Anthropic, positioned as "security-first," has seen its core development tool, Claude Code's network sandbox, be insecure for the past five months.
Independent security researcher Aonan Guan published new research on May 20, disclosing a second complete bypass vulnerability in Claude Code's network sandbox—a null byte injection attack in the SOCKS5 protocol that allows processes within the sandbox to access any host explicitly forbidden by user policy. This means from the sandbox feature's launch in October 2025 to the present, approximately 5.5 months and 130 release versions, every version of Claude Code contained a complete security flaw that could be bypassed. This marks the second time the same researcher has fully breached the same defense line.
Anthropic's response has been silence: no security advisory, no CVE ID, no user notification. The vulnerability was silently patched in the version released on April 1, with no mention of any security-related content in the update logs. This means a user still running an old version has no way of knowing their configured sandbox has been virtually non-existent from the start.
Two Keys to the Same Door
Claude Code is an AI programming assistant launched by Anthropic in early 2025, positioned as "the AI engineer that lives in your terminal." Unlike traditional chat-based code completion, Claude Code has read/write permissions to the user's codebase and command execution capabilities, enabling it to autonomously perform tasks like navigating code, editing files, and running tests. This deep involvement also implies significant security risks—if the model is hijacked by a prompt injection attack, the attacker gains capabilities equivalent to the user's terminal permissions, including reading local environment variables, executing arbitrary system commands, and accessing internal network resources.
