I didn't expect the backlash to come so quickly!!
Just now, UC Berkeley released a brand new benchmark test touted as the "Agents' Last Exam".
It brings today's most powerful AI Agents into the examination hall and makes them do real work—
Building 3D models in Siemens NX, setting up game scenes in Unreal Engine, doing special effects compositing in Adobe After Effects.
The results are astounding:
At the hardest level, the currently recognized strongest models, Claude Fable 5 and GPT 5.5, all scored a big fat zero.
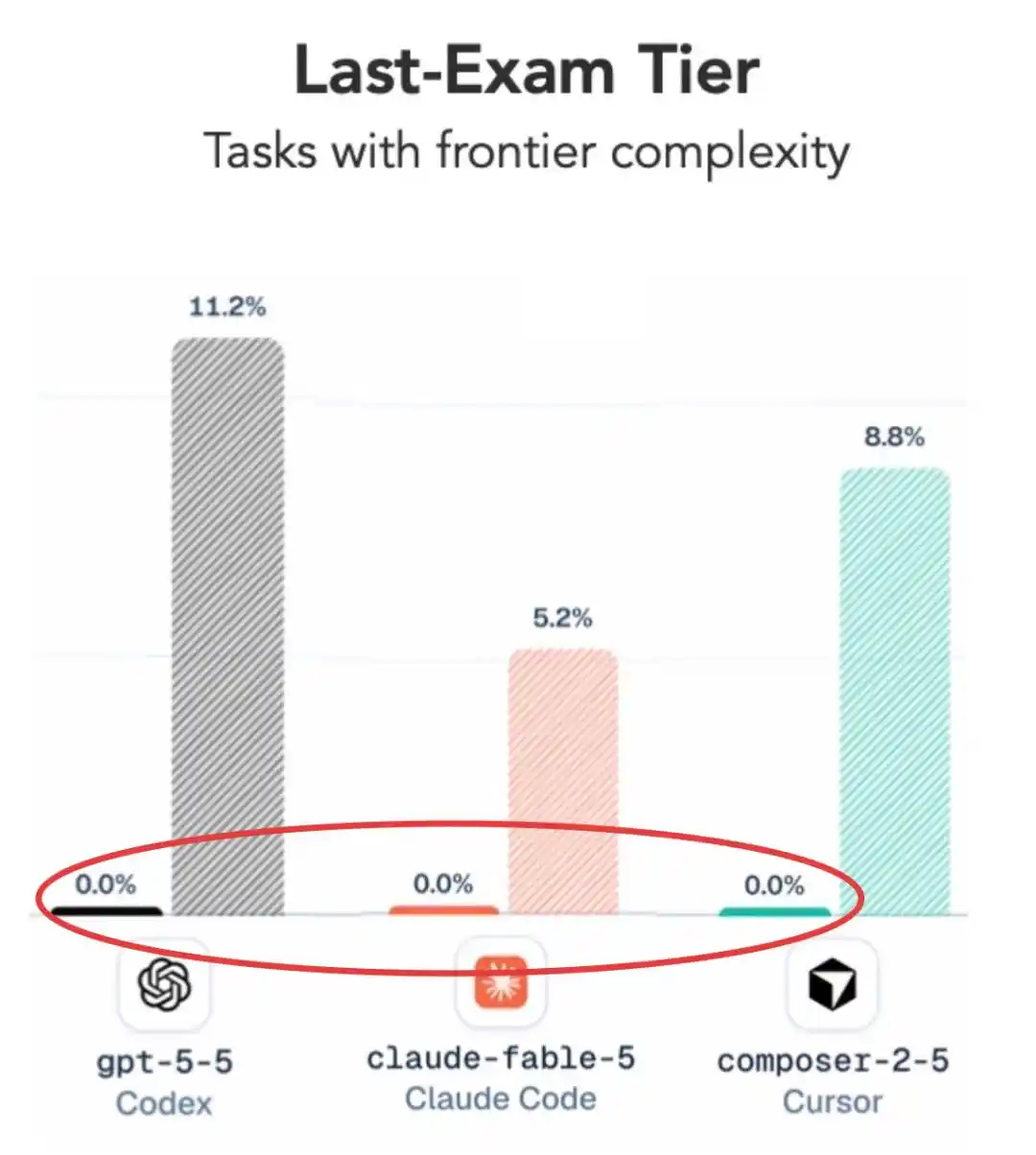
If you lower the difficulty a bit? Scores appear, but the outcome is still quite surprising—
GPT 5.5 actually slightly outperformed Claude Fable 5.
