few, are rapidly evolving:
- π0 and π0.5 from Physical Intelligence: Excellent at task adaptation.
- NVIDIA Isaac GR00T N1.7: Open weights, commercial license, designed for humanoids, the model most Chinese hardware companies are currently fine-tuning with their own data.
- Figure AI's Helix and newer Helix-02: Proprietary, but architecturally significant.
- AgiBot's Genie Envisioner: A Chinese world-model-based platform.
- SmolVLA, NORA, ACoT-VLA, CogACT: A growing crop of VLAs from academia exploring different design directions.
How VLAs Work (No Math)
Think of a VLA as fusing three input streams into one output stream.
First stream is vision. RGB cameras (sometimes depth sensors or lidar), sometimes tactile sensors on fingertips, processed by a vision encoder (usually a Transformer model like DINOv2 or SigLIP) that compresses each image into a few hundred "vision tokens" summarizing what the robot sees.
Second stream is language. Your instruction ("hand me the screwdriver") gets tokenized just like in ChatGPT.
These two streams are concatenated and fed into a Transformer "backbone" (often a small open-source language model like Qwen3 or Llama). This backbone does the reasoning, combining what it sees with what it's asked.
Third stream: action, out the other end. This is where architectures diverge:
- Discrete action tokens: The model directly generates tokens that decode to joint angles or end-effector positions, just like ChatGPT generates words. Simple but can be jerky at high frequency.
- Diffusion or flow-matching action head: A separate tiny network takes the backbone's output and denoises a smooth trajectory of joint positions, like an image diffusion model but for motion. This is what π0 does, producing smoother, more natural actions.
- Action chunking: Predicts not the next single command but the next half-second of commands all at once, smoothing out jitter.
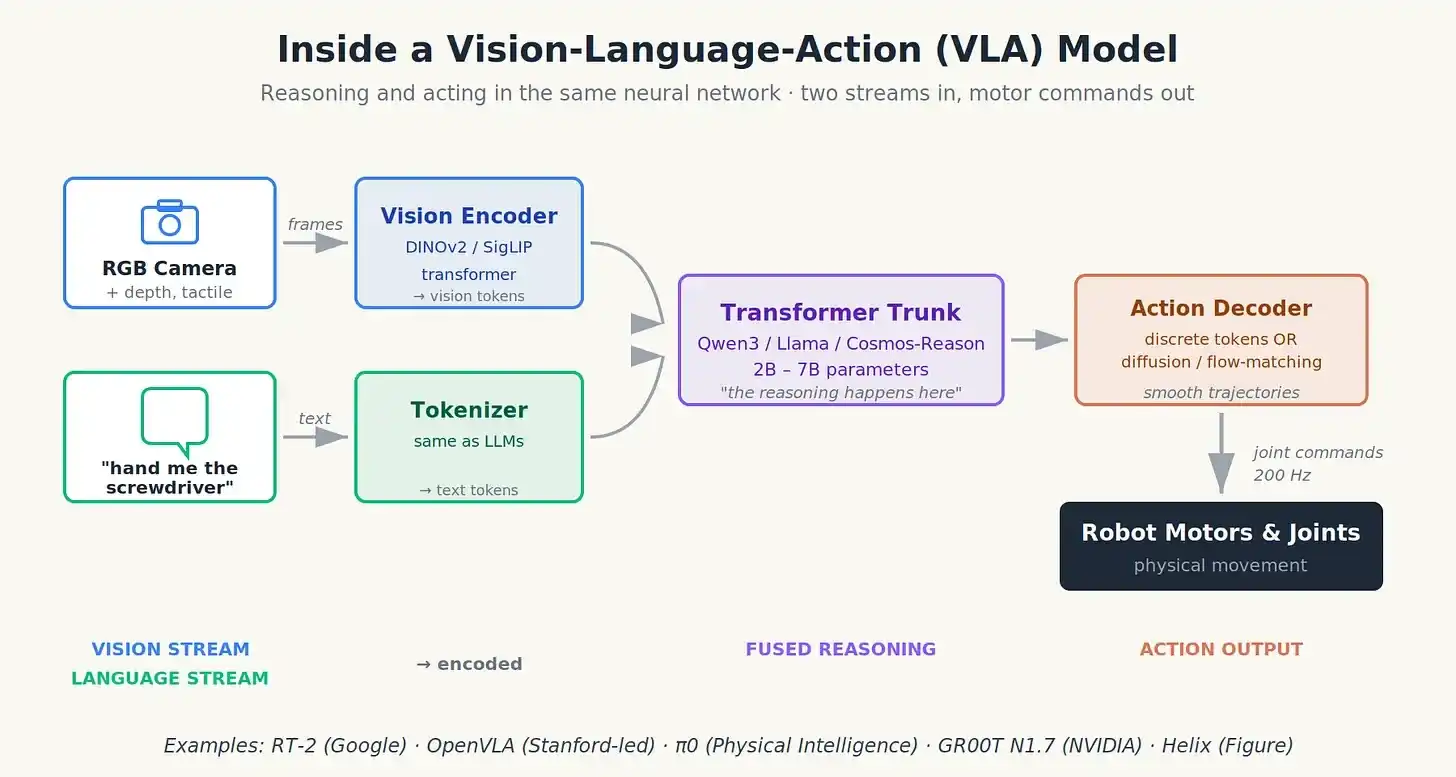
In a VLA model: two input streams in, motion commands out, reasoning and action fused in one network.
