The AI world was jolted by a sudden thunderclap!
Anthropic has issued a warning to all humanity: Stop researching AI!
Internal data from Anthropic indicates that AI is accelerating the development of AI, and a path towards recursive self-improvement may have emerged.
In other words, AI is approaching the tipping point of "building itself."
This process is faster than Anthropic anticipated, prompting them to call for a slowdown or pause in AI research.
Meanwhile, Yann Dubois, leader of OpenAI's post-training team, offered a more micro, yet equally thought-provoking perspective in a recent interview:
AI Evolution Isn't About Suddenly Cheating, It Just Passed the Pass Mark!
In his latest interview, he revealed several internal perspectives:
The growth of AI capabilities is linear and continuous, but the "usefulness" experienced by users is discrete and jumpy.
Because before reaching a certain "Reliability Threshold," AI is just a clever trick; once it crosses that point, it becomes a reliable worker you can delegate tasks to, initiating self-acceleration.

This threshold, OpenAI crossed around last December.

Furthermore, Yann Dubois made a counter-intuitive assertion: AI development resembles a "Craft" more than a "Science."
This insight holds immense tension: in this field emphasizing raw computing power, what ultimately triumphs is something akin to an alchemist's "flare (intuition/inspiration)."
He also introduced the concept of the "Last-Mile AI Dividend."
If we froze all current models and focused solely on developing vertical applications (Harnessing), we could already achieve AGI.
The bottleneck isn't the model's brain, but in "permissions, connectivity, and data." This directly pours cold water on hesitant developers while simultaneously pointing to where the gold lies.
Reliability Threshold Crossed, AI Self-Accelerates
The past few weeks have been lively in the AI world: GPT-5.5 was released, Claude Mythos also emerged.
Especially in areas like cybersecurity and AI agents writing code, it feels like things are changing daily, and AI progress feels like it suddenly "leaped a grade."
Dubois puts it rather bluntly: Capability improvement has actually been quite continuous. The feeling of being on a rocket stems from a "reliability gate" standing in the middle.
Before crossing that gate, AI is like a smart but unreliable intern: it can write, calculate, and offer ideas, but you wouldn't dare hand over real work to it.
After crossing it, you dare let it "actually get to work."