Am I hearing this right? Company A's newly released top model Claude Fable 5 was beaten by GPT 5.5 from a few months ago??
It's worth noting that on almost all mainstream benchmarks before this, Fable 5 had been crushing GPT 5.5—80.3% vs. 58.6% on SWE-Bench Pro, 64.5% vs. 52.2% on Humanity’s Last Exam.
But in this "real work" exam, the situation reversed.
This new benchmark is called Agents’ Last Exam (ALE), and the team behind it is no small player—they are responsible for benchmarks you're familiar with like MMLU, MATH, CyberGym, and ExploitGym.
They probably named it referencing Scale AI's "Humanity’s Last Exam" from before, only this time it's not testing the limits of human knowledge, but the limits of AI Agents doing work.
Honestly, once this evaluation came out, those who were shouting daily that "Agents will replace human jobs" have truly fallen silent...
"Agents' Last Exam", The Winner Turns Out to Be GPT 5.5!
First, look at the complete leaderboard.
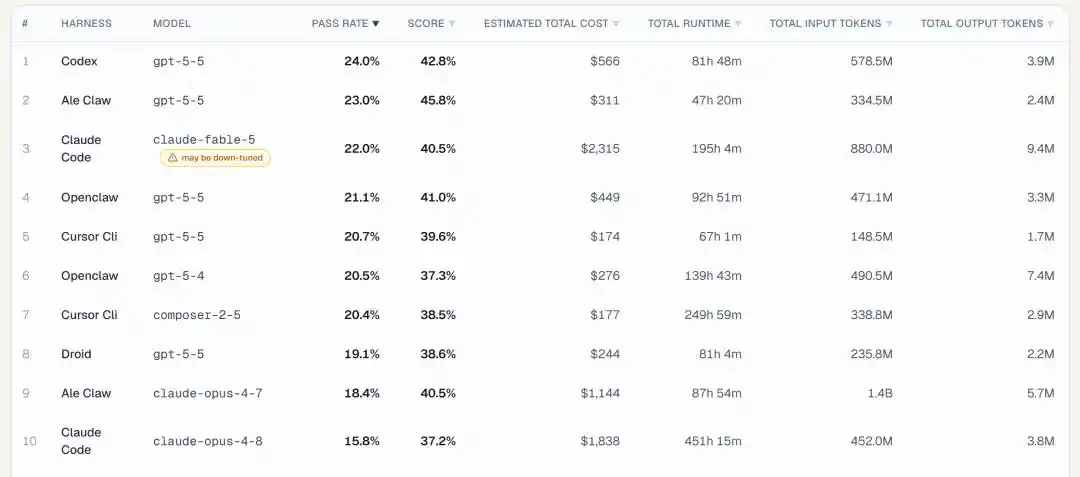
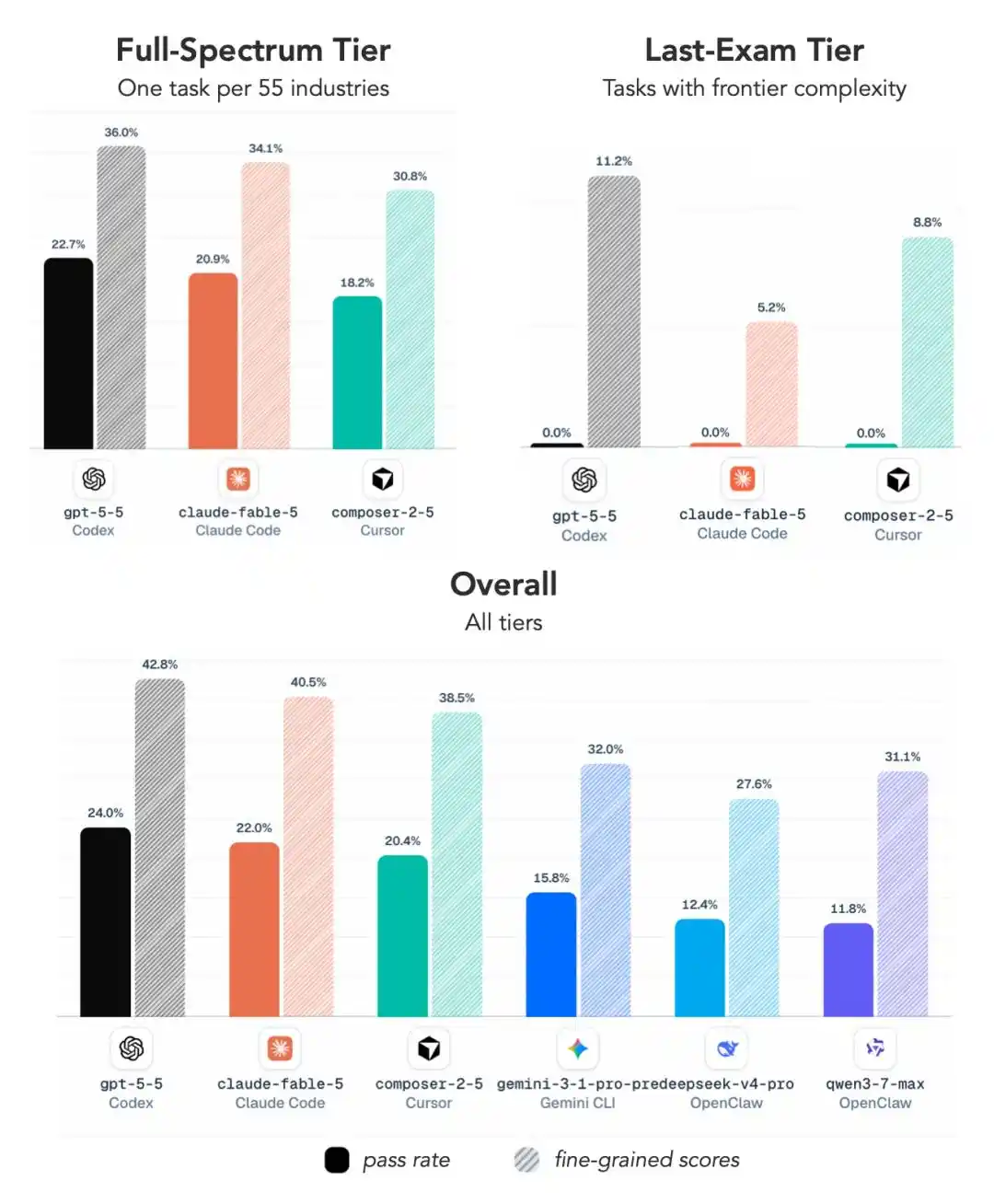
Looking at the core metric of task pass rate, GPT 5.5 directly sweeps the champion and runner-up spots:
1st place is GPT 5.5 paired with OpenAI's own Codex framework, with a pass rate of 24.0%.
2nd place is still GPT-5.5, but paired with the ALE Claw framework, with a pass rate of 23.0%.
(ALE Claw is a baseline Agent written by the team itself, competing alongside commercial frameworks like Codex, Claude Code, and Cursor CLI)
We only see Claude Fable 5 appear at 3rd place—paired with Claude Code, achieving a 22.0% pass rate.

Looking further down is even more interesting.
4th, 5th, and 8th places are all GPT 5.5, just with different frameworks.
GPT 5.5 appears 5 times in the top 10, and combined with GPT 5.4 at 6th place, OpenAI models occupy 6 spots.
And the Claude family?
Fable 5 got 3rd, Opus 4.7 got 9th (18.4%), and Opus 4.8 is at the bottom in 10th (15.8%), the losing trend is obvious.
No wonder OpenAI researchers are celebrating on social media, happily having a festive day:
Besides the scores, there are several signals here worth pondering.
First, the ceiling is shockingly low.
The champion's pass rate is only 24%, and the highest comprehensive score is only 45.8%.
Meaning, even by the most lenient "partial score" calculation, the strongest Agent can only get less than half the points.
And all these tasks come from projects already completed by real human experts—theoretically, the human expert completion rate is 100%.
Second, Claude is burning a shocking amount of money.