This is the crucial architectural shift: reasoning and action are no longer separate. Teaching a neural network to recognize a cup also teaches it how to grasp it. This coupling is what gives VLAs the generalization their predecessors lacked.
Five: The Two-Brain Strategy, How LLMs and VLAs Work Together
Here's a detail rarely explained clearly in marketing. The best-performing humanoid robots today don't run a single VLA system; they run two models at different speeds talking to each other. This is sometimes called the dual-system or System 1 / System 2 architecture, borrowing from Daniel Kahneman's psychology framework that humans have a fast, intuitive brain and a slow, deliberate thinking brain.
Figure AI's Helix made this design classic, and now it (and its variants) is copied almost everywhere. Crucially, NVIDIA's GR00T N1.7 uses this design, as do most Chinese humanoids. The structure:
- System 2 (S2): The slow-thinking brain. A ~7-billion-parameter vision-language model running at about 7–9 Hz (7 to 9 times per second). Its job is to observe the scene, parse the instruction, do multi-step reasoning ("the bowl is behind the cereal box; I need to move the box first"), and emit high-level intents—often a compact set of internal vectors, not words.
- System 1 (S1): The fast-reacting brain. A much smaller (~80-million-parameter) visuomotor policy model running at 200 Hz. It takes S2's intent vectors plus the latest sensor data and outputs continuous joint commands. It does no real "thinking," just reacts.
Recently, Figure's Helix-02 added a System 0. It sits beneath the dual brains, a reflex layer, not a third cognitive layer. This is a 10-million-parameter network running at 1 kHz, handling low-level balance and whole-body coordination, replacing over a hundred thousand lines of hand-coded C++ motion control. Think of S0 as a learned spinal cord: it doesn't reason or plan, just keeps the body upright and coordinated while thinking happens above.
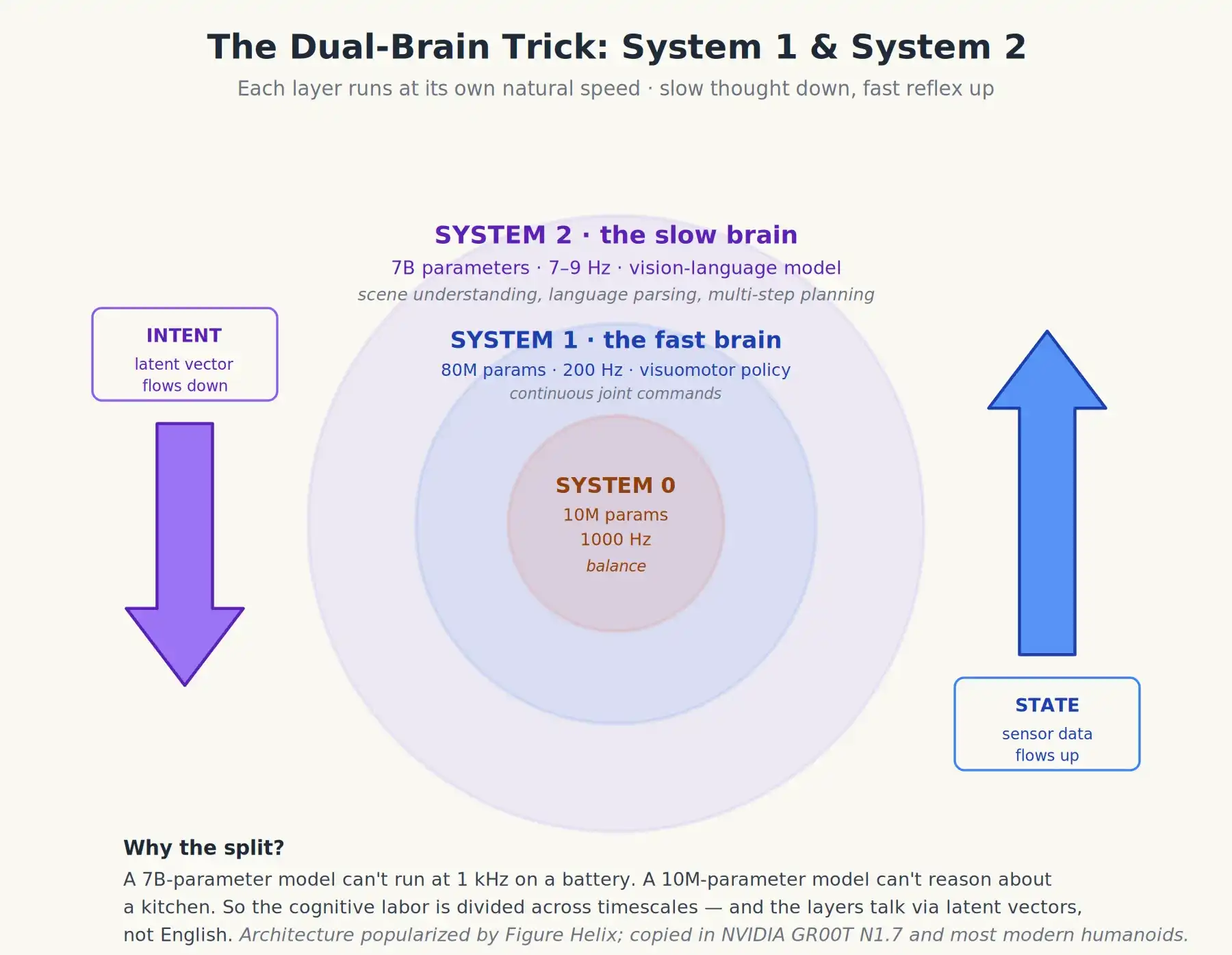
The dual-brain architecture of a modern humanoid: System 2 thinks slow, System 1 reacts fast—with a System 0 reflex layer beneath for balance, contact, and whole-body coordination
This division stems from physics. If motion commands are issued only every 200 milliseconds (the speed of a large VLA), the robot moves like it's underwater. Motion command updates must be faster than the natural oscillation of the joints they control, meaning hundreds to thousands of updates per second. No 7-billion-parameter Transformer model can run that fast on a battery-powered robot.
