"K2.6 is our strongest code model to date," Kimi wrote on its official account.
On the evening of April 20th, Kimi officially launched the open-source model K2.6, which demonstrates stronger programming and Agent capabilities, about a quarter after the release of version K2.5.
There was also a minor episode: rumors suggested that DeepSeek V4 would be released this week. If everything proceeds as expected by the outside world, this would be the Nth time Kimi and DeepSeek have coincided. But at a more fundamental infrastructure level, there is an underlying thread: Kimi and DeepSeek, these two large model startups, are ultimately destined to step into the same river—advancing together with domestic chip startups.
Rewind to March 2026, when Yang Zhilin took the stage at NVIDIA's GTC conference to discuss Kimi's technical roadmap. He said, "Many of the commonly used technical standards today are essentially products from eight or nine years ago, gradually becoming a bottleneck for Scaling."
To address such issues, Kimi has contributed to the open-source community the first large-scale application of the second-order optimizer MuonClip, the Kimi Linear architecture that makes large models more efficient at processing long contexts, and Attention Residuals, which optimizes the connections between deep neural network layers.
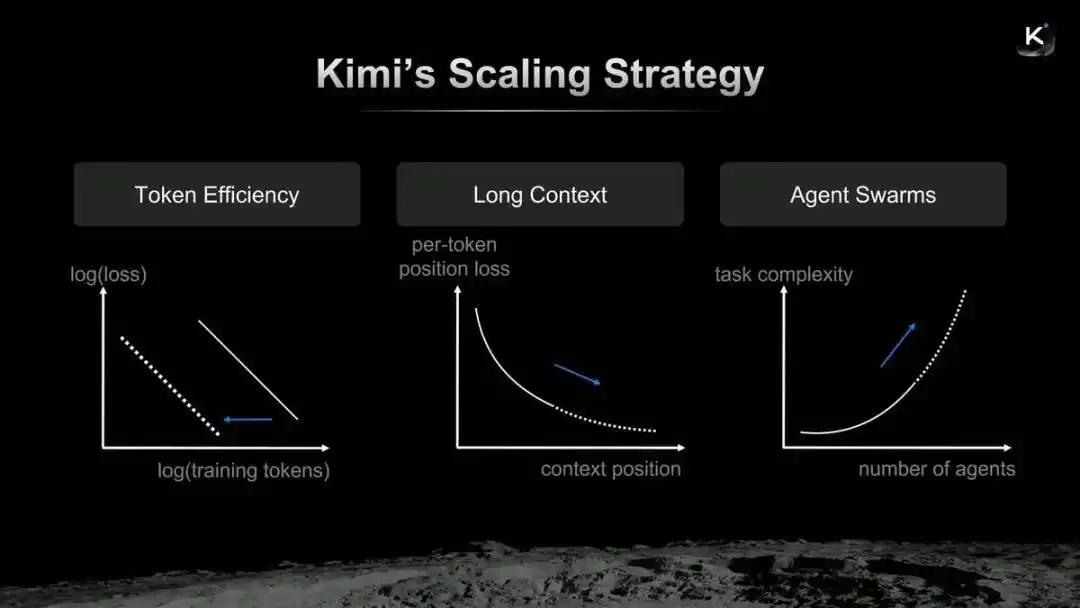
Kimi's Scaling Strategy
Yang Zhilin believes that Kimi's evolution logic can be summarized as the "merger" of Token efficiency, long context, and Agent clusters. The newly launched Kimi K2.6 can be understood as a new assignment submitted by Yang Zhilin along this Scaling path.
Kimi's official website has integrated K2.6
Code, Agent, and What Else?
As one of the most easily standardized capabilities, code is a must-win area for cutting-edge models.
From K2 to K2.5 to K2.6, Kimi has maintained an iteration rhythm of about one quarter on several open-source models. However, since this is a minor version number, it hints that Yang Zhilin may have more cards up his sleeve.
"K2.6 has significantly improved long-range coding capabilities, able to code uninterrupted for 13 hours in tests, writing or modifying over 4,000 lines of code," Kimi wrote in a promotional material. "On the Kimi Code Bench, Kimi's internal strict code evaluation benchmark covering various complex end-to-end tasks, K2.6's score improved by about 20% compared to K2.5."
It's worth noting that K2.5 was already a very "capable model," topping the OpenRouter charts in February. A source close to Kimi posted a screenshot of co-founder Zhang Yutao's朋友圈 at the time, saying, "He seemed very satisfied with this version."

K2.6's performance on general Agent, programming, and visual Agent benchmarks
For Agent frameworks like OpenClaw and Hermes, K2.6's core improvements focus on the accuracy of API calls and the stability of long-running operations—one enhances the cost of task execution, while the other optimizes the efficiency of task execution.