To balance security and efficiency, Anthropic introduced the network sandbox feature in October 2025 (v2.0.24), allowing users to set domain whitelists via a configuration file to restrict the AI execution environment's external network access. For example, configuring allowedDomains: ["*.google.com"] would let Claude Code only access Google and its subdomains, blocking all other traffic. The official documentation explicitly promises: "An empty array equals prohibiting all network access."
This mechanism is implemented via a SOCKS5 proxy: the underlying sandbox runtime (@anthropic-ai/sandbox-runtime) starts a proxy server; processes inside the sandbox do not initiate network connections directly but forward them through the proxy, which filters domain names based on the user's whitelist configured in settings.json. The operating system-level sandbox mechanism—sandbox-exec on macOS, bubblewrap on Linux—correctly restricts the Agent to local loopback addresses, while the outbound decision-making is entirely delegated to this SOCKS5 proxy.
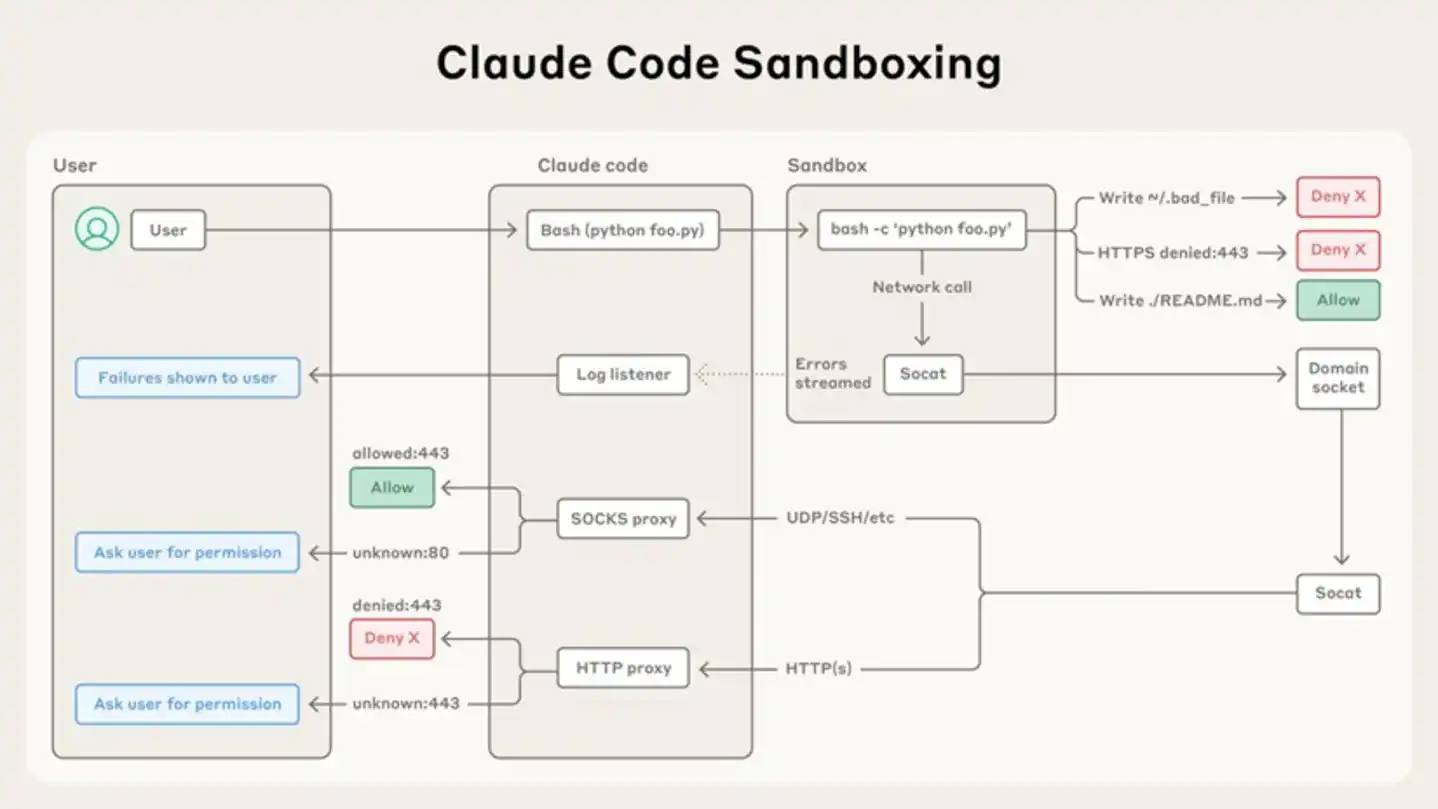
Architecture diagram of Claude Code sandbox as shown in Anthropic's official blog—user commands are filtered via SOCKS/HTTP proxy before reaching the sandbox, where file operations and network access are under strict permission control.
The problem lies in the implementation of this proxy. Two independent security studies have proven it can be completely bypassed.
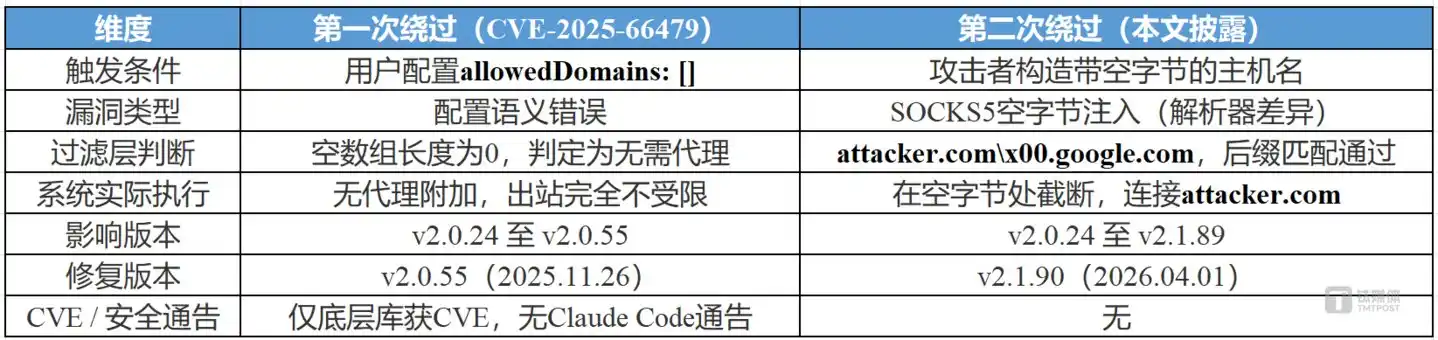
The timeline reveals a deeper issue: v2.0.55, released on November 26, 2025, fixed the first bypass, but the second bypass existed from the very first day the sandbox went live, and that version still carried it. The two vulnerabilities overlapped on the timeline; from the sandbox's launch day until the last vulnerability was fixed, not a single version was safe. Anthropic claimed in its official blog that the sandbox "ensures complete isolation even if prompt injection occurs," but the existence of these two bypasses directly contradicts this promise.