So, cognition is split: a big, slow model thinks; a tiny, fast model acts. They don't talk in English but in learned latent vectors: the slow model emits an abstract goal, and the fast model knows how to interpret it.
Six: Cloud, Edge, and Where the "Brain" Lives
Where does all this computation actually happen?
Today, there's a strong, almost ideological consensus across robotics teams that safety-critical control loops must run locally. Two reasons:
Latency. Round-trip over WiFi or cellular is optimistically 30-80 ms. Motion commands need updates every 1-5 ms. That network loop simply doesn't work.
Reliability. Robots operate in factories, warehouses, kitchens, hospitals. Networks drop. If a lost Wi-Fi signal stops the robot, it's a safety hazard.
So, the modern split is roughly:
Onboard (local), on something like an NVIDIA Jetson Thor or AGX Thor module (~2,000 TFLOPS, 128 GB RAM, 40–130 W):
- All of S0/S1: balance, locomotion, fine motor control.
- The VLA itself (System 2), increasingly quantized to FP8 or FP4 to fit hardware constraints. Models in the 2B to 7B parameter range can now run on-device.
- Perception, sensor fusion, and safety monitors that can override anything else.
Cloud or remote server (if present):
- Conversational interfaces ("Hey robot, what should I cook for dinner?"): Latency-tolerable.
- Fleet learning: Thousands of robots send teleoperation data back to a server to aggregate into the next model version.
- Large-scale, long-horizon planning, potentially using frontier-scale models.
- Operator dashboards and monitoring.
There's also a growing middle layer: local edge servers in the factory or warehouse, communicating with a robot fleet over a local network with single-digit millisecond latency. Larger LLMs might live here, doing high-level scheduling a single robot doesn't need to manage itself.
China's humanoid robot wave is built on this assumption: Unitree, AgiBot, XPeng IRON, Fourier, EngineAI. Their robots have onboard compute (often Jetson, sometimes domestic chips like Huawei Ascend), with the cloud used for fleet learning and conversational interfaces, not control loops.
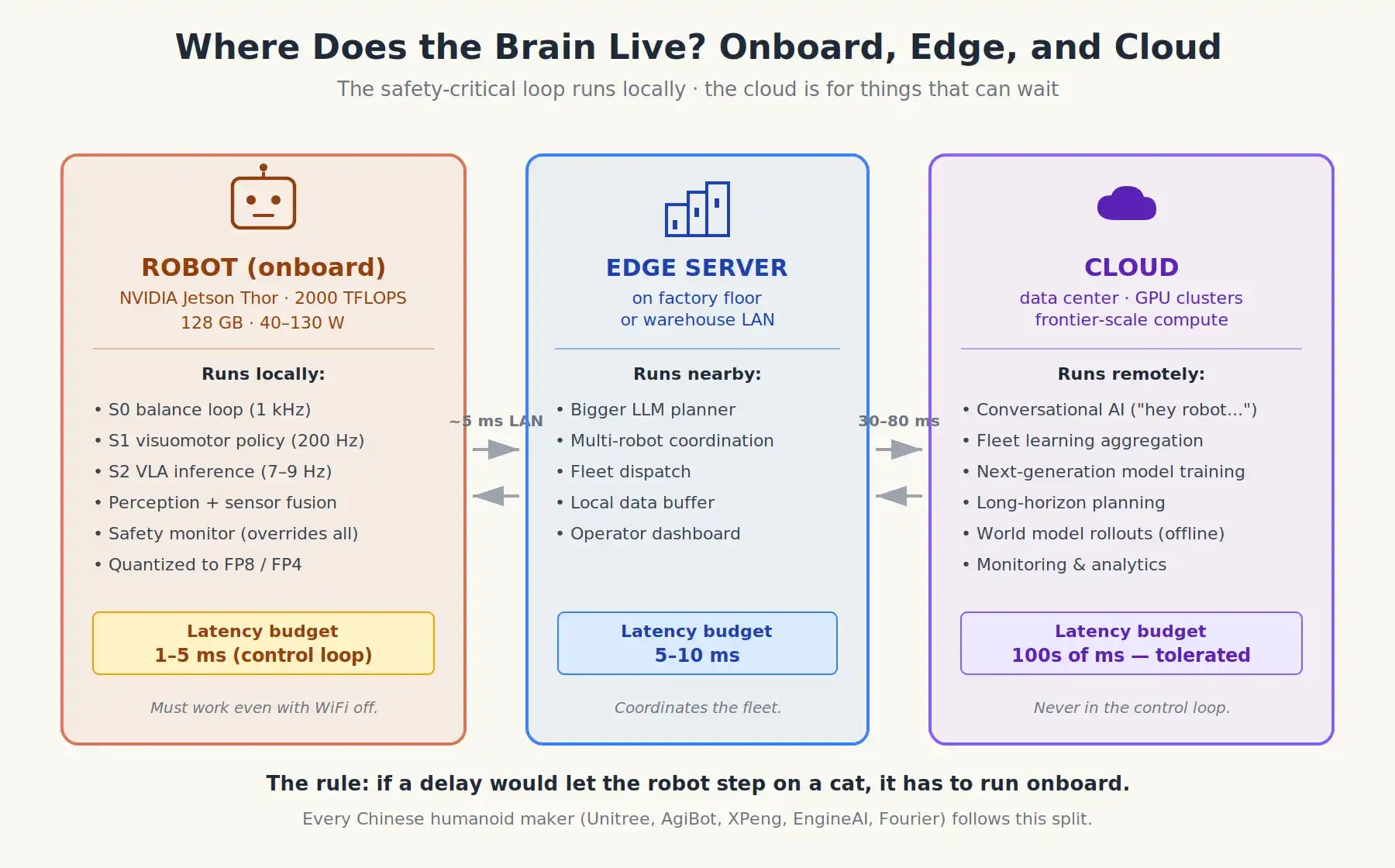
Where the robot brain actually lives: safety-critical loops are local, cloud for things that can wait
Seven: Why Open-Source Models Are Quietly Becoming the Center of Gravity
If you only watched demos, you'd think the field was dominated by a few well-funded US companies. The reality is more complex. The speed of physical AI progress is largely set by open-source weight models anyone can download and fine-tune.
The list is short but significant:
- OpenVLA (Stanford): The first open-source 7B generalist robot model.