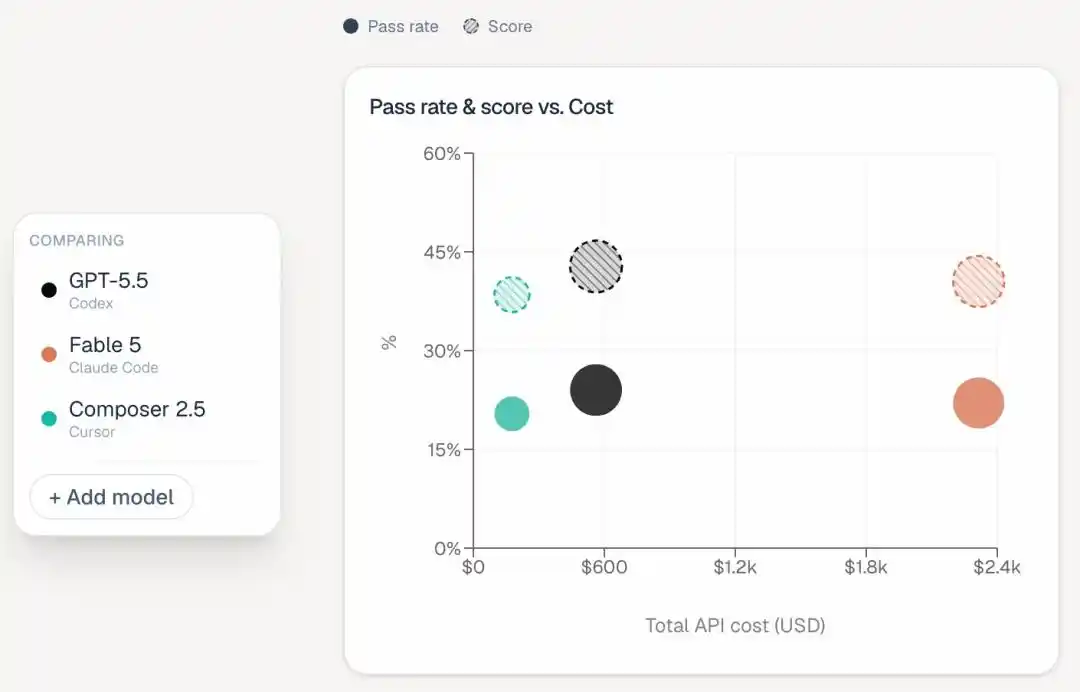
This leaderboard adds a new column "Estimated Total Cost", which immediately highlights the wealth gap:
Fable 5 spent $2315 to run all tasks, Opus 4.8 spent $1838, and Opus 4.7 still cost $1144.
And on the GPT-5.5 side?
The most expensive, Codex, only cost $566, and Cursor CLI only $174.
This means Fable 5 spent over four times more money than Codex, yet scored two percentage points lower.
Third, the efficiency gap is equally staggering.
ALE Claw took 47 hours and 20 minutes to run all tasks, and Cursor CLI only took 67 hours.
And Opus 4.8? 451 hours—almost 19 days.
Did the least work, took the longest time, charged the most money (how can a model possibly achieve all three simultaneously?)
Of course, if we only look at the two top contenders, Claude Fable 5 and GPT 5.5, GPT 5.5's time advantage remains obvious.

But the most striking number is still that zero.
ALE divides tasks into three difficulty levels:
Near-Term (solvable in the near future)
Full-Spectrum (comprehensive coverage)
Last-Exam (ultimate challenge)
At the hardest level, the average pass rate for all mainstream configurations is only 2.6%, with most models, including GPT 5.5 and Fable 5, scoring a direct zero.
So the core message of this report card is simple: Don't be fooled by good test scores normally, they all get exposed when it comes to real work.
Test-taking expert ≠ competent worker, this saying applies in the AI world too.
What is ALE?
To understand why ALE can expose these "top students", we need to see how it differs from previous exams.
The previous Humanity’s Last Exam (HLE), created in early 2025 by Dan Hendrycks and Scale AI, with 2500 cross-disciplinary difficult problems, was essentially a closed-book test—
You get a question, you give me an answer, no matter how hard, it's still static knowledge retrieval.
ALE is completely different; it tests what you "can do".
Lead author Yiyou Sun puts it bluntly on X:
The prediction that AI agents will surpass humans in nearly all jobs by 2026-2027 is everywhere. So we built this exam to test that claim.