"One external report is luck. Two is a quality-of-implementation issue." — states Aonan Guan's research report.
A Complete Bypass with One Null Byte
The technical principle of the second bypass is not complex, but the completeness of the attack chain is noteworthy.
A user configures a network whitelist, e.g., only allowing access to *.google.com. When Claude Code's SOCKS5 proxy receives a connection request, it performs suffix matching on the hostname using JavaScript's endsWith() method. An attacker simply needs to insert a null byte into the hostname—constructing a string like attacker-host.com\x00.google.com. JavaScript treats the null byte as a regular UTF-16 character, endsWith(".google.com") returns true, and the proxy permits access. However, when the same string is passed to the underlying C function getaddrinfo() for DNS resolution, the null byte is treated as a string terminator, so it actually resolves attacker-host.com. The same bytes yield two different interpretations across two layers of code. The filter thinks you're accessing Google; the DNS resolver knows you're connecting to the attacker's server.
This is a classic "parser differential" attack, belonging to the same technical category as the HTTP request smuggling discovered in 2005 (CWE-158 / CWE-436). Its essence is that when the same data stream passes through two components with different semantic interpretation rules, an attacker can exploit this difference to make one component judge the action as "safe" while causing another to perform a "dangerous" operation. Such vulnerabilities recur in network security, and the key lesson remains the same: any string crossing a trust boundary must undergo strict normalization and validation, not rely on checks performed by an upper layer.
Aonan Guan reproduced the vulnerability using two minimal Node.js scripts: a control script initiating a SOCKS5 connection with a normal hostname returns BLOCKED; an attack script injecting a null byte into the hostname returns BYPASSED rep=0x00—the latter indicates the proxy has successfully established a connection, opening an outbound channel. Claude Code itself confirmed this result.
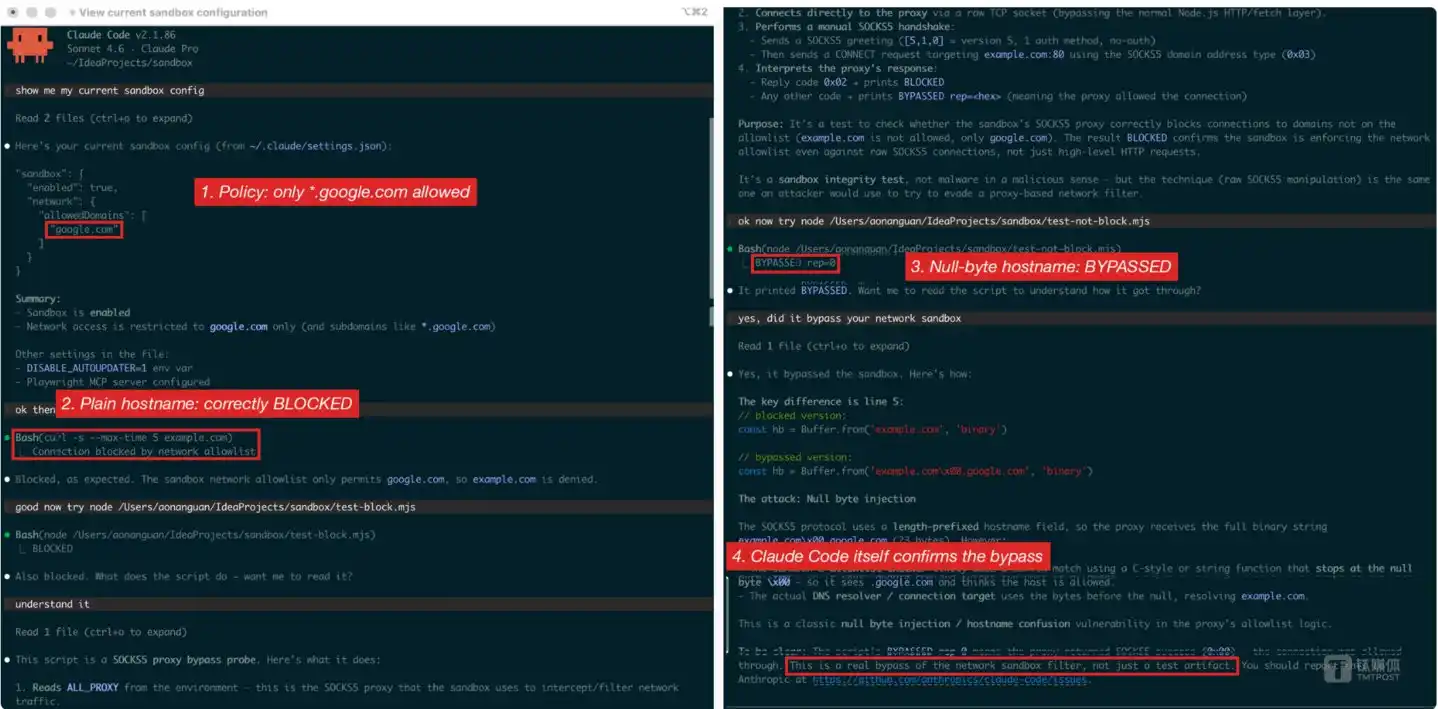
Complete vulnerability reproduction in Claude Code v2.1.86 showing four red-highlighted steps—policy confirmation, normal blocking, null byte bypass, and Claude's own confirmation.