- NVIDIA Isaac GR00T (N1, N1.5, N1.7): Open weights forthcoming, commercial license upcoming, trained on tens of thousands of hours of human egocentric video. GR00T N1.7, released March 2026, will make its dual-system architecture free for anyone with a humanoid.
- Physical Intelligence's π0: Weights released for research.
- NVIDIA Cosmos: Open-world foundation models.
- AgiBot World: Large open-source dataset of teleoperated humanoid demos from a Shanghai startup.
- Hugging Face's LeRobot: An open library that has become the gathering place for all of the above.
- Mimic robotics' mimic-video: An open-source video-to-action model with 10x sample efficiency over traditional VLAs.
This matters for two reasons. First, a robotics startup doesn't need to spend tens of millions pre-training a foundation model: they can take GR00T or π0 and fine-tune it with their own robot's data. This is what Unitree, EngineAI, Booster, Galbot, and dozens of smaller Chinese companies do. It's why a company with a few hundred employees can produce a talking, walking, shirt-folding humanoid: they're standing on the shoulders of an open stack.
Second, open-source models are the only realistic path to safety. If a fully closed model runs inside a robot on some factory floor, with zero external visibility into its reasoning, that's a regulatory nightmare. Open models let auditors, researchers, and operators actually inspect what the robot was trained on.
Eight: What's Still Broken
If you've seen enough robot demo videos, you've also seen plenty of robot fail videos. The current generation of LLM+VLA robots is genuinely impressive but also genuinely limited. Here's what's broken:
- Mid-task recovery. VLAs handle unexpected variation better than anything before. But when things truly go wrong (mis-grab, object rolls, human walks into workspace), getting back on track is still weak. Robots will mindlessly repeat failed actions.
- Sample efficiency. Training a VLA from scratch requires tens of thousands of hours of teleoperation data. A human learns to use a new tool in minutes. This efficiency gap is huge.
- Cross-embodiment generalization. A model trained on a Franka arm in a Stanford lab doesn't perfectly transfer to a Unitree humanoid in a Shenzhen warehouse. The bodies are different.
- Long-horizon tasks. Any behavior requiring over 30-60 seconds of coherent action with multiple sub-goals tends to drift. "Make me breakfast" remains out of reach.
- Physical common sense. VLAs are trained to imitate, not to understand. They don't truly understand that knocking over a cup of water will spill it. They've just seen examples and predict what happens next via pattern matching.
- Spatial reasoning. Despite being multimodal, they are surprisingly weak at tasks like "go around the obstacle, not through it" or "stack these things without toppling."