He estimates OpenAI crossed this line around "last December," leading to the externally perceived "step-change leap."
More stimulating is the second reason: when models become good enough, they accelerate R&D itself.
This is exactly what Anthropic is most worried about.
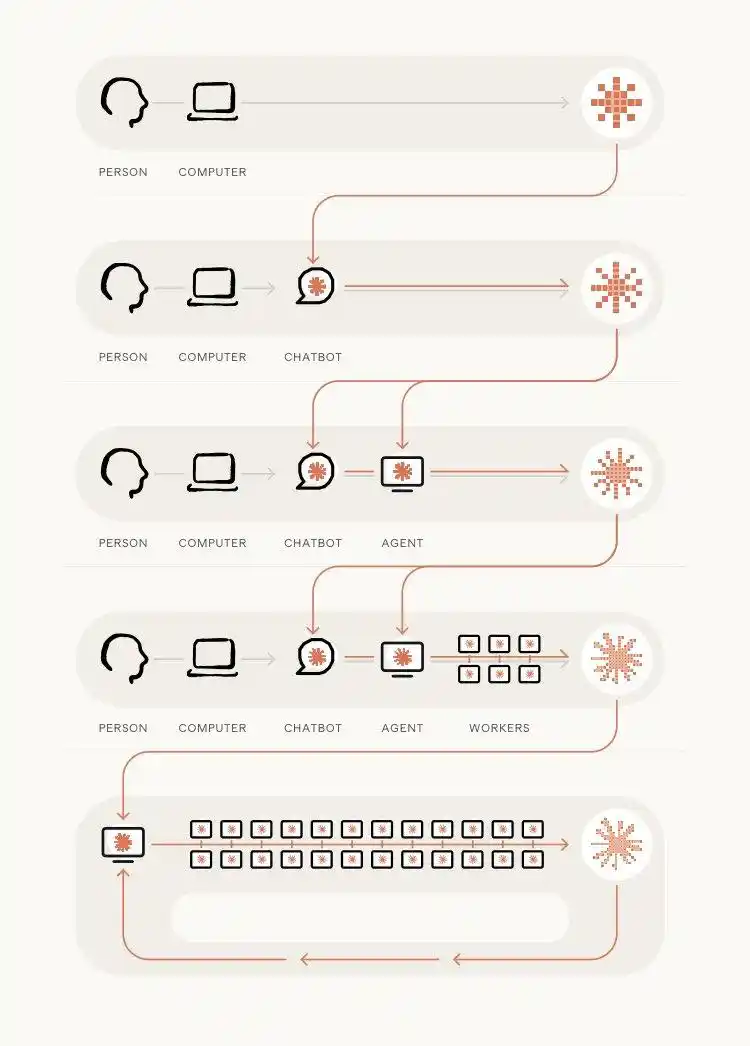
Dubois mentions, particularly in programming scenarios, researchers code daily. When the model gets stronger, it's like the entire team gains a partner that doesn't sleep — helping researchers build their toolchains and "feeding AI with AI" when training the next generation of models.
Once this acceleration loop starts spinning, it spins faster and faster. It's no surprise recent months have felt "increasingly intense."
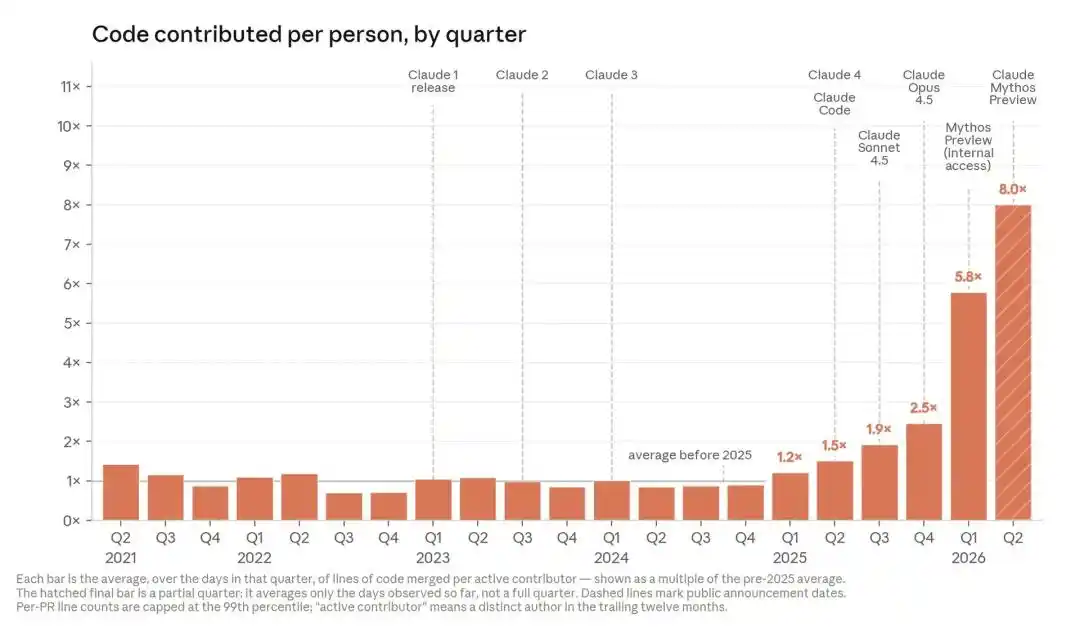
This is also happening inside Anthropic. By Q2 2026, the code contributed per person per quarter was already 8 times that of Q1 2024.
The third driving force comes from the "transformation and upgrade" of Reinforcement Learning (RL).
Early reasoning models like o1 mainly focused on scoring high on tasks with "verifiable rewards" — math problems, programming contests, because right/wrong was clear, and rewards easy to define.
But over the past year, they've migrated the tools honed in competitions to more real-world, ambiguous work scenarios: no longer just optimizing for "problems with standard answers," but optimizing for "things users find genuinely useful."
In short: evolving from test-takers to workplace professionals.
AI Engineers Aren't Scientists, AI is 'Cultivated'
But once you step into the real world, trouble arises: How do you improve reliability?
Dubois offers a straightforward "probability model":
Given many systems are now AI-agentic, you can roughly think of it as "a certain probability of error every two minutes"; the longer it runs, the higher the chance the final answer goes off the rails.
So-called "improving reliability" essentially means continuously pushing down this "error rate per two minutes."
This is an inherent, tough challenge for AI agents.

This also explains why Dubois says building AI resembles "craftsmanship" more than textbook "scientific experiments."
The realistic process is often: first, use experience, intuition, trial-and-error to build something, even with a touch of "alchemy"; then, once it actually works and is useful, go back and supplement it with more scientific explanations and methodology.
He also mentions a rather ironic anecdote —
When ChatGPT first went public and mentioned using RL, his initial reaction was, "Isn't that too complex? Supervised Fine-Tuning (SFT) should be enough," which was precisely the approach he aimed to validate while working on Alpaca at Stanford.