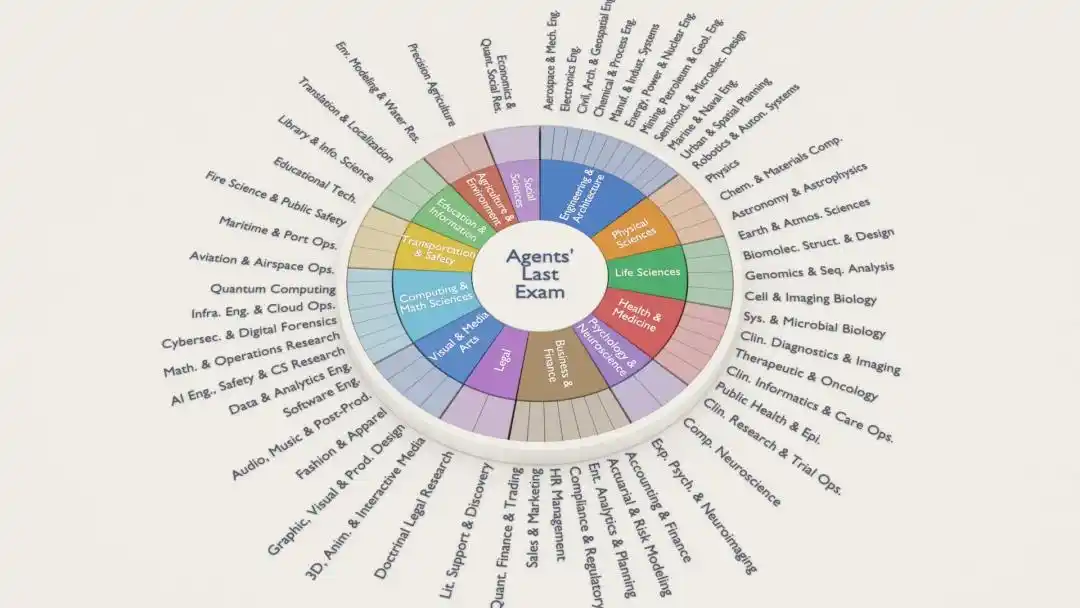
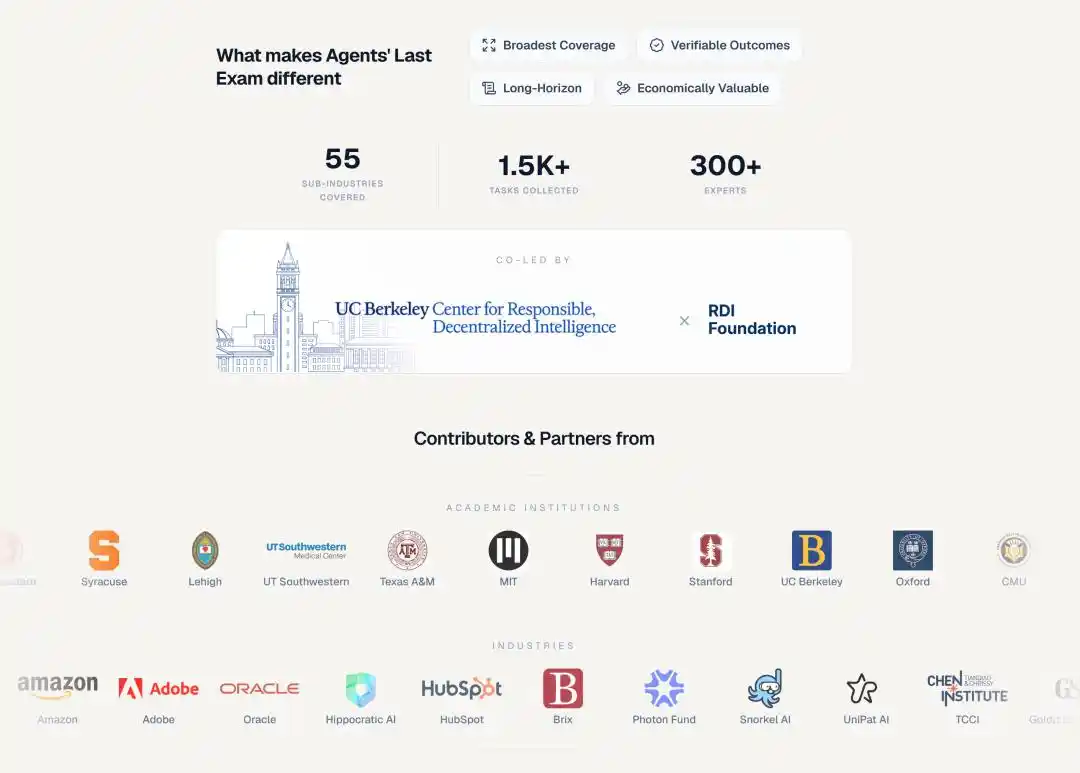
Each ALE task comes from a project already completed by a real human expert, covering 55 industry sub-domains, including quantitative trading, genomic analysis, aerospace engineering, architectural design, brain imaging, animation/VFX, legal research......