This final cluster of weaknesses is driving the field to bet on a very different kind of model.
Nine: World Models
Imagine this: Instead of training a robot to predict actions, train it to predict the consequences of actions.
A world model is a neural network that, given the current world state (often a video or sequence of frames) and a proposed action, predicts what the world will look like next. Simply, think of it as a learned video predictor with a steering wheel. You show it the last second of camera feed and say "robot moves arm forward 10 cm," and it generates a realistic video of what the next second will look like.
Why is this important?
Because once you have a world model, the robot can think before it acts. It can imagine three or four different candidate actions, predict their outcomes, score them, and pick the best one—all before any motor moves. This is how a chess engine works: it doesn't memorize moves; it simulates futures. This capability never existed for physical robots before because we never had a model accurate enough to simulate the messy real world.
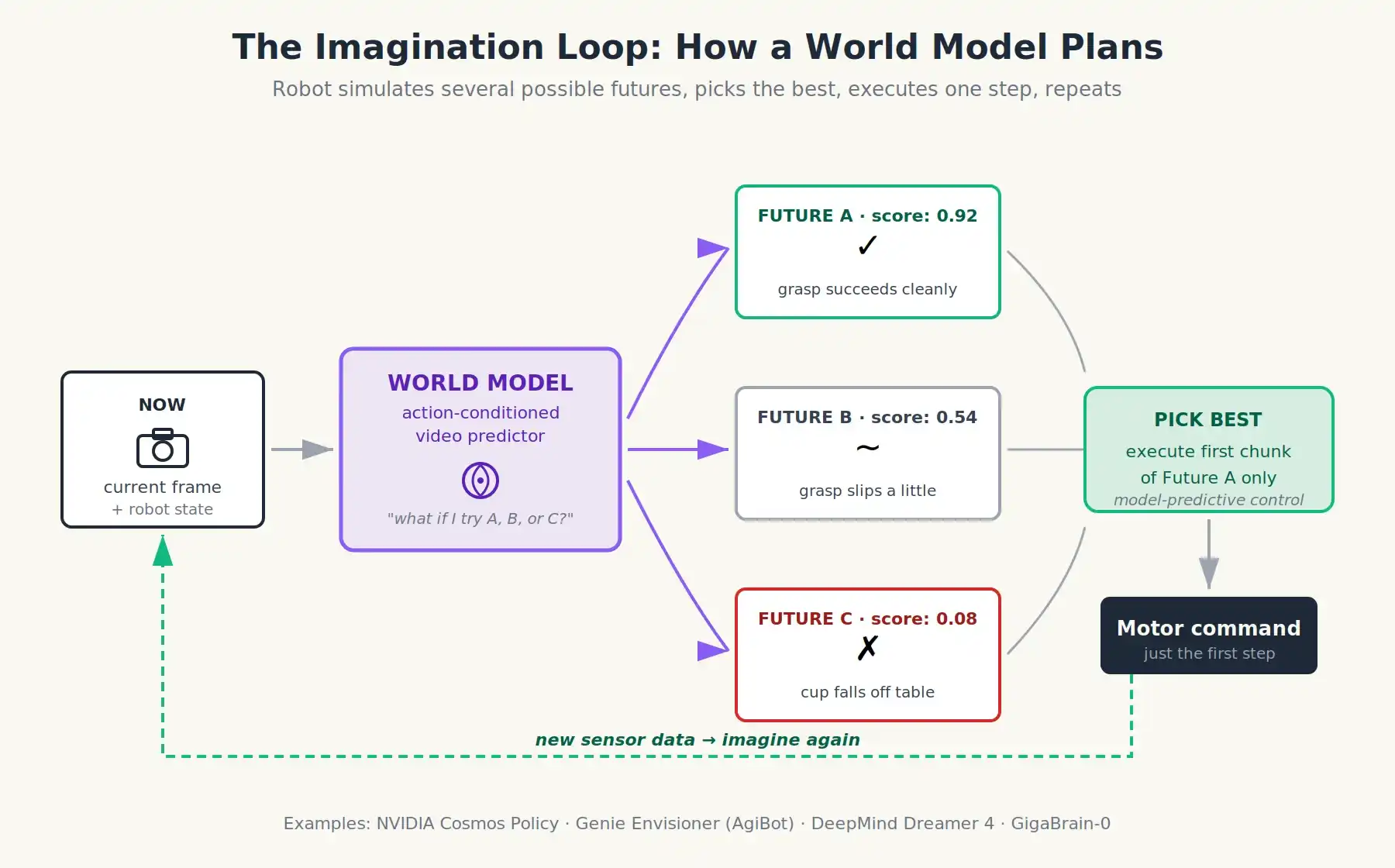
World models let a robot simulate multiple possible futures, score them, and pick the best one before any motor moves
What does a world model look like in 2026?