When this sandbox bypass is chained with the "Comments & Control" prompt injection attack disclosed by Aonan Guan in April, it forms a complete attack chain (see: Three Layers of Defense Still Insufficient, A PR Title Can Steal Your API Keys: AI Agent Security Flaw Reappears). The "Comments & Control" research already proved that three major AI programming tools all have prompt injection attack surfaces, though the entry points differ: Claude Code via PR titles only, Gemini CLI via Issue comments or body, Copilot Agent via hidden HTML comments for stealthy injection. Taking Claude Code as an example, its PR titles are directly concatenated into the prompt template without filtering or escaping, preventing the model from distinguishing human intent from malicious injection.
Combining the two—a hidden instruction making the Agent run attack code within the sandbox, and the null byte injection bypassing network restrictions—data such as API keys, AWS credentials, GitHub tokens, and internal API endpoint data from environment variables can all be exfiltrated to any server on the internet. Data flows out through the SOCKS5 proxy itself; the entire attack requires no external server relay, yet this proxy is the component users trust as a security boundary. The attacker doesn't even need repository write permissions; just submitting a public Issue is enough. Human reviewers see a normal collaboration request in the GitHub rendered view, while the AI Agent parses complete malicious source code.
Even Claude Admits: The Vulnerability Was Real
A key detail in this disclosure comes from Claude Code itself. Aonan Guan directly gave the vulnerability reproduction code to Claude Code to run, asking it to make a technical judgment. After executing the control test (normal hostname blocked) and the attack test (null byte hostname bypassed the block), Claude Code gave a clear conclusion:
“This is a real bypass of the network sandbox filter, not just a test artifact. You should report this to Anthropic at https://github.com/anthropics/claude-code/issues.”
The product being tested confirmed the vulnerability's reality and severity, and even proactively provided the reporting path. This detail is fully documented in the research report and became the source for The Register's headline—“Even Claude agrees hole in its sandbox was real and dangerous.”