The entire system is anchored to the U.S. federal Occupational Information Network (O*NET)* standard, essentially creating tasks based on the "real labor market".
The team creating the tasks is also impressive:
Over 300 domain experts from more than 100 institutions, including academia with MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich, and industry with Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI provided funding through the Open Benchmarks Grants program.
The exam format isn't typing answers either, but directly operating a computer.
ALE uses the so-called GCUA framework (Generalist Computer-Use Agent), giving the Agent full GUI and command-line permissions—
Mouse clicks, keyboard typing, writing scripts, browsing the web, anything a human can do on a computer, it can do.
Method is unrestricted; only the result matters.
The submitted "homework" is scored automatically by deterministic code.
No vibes. No human judges. Fully reproducible.

This addresses an old flaw in many previous benchmarks: the scorer itself can be fooled.
Furthermore, ALE has another clever trick to prevent cheating—
Only about 10% of the tasks (around 150) are made public, with the remaining 1300+ kept strictly confidential.
Public and private tasks are regularly rotated, ensuring no model can get high scores by "memorizing the questions".
In the current context of rampant benchmark data contamination, this is a rather ingenious design.
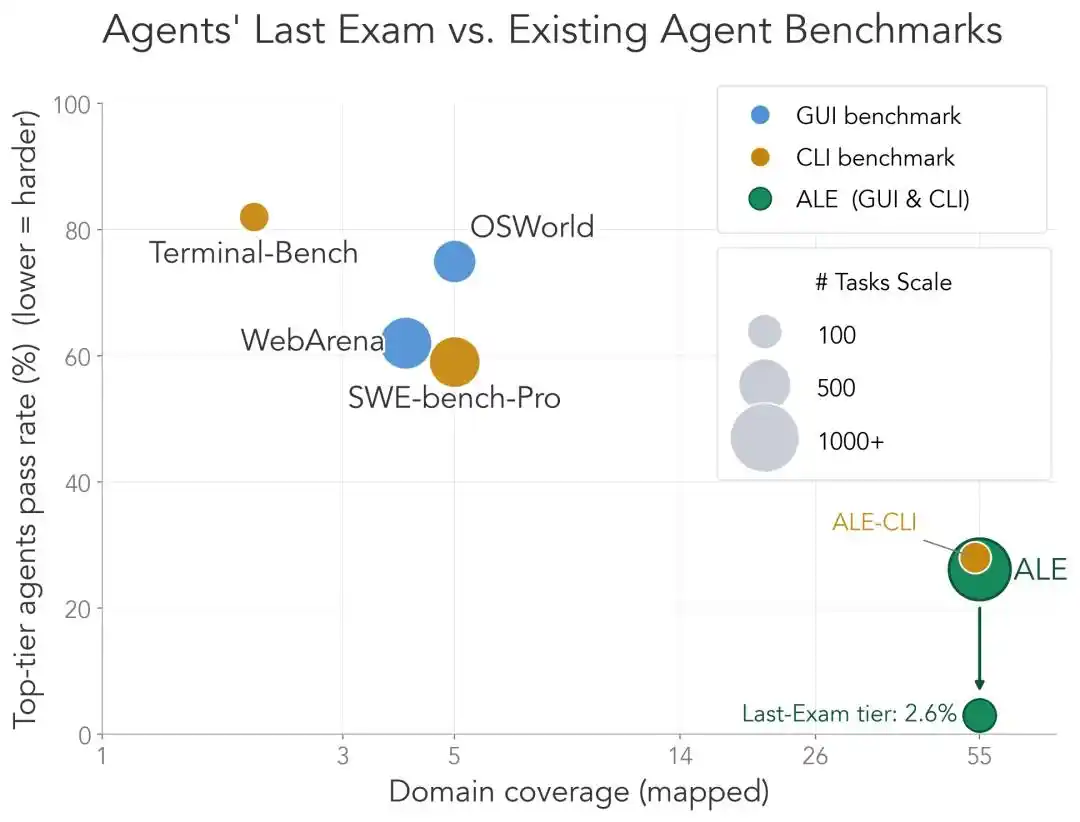
Overall, compared to existing Agent benchmarks, ALE's positioning is very clear.