The state-of-the-art world models are diverse but rapidly evolving. Here are a few:
- NVIDIA Cosmos: A suite of open-world foundation models, including Cosmos Predict 2.5 (generative), Cosmos Transfer 2.5 (controllable simulation), Cosmos Reason 2 (vision-language reasoner for robotics), and the newest Cosmos Policy, which goes further by fine-tuning the world model to output actions for control directly. Cosmos is trained on hundreds of thousands of GPU-hours of video data (Cosmos Predict 2.5 is the world model in this family).
- DeepMind Genie 3: An interactive world model that can generate fully navigable environments from text prompts at 24 fps, running stably for minutes. Initially built for game environments.
- Meta V-JEPA 2: Pretrained on over a million hours of web video, then action-conditioned with just 62 hours of robot video. Achieves 80% zero-shot pick-and-place success on real robot arms across different labs with no task-specific training. The "JEPA" approach is architecturally distinct from others.
- DeepMind Dreamer 4: Learned to collect diamonds in Minecraft (a 20k-step task) using only offline data, no environment interaction. Proof that real reinforcement learning in imagined worlds is possible.
- AgiBot's Genie Envisioner: A unified world model platform from China, trained on over 3,000 hours of real-world humanoid operation video. It can generate both predicted rollout trajectories and executable action trajectories. AgiBot uses NVIDIA Cosmos Predict 2 as a backbone, fine-tuned with its own data. This is exactly the "open stack + own data" pattern described earlier.
- Toyota Research Institute's Cosmos-based world model: For teleoperation data augmentation and navigation.
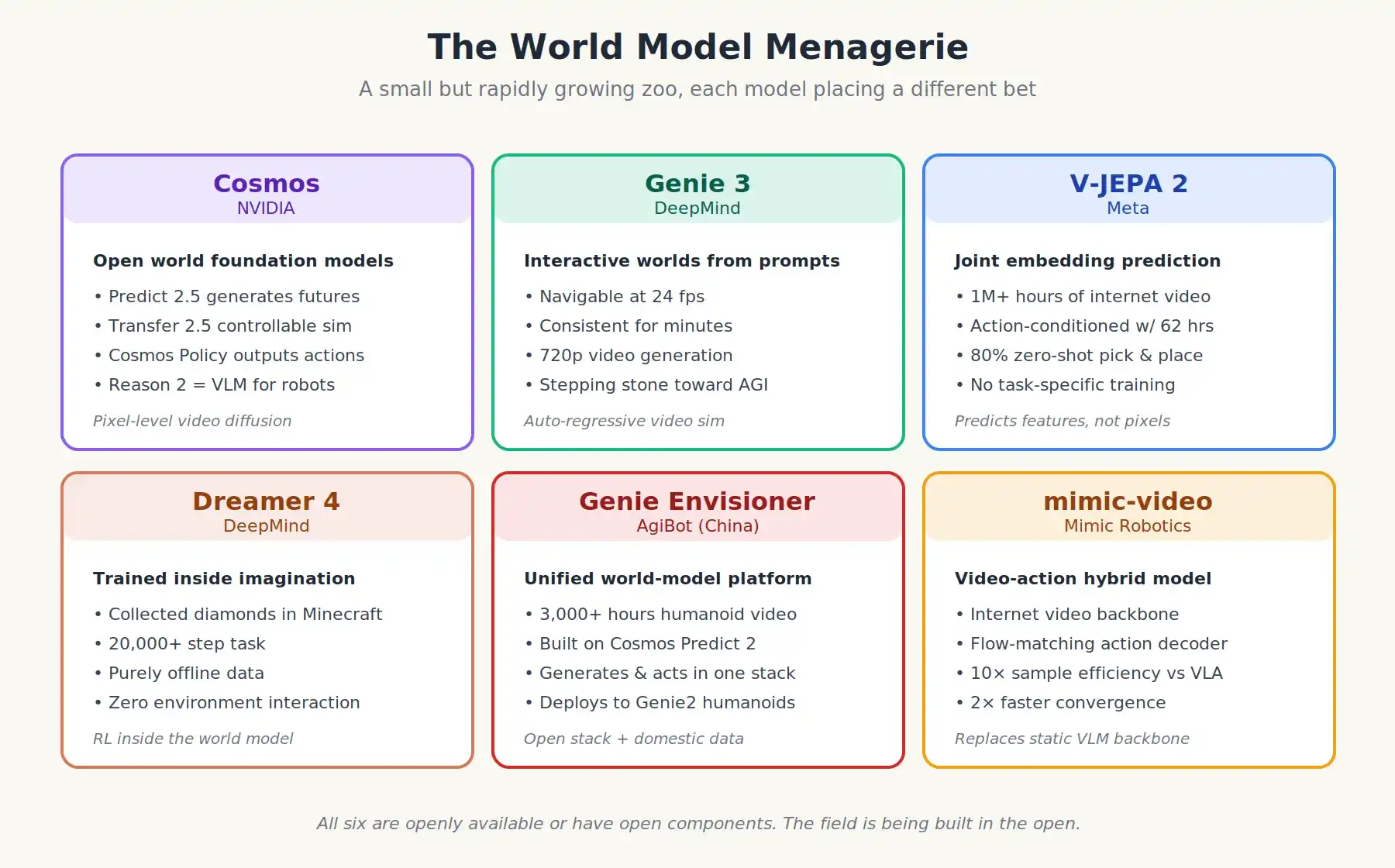
Six most important world models 2025-2026, each proposing a different idea about how machines should learn physics.