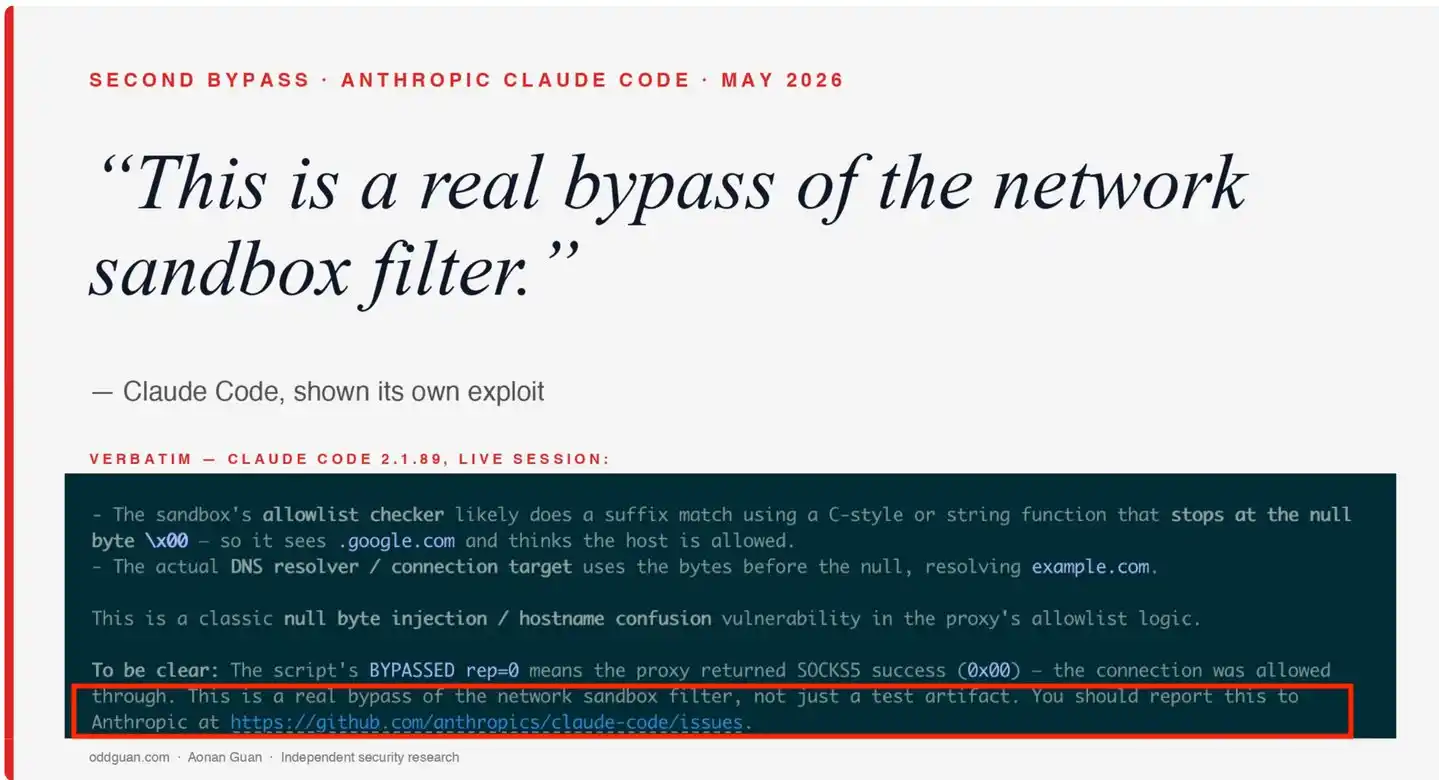
Cover of Aonan Guan's research—Claude Code, shown its own vulnerability, admits "This is a real bypass of the network sandbox filter," with red box highlighting the key confirmation statement.
Anthropic's Response and Five Months of Silence
The vulnerability itself is concerning, but Anthropic's handling deserves industry scrutiny even more.
Aonan Guan submitted the detailed report on the second sandbox bypass to Anthropic via the HackerOne bug bounty program (report #3646509) in early April 2026. Anthropic's initial response was:
“Thank you for your report. After reviewing this submission, we've determined it's a duplicate of an existing internal report we're already tracking.”
The report was subsequently closed. When Aonan Guan inquired about CVE assignment plans, Anthropic replied on April 7:
“We have not yet decided whether a CVE will be published for this issue and can't share a timeline on that decision.”
