In recent days, a 3B small model has gained popularity on X because in some difficulty-verifiable reasoning tasks (like programming), it has entered the performance range of frontier models like Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, and Kimi K2.5, while its size is far smaller than these models.

This model is named VibeThinker-3B, a dense reasoning model with 3 billion parameters, aiming to explore how far verifiable reasoning capability can be pushed under strictly small model scale constraints.
After the model's release, many were amazed by its results and expressed a desire to try it out.


Notably, it is also a domestic model, coming from the Sina Weibo team.
The technical report shows that this model is designed specifically for tasks with reliable verification signals, including mathematical reasoning, competitive programming, STEM reasoning, and instruction execution with clear constraints.
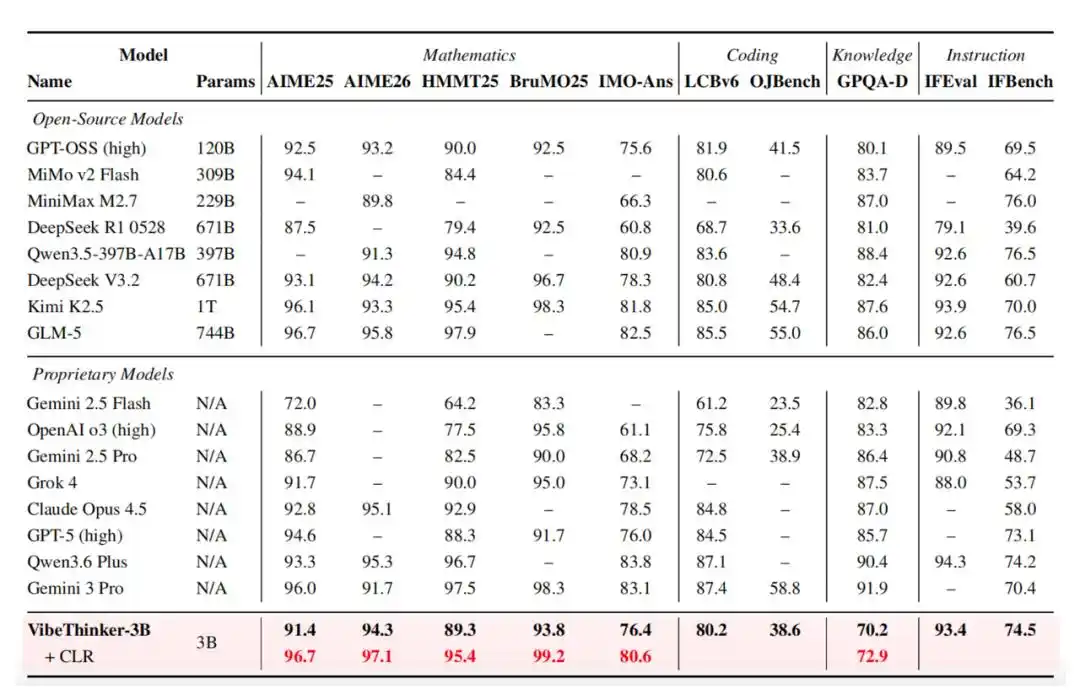
Therefore, it performs exceptionally well in various benchmark tests. It scored 94.3 on the AIME26 test, 89.3 on the HMMT25 test, 80.2 on the LiveCodeBench v6 test (Pass@1), and achieved a 96.1% pass rate in the latest unpublished weekly and biweekly LeetCode contests between April 25 and May 31, 2026.