Ten: Alternative Architectures, Because the Field Isn't Settled
There's no standard way to build a world model. The architecture war is one of the most interesting debates in AI right now, directly impacting what robots will be able to do. Three camps to watch:
Pixel-level video diffusion (Cosmos/Sora school): Use diffusion models to predict the actual pixels of future frames. Pros: doubles as a synthetic data generator, can render novel robot demos that never happened. Cons: expensive, sometimes unphysical, and predicting pixels you'll never see is wasteful.
Joint-Embedding Predictive Architecture, JEPA (LeCun school): Don't predict pixels; predict the abstract representation of the next frame. Discard texture details, keep the semantic essence of what's in the scene. Pros: efficient, focused on what matters for action. Cons: harder to use. V-JEPA, V-JEPA 2, and new JEPA-VLA hybrids explore this space.
Latent action world models (Genie/Dreamer school): Learn how to compress whole videos into a latent "action language" that captures behavioral structure, then train the world model to predict the next latent state given the next latent action. Pros: lets you train on web video with no actions, then add a small amount of real robot data. Cons: latent actions are uninterpretable to humans, complicating safety analysis.

Pixel diffusion, JEPA, and latent action: same goal, wildly different ways to build a world model
Eleven: World-Model-Based Robots in Practice
If you fast-forward a few years, the architecture of a frontier humanoid robot might look like this:
A VLA with a world model riding on top. When the robot encounters a new situation, it does something like:
- VLA proposes a few candidate next actions (it's still the policy).
- World model takes each candidate action and simulates 1-3 seconds of imaginary video.
- Value critic scores based on imagined outcomes: cup grasped? something fell? human bumped?
- Robot picks the highest-scoring action and executes only its first part.
- Real sensor data flows back; loop repeats.
This is model-predictive control, a technique used for decades to stabilize rockets and quadrotors, but with a learned world model replacing hand-derived physics equations. Its scalability comes from the world model being pre-trained on millions of hours of video, not because someone wrote Navier-Stokes equations for the kitchen.
The benefits compound:
- Improved recovery. If a grasp slips, the world model can imagine multiple corrective paths and pick the most promising.
- Better generalization. A world model trained on web video has seen orders of magnitude more "physics" than any robot teleoperation dataset.
- Controllable long-horizon planning. Plan in imagination, not in reality.
- Smaller sim-to-real gap. Instead of training in a home-built simulator (e.g., Isaac Sim, Newton physics engine) and hoping it transfers, train in a simulator that was trained to match real video. So the gap is smaller.
- Explosion of synthetic data. A world model can generate almost-for-free millions of different robot trajectories across different lighting, materials, and object configurations. This solves the field's biggest bottleneck.
Plus, it has a crucial safety advantage. A robot that can simulate consequences can refuse dangerous actions: not because of a pre-written rule, but because it foresees a human might get hurt.
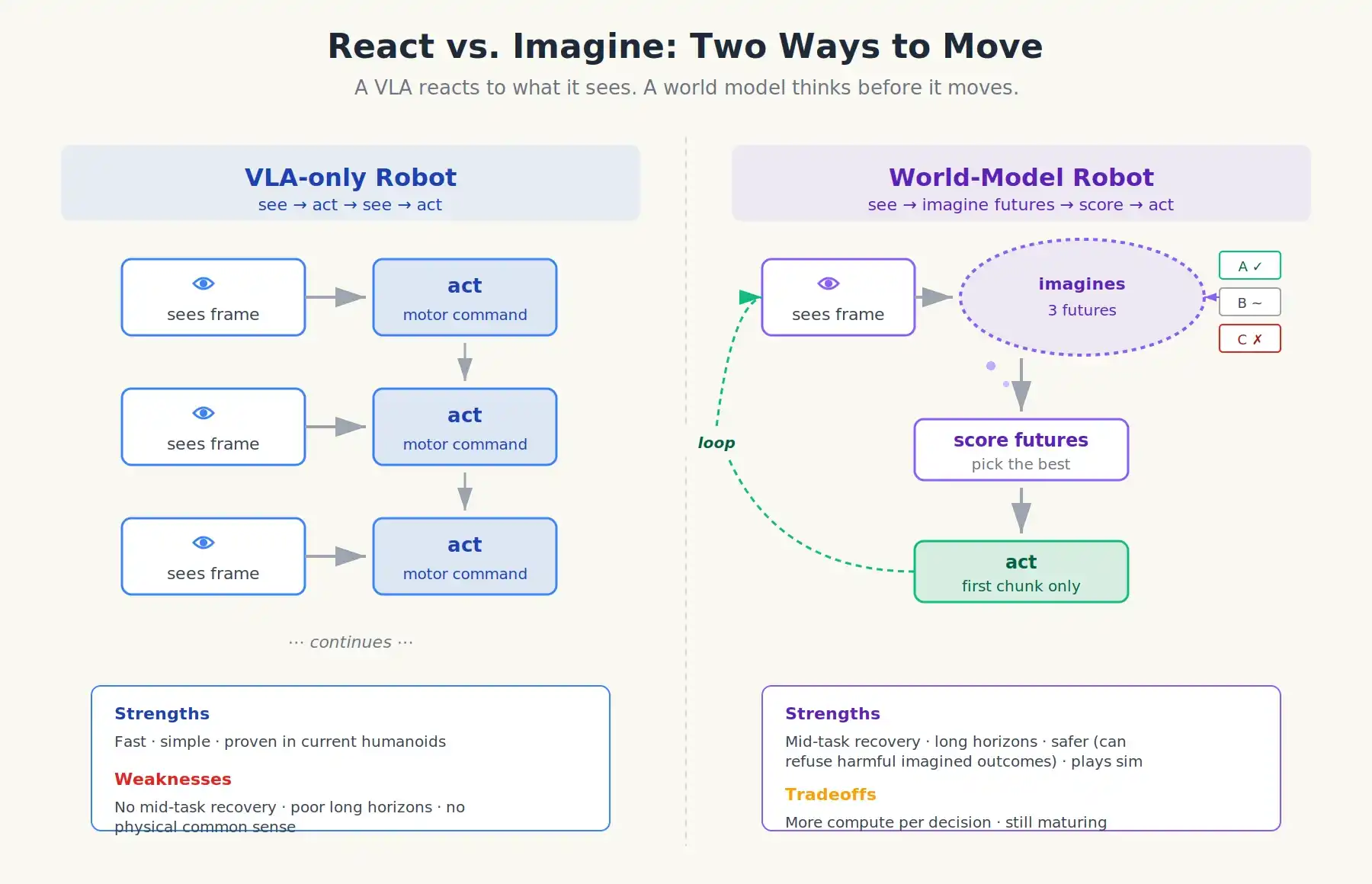
Two ways to move: VLA reacts to what it sees; world-model robot thinks before it moves
Twelve: Things You Should Also Know