In the K2.5 version launched in January, Kimi introduced the concept of "Agent clusters," breaking down a task into multiple sub-tasks and automatically assigning them to different specialized Agents for processing, thereby reducing task processing time and avoiding the risk of entire project failure under serial task flows.
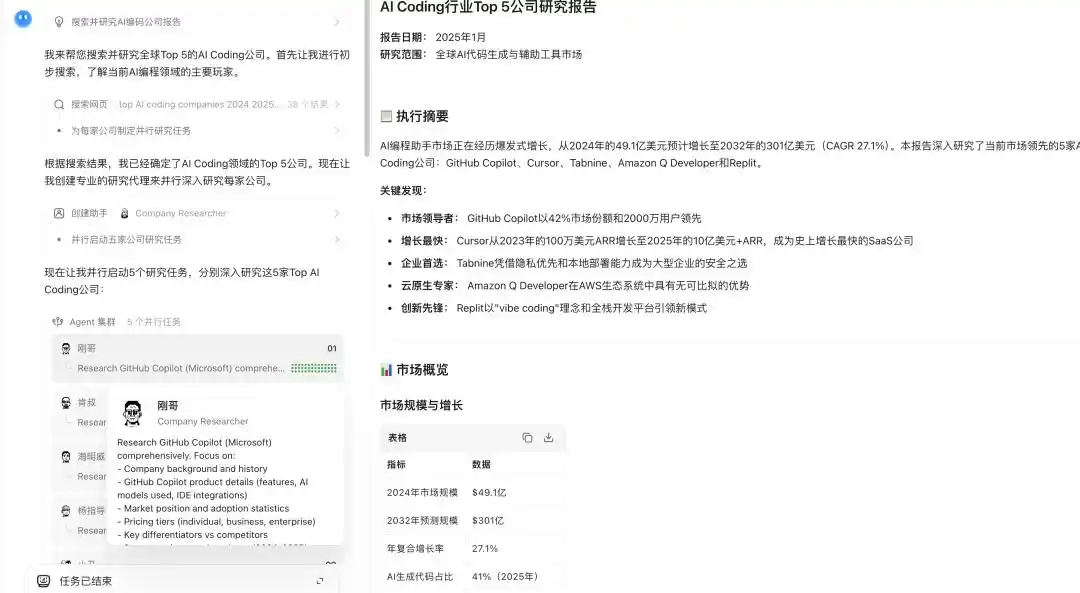
Demonstration of Kimi K2.6's Agent cluster capability
In the new K2.6 version, this capability is further amplified, integrating and parallelizing breadth search with in-depth research, large-scale document analysis and long-form writing, and multi-format content generation, supporting up to 300 sub-Agents completing 4,000 collaborative steps in parallel.
To summarize the highlights of Kimi K2.6 in one sentence, they大致包括: evolution in code and long-range task capabilities, evolution of Agent cluster capabilities, and optimization for mainstream Agent frameworks.
If I had to pick a personal preference from the above features, I believe the Agent cluster is the most valuable capability—it directly embodies the explosive power of parallel computing. Whether it's code or the stability of long-range tasks, these are things that model iteration must address. More importantly, based on these capability improvements, they drive innovation in Agent working methods, efficiency, and even interaction modes.
After all, as a user, what I want is not for it to tell me what it can do, but for it to drive Agents to solve my real problems and form effective productivity.
When K2.5 was launched, an academic researcher began using this model for scientific research projects. His evaluation at the time was that it had no weaknesses and could serve as a research assistant.
"The multi-Agent provided by the official is indeed effective; many domestic Agents last year were still toys."
If Kimi K2.5 received positive evaluations both internally and externally, how effective will K2.6, which goes a step further, be?