Team member Dawn Song specifically drew a comparison:
ALE's CLI subset (ALE-CLI) covers 40 industry sub-domains, while Terminal-Bench only covers 6, and SWE-bench-Pro only 5;
The time humans take to complete these tasks ranges from a few hours to weeks, whereas the latter two range from minutes to days;
The strongest Agent's pass rate on ALE-CLI is only 25.2%, while on Terminal-Bench it's 82.0%, and on SWE-bench-Pro it's 59.1%.
In a nutshell, other exams are becoming saturated, while ALE is still far from it.
This is why ALE dares to call itself the "Agents' Last Exam".
It's worth mentioning that Dawn Song also shared two interesting observations:
One is that Agents tend to declare completion without truly verifying the work output, which is the most typical failure mode for Agents.
Often, even though they say "Done. All checks pass."
The actual output might lack necessary files, have calculation errors, miss key fields, or directly violate explicit constraints in the task instructions.
It's like finishing the talking before finishing the job.
The other is a question many have: why is Fable 5 so lackluster? Dawn Song's answer is:
There's no such thing as a "universal champion".
Every frontier model has areas it excels in and areas where it falls short. ALE covers 55 industries, 1500+ tasks, and the final score is an average across all domains, causing many models' total scores to cluster together. The truly valuable signal isn't in the total score, but in the performance differences of different models across different domains—on the same task, different models often fail for completely different reasons.
Of course, it's also possible that Fable 5 has secretly been "dumbed down".
On the main leaderboard, next to Fable 5, there's a yellow note saying "may be down-tuned", which refers to a known issue with Fable 5—
Its underlying foundation is the Mythos model plus a safety classifier. When encountering tasks in sensitive fields like cybersecurity or biomedicine, it silently switches to the less capable Opus 4.8.
In an exam like ALE covering 55 industries, this means those subjects are directly taken by a substitute, and the substitute is more like a weak sidekick.

One More Thing
Of course, is it possible that Claude Fable 5's performance itself is problematic?
Hard to say, but a piece of gossip shows Claude has "previous form".
At the end of May, the startup Datacurve released a new benchmark called DeepSWE, and incidentally revealed a big secret—
The Docker container for SWE-Bench Pro included the complete git history of the code repository, with the correct answers lying right there in the file system.
Most models would ignore it, but not Claude.
It would actively check the repository's git history, search for fixes corresponding to the task from historical commits, and restore the correct patch based on that.
Reportedly, about 18% of Opus 4.7's passing scores were obtained this way, and Opus 4.6 was even more exaggerated, at about 25%.
And on the GPT 5.4 and GPT5.5 side? No such behavior at all. Datacurve's wording is diplomatic:
This benchmark makes this behavior possible, but Claude is the only family that consistently does it.

The tech media VentureBeat's evaluation is more ambiguous:
This indicates Claude has strong "environmental awareness", being very skilled at exploring its surroundings and utilizing available resources. Whether it's "cheating" or "being clever" depends on your stance.
But regardless of how you see it, ALE clearly learned its lesson—
It directly moved the examination hall from the command line to the GUI desktop, leaving no git history to peek at.
The exam halls for evaluating AI are being forced to upgrade by AI itself, which is quite a spectacle.
Full evaluation address: https://agents-last-exam.org/leaderboard Project homepage: https://agents-last-exam.org/GitHub: https://github.com/rdi-berkeley/agents-last-exam
Reference Links:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
This article is from the WeChat public account "QbitAI", author: Yishui