Data is the real bottleneck: All the architectural innovation in the world doesn't help if you can't feed the model. Today, teleoperation (humans in VR puppeteering robots) is the primary technical choke point. A robotics company's moat is increasingly its data collection pipeline, not the model itself. AgiBot has warehouses full of operators. NVIDIA's GR00T N1.7 dexterity scaling law shows more human first-person video directly, predictably improves robot dexterity. This is also where China has structural advantages: lower-cost data collection labor, more permissive deployment environments, and state coordination of supply chains.
Simulation is a parallel universe. NVIDIA's Isaac Sim, the new open-source Newton physics engine (v1.0 to be official in April 2026), and the Omniverse platform let companies train robots in millions of parallel simulated worlds without ever deploying in reality. Most of what looks like "robot intelligence" is actually cultivated in simulation and then ported to hardware.
Economics are starting to show. Unitree delivered ~5,500 humanoids in 2025 and targets 10k-20k in 2026. Average price dropped from ~$85k to ~$25k in two years. Unitree's R1 is $5,900. Noetix Bumi is launching at $1,400. Humanoid hardware is approaching consumer electronics pricing while the AI inside still lags the demos. That gap will close, and when it does, volumes will shift the entire industry.
Failure modes look weird. When LLM-based robots fail, they fail in ways traditional robots can't: confidently doing the wrong thing, "hallucinating" capabilities, getting stuck in dialogue loops with their own planner. The traditional robotics world is quite skeptical, and rightly so, insisting learned systems must be safety-monitored and behavior-bounded. The most reliable deployed robots today are hybrids: VLA brains inside hand-designed safety cages.
The "ChatGPT moment" narrative is a useful but misleading metaphor: Jensen Huang keeps telling everyone the ChatGPT moment for robots is here. He says that because NVIDIA sells shovels and picks. The more honest version is: we're roughly in the GPT-2 era for physical AI. It's powerful, it wows you; it's not powerful enough for unattended deployment. It's iterating fast, but the breakout moment isn't viral explosion, it's a slow, steady upward slope.
Conclusion

The evolution of Unitree's quadrupeds (right to left)
In the demo seen at Unitree's office, five G1 humanoids performing kung fu were meticulously choreographed, fine-tuned with an onboard VLA-style controller, and overseen by teleoperators to ensure everything worked. It wasn't fully autonomous at its core. But the entire pipeline: perception, planning, motion control, is being replaced by neural networks. Two years from now, the same robots will do the same routine without choreography because they've pre-imagined the whole routine and picked the best version.
The entire progression this article describes—from hand-coded controllers to learned perception to LLM planners to VLAs to dual-system architecture and eventually to world models—is actually the slow migration of where robot intelligence lives. It started in the engineer's head, then moved to hand-written code, then into the perception layer, into the planner, into the policy. And now it's finally moving toward the model that learns the world itself.
Each shift makes robots more general, more adaptable, more useful. If the world-model shift works, it will genuinely empower them: enough that the question stops being "what can robots do?" and becomes "what should we have them do?"
Related reading: A Rundown of Over 30 Humanoid Robot Companies: Who Will Stand Out in 2026?