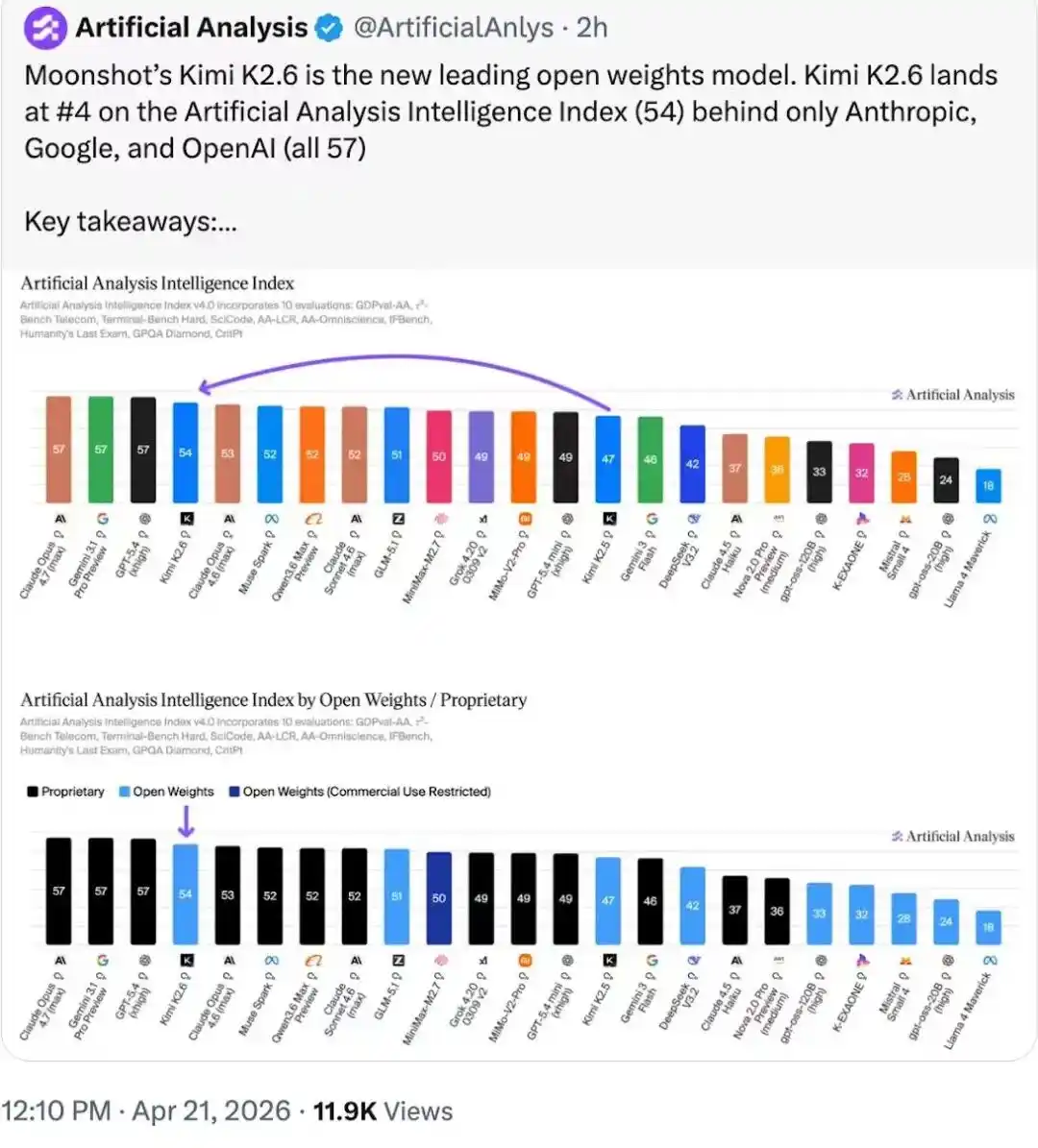
On the Artifacial Analysis intelligence leaderboard, Kimi K2.6 ranks仅次于 three closed-source models and leads the open-source model weight leaderboard
The "New Story" in the Roadmap
Kimi always occasionally brings something new to the industry, including the MuonClip, Kimi Linear, and Attention Residuals mentioned in Yang Zhilin's roadmap speech. Some explorations have also received positive recognition from industry top players.
In mid-March, Kimi published a paper on Attention Residuals, proposing the use of attention mechanisms to改造残差连接. Musk directly tweeted that this was "an impressive breakthrough by Kimi."

Last weekend, Kimi published a new paper titled "Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter" (PrfaaS, Prefill-as-a-Service), mentioning Kimi's new exploration in architecture,核心讨论的仍然是 PD separation (Prefill and Decode).
PD separation is not a new topic—the Prefill stage of model inference is a computationally intensive task, while the Decode stage relies on memory bandwidth, with memory repeatedly reading and writing KV Cache. This architecture aims to decouple compute-intensive tasks from bandwidth-intensive tasks, improving compute utilization and throughput, thereby reducing costs and increasing efficiency.
Although PD separation is good, there is a sticking point: it must be based on RDMA high-speed networks within the same data center.
The core point of Kimi's PrfaaS paper is: based on a hybrid model (Kimi Linear), it significantly reduces the KV cache size, and then completely decouples Prefill and Decode into different heterogeneous clusters.