How was this model trained? The technical report reveals some details.
First, it is built upon Qwen2.5-Coder-3B and undergoes post-training using an upgraded Spectrum-to-Signal process. This process strengthens data synthesis, quality filtering, and curriculum learning in Supervised Fine-Tuning (SFT), extends MGPO-style reinforcement learning to multiple verifiable domains, preserves complete long-context reasoning trajectories, and consolidates various capabilities through offline self-distillation and instruction reinforcement learning (Instruct RL).
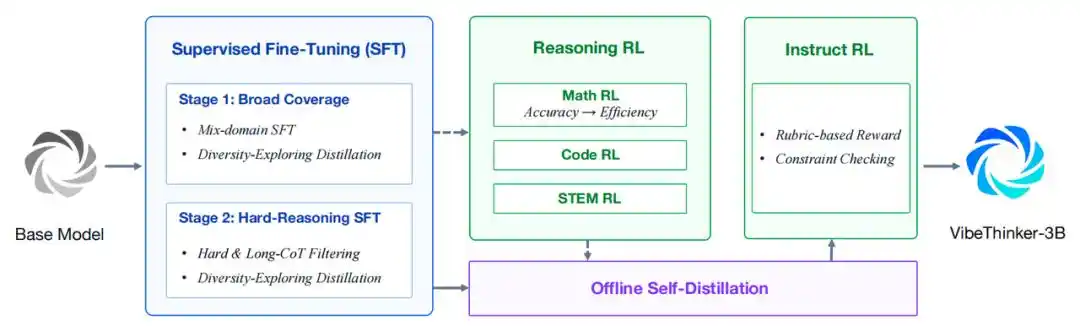
Overall training pipeline of VibeThinker-3B
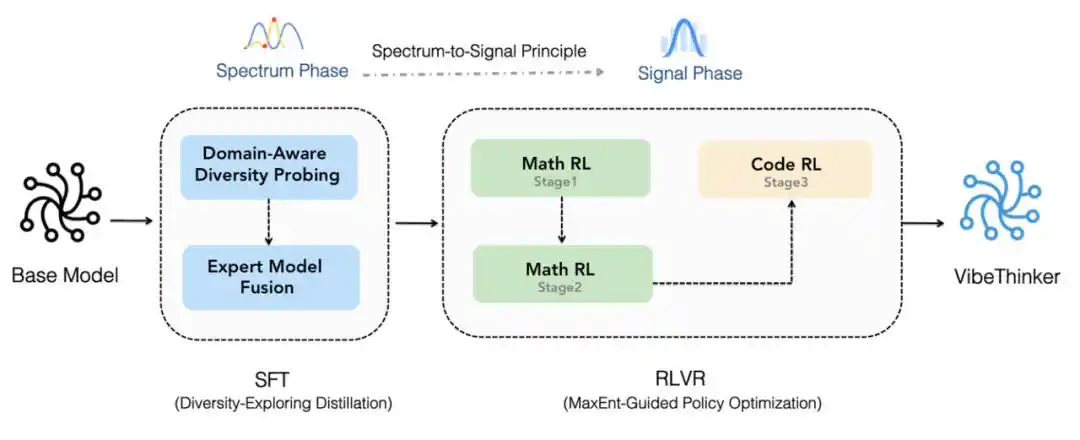
Spectrum-to-Signal pipeline.
Furthermore, VibeThinker-3B introduces Claim-Level Reliability (CLR) assessment, a test-time scaling strategy for answer-verifiable reasoning. CLR further improves performance on mathematical benchmarks, raising AIME26 from 94.3 to 97.1, HMMT25 from 89.3 to 95.4, and BruMO25 to 99.2.
The specific training pipeline is as follows:
- Curriculum-based two-stage SFT. The first stage focuses on broad capability coverage in mathematics, programming, STEM reasoning, general conversation, and instruction following. The second stage shifts to more difficult, broader-scope reasoning samples. Diversity-Exploring Distillation is used to preserve multiple valid solution paths.
- Multi-domain reasoning reinforcement learning. VibeThinker-3B reuses MGPO. Reinforcement learning is applied sequentially to mathematical, programming, and STEM reasoning tasks. Training uses a single 64K long-context window to preserve complete long-horizon reasoning trajectories.
- Offline self-distillation. High-quality trajectories are filtered and distilled from the mathematical, programming, and STEM RL checkpoints, ultimately forming a unified student model. Learning Potential Scoring is used to prioritize trajectories that are correct but not yet well imitated by the student.
- Instruct RL. The final stage improves the controllability for user-facing prompts. For format-sensitive and open-ended instructional data, rule-based verifiers and rubric-based reward models are employed.
In a recent post, well-known AI researcher and blogger Sebastian Raschka systematically summarized key points disclosed in the VibeThinker-3B technical report, including the following:

If you are interested in this content, you can delve into their technical report. Currently, the model is also publicly available for download.

Report Title: VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Report Link: https://arxiv.org/pdf/2606.16140
HuggingFace Link: https://huggingface.co/WeiboAI/VibeThinker-3B
However, the model's applicable scope has clear limitations, as it does not perform well in domains requiring general knowledge.
The developers also explicitly point this out and propose the "Parameter Compression Coverage Hypothesis": Different capabilities rely on model parameters in drastically different ways. Verifiable reasoning is closer to a highly compressible, parameter-dense ability whose core lies in multi-step reasoning, constraint satisfaction, self-correction, and answer verification. When the task space structure is clear enough and feedback signals are sufficiently reliable, compact models can also possess near-state-of-the-art reasoning capabilities. In contrast, open-domain knowledge, general conversation, and long-tail scenario understanding rely more on large-scale parameters to extensively cover facts, concepts, and world knowledge. This hypothesis is very insightful. VentureBeat wrote in its report: "It reveals a partial decoupling between reasoning capability and factual knowledge, and that the former can be compressed more efficiently than previously thought — an insight that has profound implications for how the industry thinks about model design, deployment costs, and the accessibility of advanced AI capabilities."

The authors state that their goal is not to create a small model to replace large-scale models, but to examine the true boundaries of small models along specific capability dimensions. With VibeThinker-3B, they hope to demonstrate that small models should not merely be seen as a compromise to reduce deployment costs. In capability domains with clear feedback and verification mechanisms, small language models are revealing a promising research path, potentially achieving frontier-level performance and forming a fundamentally complementary relationship with the traditional paradigm of parameter scaling.
Currently, the model still faces some skepticism within the community. If you are interested in this model, you might want to try it out for yourself.

Reference Links:
https://x.com/orcus108/status/2066876960073281582
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Zhang Qian