But later facts showed that once model scale crosses a certain level, RL really does "suddenly start working well," albeit at a high cost — sampling many answers, judging which are right/wrong — requiring significant computing power and systems engineering.
Vertical Harnessing Has Reached AGI
When it comes to "bringing AI into reality," you can't avoid the term entrepreneurs love these days: Harness (orchestration system).
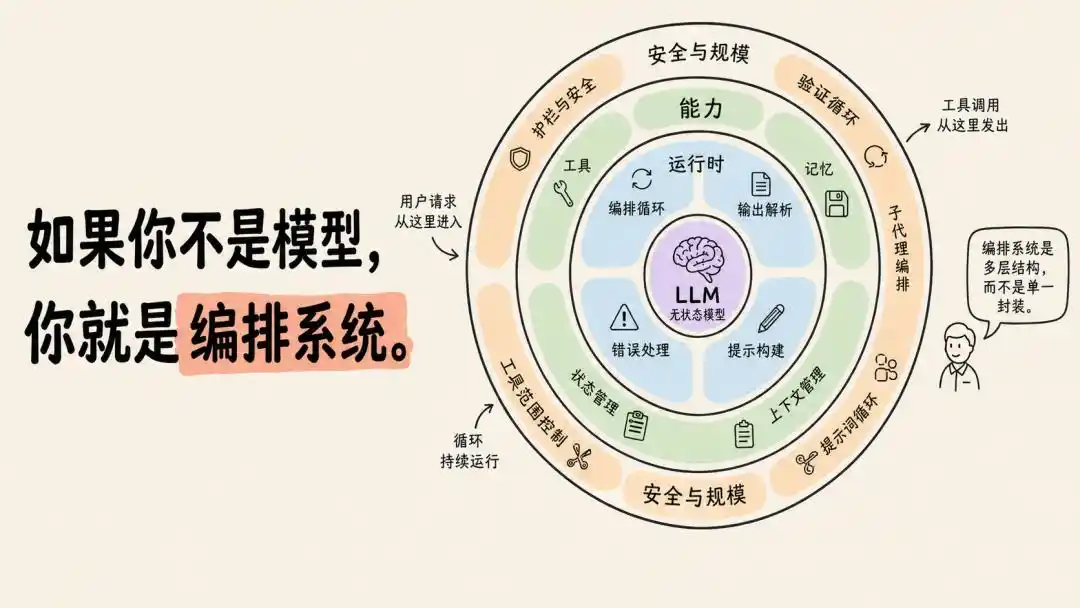
Some see it as the "external skeleton" for AI agents, while others suspect models will eventually "consume" it.
Dubois's stance is pragmatic:
In the short term, vertical-scenario Harnesses are valuable, able to push reliability from 80% to 85%.
But the premise is accepting that models are continuously improving, and Harnesses need constant re-tuning.
Attempting to create a long-term stable, universally applicable "General Harness" is, in his view, essentially a dead end.
He even throws out a provocative judgment: If we "froze" current models today and focused solely on meticulously polishing Harnesses and training around them, many in specific fields might "clearly sense the flavor of Artificial General Intelligence (AGI)."
The Last Mile
But what truly excites and worries Dubois is the perennial challenge of "continual learning."
Three years ago, when ChatGPT first exploded in popularity, he and a friend seriously discussed starting a venture for personalized memory and continual learning.
At the time, they thought, "OpenAI will solve this within 6 months," so they didn't proceed. Three years later, he's now at OpenAI, yet this issue remains unresolved.
The current model's awkwardness lies in this: on day one at a company, it might be more capable than most new hires (high starting point); but afterwards, it largely "stays the same," because it doesn't learn more about you or become more efficient within a specific environment.
The human learning curve climbs upward; AI's curve tends to flatten.
Bending AI's curve from "flat" to "continuously rising" is, in Dubois's view, one of the most important problems ahead.
So, is there still room for startups to build vertical applications?
Dubois's answer is clear: Not only is there room, but it's significant.
Because the real bottleneck often isn't "whether the model is smart enough," but the last mile — how to grant permissions, how to connect data, how to build connectors, how to integrate into specific business workflows.

No matter how high foundation models fly, if they don't land, they're just fireworks. Pulling them down to earth, giving them the right keys, and opening the right doors is the most valuable, grunt work.
References:
https://x.com/Potatoloogs/status/2062494654885749126
https://www.youtube.com/watch?v=DhD1zZ8w8Mw&t=3s
This article is from the WeChat public account "XinZhiYuan" (New AI Era), Author: ASI Apocalypse