The experimental example mentioned in the paper shows that the PrfaaS dedicated prefill cluster uses 32 H200 GPUs focused on high compute power; the local PD decoding cluster uses 64 H20 GPUs interconnected via RDMA internal network; the two clusters are connected via VPC dedicated line, with a total cross-cluster bandwidth of about 100Gbps. The test model is a 1T parameter Kimi Linear hybrid attention model.
Actual test results show that the PrfaaS-PD cross-data center solution, compared to the 96-card H20 same PD cluster solution, improves throughput by 54%, reduces P90 TTFT (the waiting time for 90% of users from sending a request to seeing the first character returned) from 9.73s to 3.51s, a reduction of 64%, and the cross-data center KV cache transmission bandwidth only占用 13% of the total 100Gbps bandwidth.
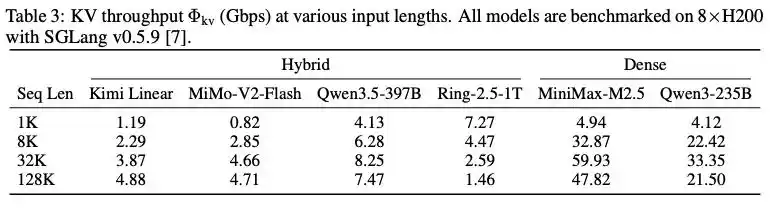
Comparison of KV throughput between hybrid architecture models and dense models under different context lengths
To demonstrate the advantages of the hybrid model architecture, the paper mentions a set of experiments: under an 8-card H200 and SGLang v0.5.9 inference framework, benchmark tests were conducted on several mainstream models. At a context length of 32K, the KV throughput of the MiMo-V2-Flash model using hybrid attention was only 4.66Gbps, while the similarly scaled dense attention model MiniMax-M2.5 reached 59.93Gbps, directly proving that the hybrid attention architecture can reduce KV cache transmission requirements to within the range manageable by ordinary Ethernet.
"Cross-data center + heterogeneous hardware unlocks the potential to significantly reduce per-token cost," Kimi said on its official account.
Regarding token cost reduction, I mentioned in the article "The People Miss DeepSeek" that there is room for optimization at both the model and hardware levels. Professor Hu Yanping from Shanghai University of Finance and Economics specifically posted a朋友圈, emphasizing that cost reduction cannot rely on DeepSeek alone. "The solution depends on the cost efficiency of compute power supply,跨代提升 of model quality, continuous advancement of intelligence paradigms, and the放大效应 of workflow and scenario integration."
From this perspective, Kimi has told the industry a new story about token cost reduction.
Chinese Models Summon Chinese Chips
In the Prefill-as-a-Service paper, more people only noticed the cross-data center narrative, while overlooking the point about heterogeneous hardware.
It is important to note that H200 and H20 are still based on the Hopper architecture in terms of chip design. The heterogeneity mentioned in the paper refers to heterogeneity in bandwidth and compute power. Its启示 is: we can use一部分 compute-powerful domestic cards for Prefill, or bandwidth-strong domestic cards for Decode, and of course, they can also be mixed with overseas cards to achieve cost reduction and efficiency improvement.
It can be said that this is a door opened by Kimi for Chinese chips in large model inference.
In the view of a domestic compute power insider, to catch this wave of traffic benefits brought by the Prefill-as-a-Service solution, they still have to face the old problem of ecosystem.
Over the past few years, Chinese large models have been stuck outside domestic compute power due to ecosystem challenges, but there is another unnoticed detail: products like the H20 have been断供 for a year. In other words, in the short term, there is only one option for inference chips: domestic.
As inference demand surges, compared to supply, ecosystem challenges will switch to secondary issues—the dependence of Chinese large models on domestic compute power has changed from optional to不得不使用. Because of this, many predictions are discussing that DeepSeek V4 is adapting to domestic compute power.
In my article with Professor Hu Yanping, "The Last Urging Letter to DeepSeek," we said that adapting to domestic compute power is a very difficult road for domestic models, but in the longer term, it has to be done. Something that must be done always needs a starting point, and perhaps DeepSeek V4 is that starting point.
Now, DeepSeek V4 has not yet arrived, but Kimi has already used its own practice to explore a feasible path for the combination of Chinese models + Chinese chips.
Kimi has taken the lead as a model representative in extending an olive branch; the problem now lies with domestic chip startups.
Does everyone remember Huang Renxun's reaction when asked about the chip export ban to China in the latest episode of "the Dwarkesh Podcast"? He said that chips are not uranium enrichment, and禁售 cannot stop the progress of Chinese chips; they can still develop models by暴力堆叠 domestic chips.
Why did Huang Renxun say this? The next step for DeepSeek and Kimi is the standard answer.
This article is from the WeChat public account "Tencent Technology," author: Su Yang, editor: Xu Qingyang