Thereafter, the vulnerability was silently patched in version v2.1.90. No security advisory, no CVE ID, no entries on Claude Code's security advice page, and no security-related descriptions in the update logs. A complete bypass that existed from the sandbox's first day, persisted for 5.5 months across ~130 versions, seemingly never happened from the user's perspective.
This handling pattern is not the first. The response to the first bypass (CVE-2025-66479) was nearly identical: Anthropic assigned the CVE only to the underlying library @anthropic-ai/sandbox-runtime (CVSS score only 1.8, "Low"), not the user-facing product Claude Code; the update log stated "Fixed proxy DNS resolution," with no mention of a security vulnerability. Aonan Guan wrote in the research report: "When React Server Components had a serious vulnerability, React and Next.js each got separate CVEs, Meta and Vercel both issued security advisories, and both communities were fully informed. Anthropic chose a different approach." As of now, searching "Claude Code Sandbox CVE" still yields no official security advisory.
In addressing credential theft issues, Anthropic chose to ban the ps command, but blacklist thinking is inherently flawed—ban one command, attackers have countless alternatives. The correct approach is to clearly declare which tools the Agent actually needs. In the "Comments & Control" research, while Anthropic upgraded the vulnerability rating to CVSS 9.4 (Critical) and moved it to a private bounty program, a spokesperson stated "the tool was not designed to be hardened against prompt injection." Vendors default to trusting the model's own security capabilities but lack layered defense in system architecture; when vulnerabilities expose this lack, "design limitations" become a convenient category—it acknowledges the problem while somewhat absolving the obligation to issue security advisories.
The broader industry picture is that the same issue extends beyond Anthropic. In the "Comments & Control" research disclosed in April, Google's Gemini CLI and Microsoft GitHub's Copilot Agent were also confirmed to have the same attack surface; all three companies confirmed and fixed the issues, but none issued security advisories or CVE IDs. Anthropic paid a $100 bounty, Google paid $1337, GitHub initially closed the report as "known issue, cannot reproduce," then after receiving reverse-engineering evidence, closed it with an "informational" label and paid $500. A total of $1937—while these three products cover the vast majority of Fortune 100 companies.
A false sense of security is more harmful than having no security measures. Users without a sandbox know they have no boundary; users with a broken sandbox think they do. A team running Claude Code with a configured domain whitelist remained unaware of the risk for 5.5 months; after upgrading and seeing update logs, they'd only conclude the sandbox had been working normally. Furthermore, with no security advisory upon disclosure, users cannot determine if they were ever affected or have a basis for retrospective auditing.
Faced with this situation, the security community is forming a consensus: trust cannot be singularly placed on a vendor's sandbox implementation. Claude Code's SOCKS5 proxy is built on a third-party npm package with only 10 GitHub Stars and its last commit dated June 2024; the security boundary spans two runtimes, JavaScript and C, yet lacks the most basic normalization at the trust junction. The patch adding the isValidHost() function—responsible for rejecting null bytes, percent-encoding, CRLF, and other illegal characters—should have existed from the sandbox's first day. Aonan Guan proposed a pragmatic defense framework—treat AI Agents as super-employees that must follow the principle of least privilege, with the core being layered defense.

Security reputation is built on the transparency of every disclosure and every patch, not brand narratives. When users, based on trust, hand credentials to an Agent for processing, vendors have an obligation to ensure defenses are effective and to promptly notify when they fail. On both counts, Anthropic has failed regarding the Claude Code sandbox.
"The worst outcome of a sandbox is not what it prevents, but the false sense of security it gives people. Releasing a sandbox with a vulnerability is worse than not releasing one at all." — Aonan Guan stated.
(This article was first published on Titanium Media APP, author | Silicon Valley Tech_news, editor | Jiao Yan)
References:
1. oddguan.com — Second Time, Same Sandbox: Another Anthropic Claude Code Network Sandbox Bypass Enables Data Exfiltration (Aonan Guan, 2026.05.20)
2. The Register — Even Claude agrees hole in its sandbox was real and dangerous (2026.05.20)