In February 2026, Xiaohongshu issued an announcement requiring AI-generated synthetic content to be proactively labeled; unlabeled content would face distribution restrictions. More than three months later, an open-source project named guizang-social-card-skill appeared on GitHub, specializing in generating Xiaohongshu 3:4 graphics and public account covers. Its technical path had an unusual choice: it doesn't use any AI model to generate image pixels. The entire visual is rendered by HTML+CSS, with supporting images sourced from searches in real photo libraries like Unsplash. What it outputs is not an "AI-generated image" but a web page screenshot rasterized by a browser engine.
This choice corresponds to a specific change. Since 2026, Xiaohongshu has deployed audio-visual recognition models that analyze pixel distribution patterns and audio features to identify AIGC content. During the same period, over 800,000 AI-operated accounts and nearly 150,000 AI-fabricated notes were penalized. For content creators who need to produce graphics frequently, the probability of detection and labeling for images generated by tools like Midjourney or Canva AI is continuously increasing. Developer Cang Shifu's Skill chose another path: let AI handle layout decisions and leave the final pixels to rendering engines and real photo libraries.
This is a conscious technical bypass. However, how far this solution can go depends on the elasticity of the platform's definition of the term "AI-generated synthetic content."
28 Layout Skeletons: AI Handles Layout Logic, Not Drawing
Developer Cang Shifu, real name Gui Zang, previously released guizang-ppt-skill, another AI tool for graphic layout scenarios. This new social-card-skill has a more focused positioning: targeting Xiaohongshu 3:4 graphics, public account 1:1 and 21:9 covers, outputting resolutions of 1080×1440, 1080×1080, and 2100×900 respectively.
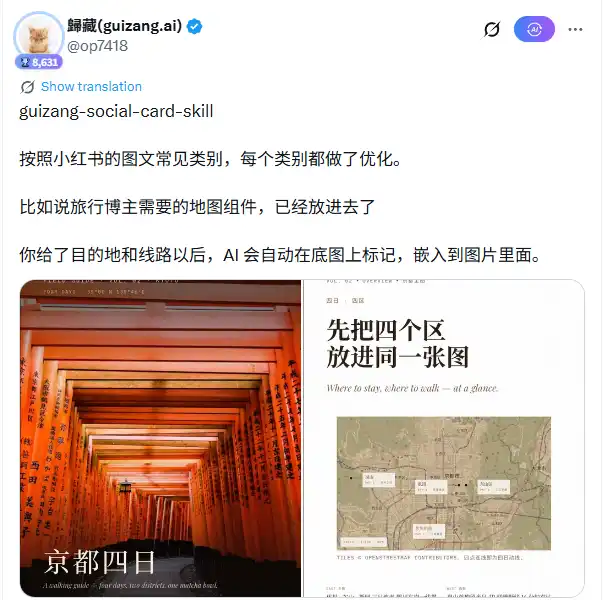
In terms of technical architecture, this Skill has 28 built-in layout skeletons, divided into two visual systems: Editorial (magazine style, 16 layouts) and Swiss (Swiss International Style, 12 layouts), accompanied by 10 preset theme color schemes. After users input a destination, itinerary, or note topic, the AI is responsible for selecting an appropriate layout skeleton, deciding text positioning, processing map annotation parameters, and then writing all design decisions into HTML+CSS. The Playwright rendering engine takes over the subsequent steps, capturing screenshots page by page to output PNGs.
A particularly useful component for travel bloggers is the map module. It uses MapLibre to load real tiles from OpenStreetMap, supporting multiple location markers and connecting lines. Users only need to provide city or attraction names; the AI automatically generates a basemap with annotations and embeds it into the layout. The accompanying image sourcing workflow has a clear priority: user-provided real photos take precedence; when no user images are available, it automatically retrieves supporting images in the order of Unsplash → Pexels → Flickr CC → Wallhaven.

The entire process is executed in seven steps: Intake (receive input) → Style & Theme (determine style and theme) → Layout Selection → Asset Prep (material preparation) → Compose & Render (layout and rendering) → Deliver & Review (output and review) → Iterate (iterative modifications). Each step is recorded in .poster files within the task directory. For batch image generation, run
node render.mjs, and Playwright renders them one by one. Another validation script, validate-social-deck.mjs, measures DOM elements in a real browser environment to detect layout issues like text overflow, font size exceeding limits, and footer element collisions.
The design goal of this mechanism is clear: to be as precise and controllable as printing layout software, rather than as free but unpredictable as diffusion models. The cost is that creative freedom is confined to these 28 grids. For creators who rely on personal photography styles, hand-drawn elements, or irregular collages, these layout skeletons provide not efficiency gains, but design constraints.
Regarding the entry barrier: the CLI version requires installing Playwright, Node environment, and obtaining API access for Claude Code or Codex. There's also a web version portal at xiaohongshu.guizang.ai for non-developer users, but there is no public comparison yet on whether its feature completeness matches the CLI version. The developer's several X platform posts and frequently updated README indicate this project is still in rapid iteration.
Pixels Not from Generative Models, But Compliance Doesn't Equal Long-term Safety
Xiaohongshu's AI content detection logic, according to public information and technical analysis, relies primarily on audio-visual recognition models. These models determine whether content originates from AI generative models by analyzing pixel distribution patterns. Diffusion models and GANs leave specific statistical signatures at the pixel level when generating images, which differ from the natural lighting, lens distortion, and noise patterns captured by camera sensors. The training objective of audio-visual recognition models is precisely to capture this inconsistency in statistical patterns.
The evasion logic of Cang Shifu's Skill is based on a key distinction: its output image pixels do not come from any generative model. The HTML rendering engine rasterizes CSS styles, producing pixel distribution characteristics closer to browser interface screenshots or desktop publishing software outputs. The photographic portions come from real human-shot materials in libraries like Unsplash; these images, captured by cameras and manually post-processed, do not carry diffusion model signatures.

However, the validity of this distinction depends on the platform's definition of "AI-generated synthetic content" being precisely drawn at the line of "AI model generating pixels." Xiaohongshu's official announcement uses the term "AI-generated synthetic content," a phrase whose original scope is not narrow. Once the platform expands the definition to include "AI-assisted design programmatically rendered output" or incorporates the browser rendering characteristics of HTML-rasterized images into the training data for its recognition models, the current technical advantage of this solution would disappear.
The platform has both the technical foundation and governance motivation to expand the definition. The audio-visual recognition models themselves are continuously iterating. If training data includes a large number of comparative samples between HTML-rendered images and AI-generated images, models could learn to distinguish "subpixel anti-aliasing features of browser font rendering" from "irregular pixel blocks in GAN-generated text." There's no public information indicating Xiaohongshu has initiated training in this direction yet, but from the perspective of model capability boundaries, such expansion is technically feasible.
More noteworthy are compliance factors related to mini-program/API hosting. Currently, there is no official documentation indicating that this Skill has integrated a model filing number or completed related compliance registration. If the platform adds traceability requirements for the image generation toolchain to its content review process, the lack of filing information could become a new blocking point.
API Template Engines, Platform-specific Tools, and HTML Rendering Are Forging Three Diverging Paths
Observing tools in the market that generate images for social media, one finds they are diverging into three distinct technical routes, each facing a different structure of review risks.
Direct Image Generation by AI Models. The representative of this path is the Magic Design feature released by Canva AI in April 2026, which generates design drafts containing AI visual elements directly from text prompts. Images generated by models like Midjourney, DALL·E also fall into this category. The problem is clear: these images are the primary detection target for audio-visual recognition models. Canva's response is to encourage transparent labeling, not evasion of detection. On Xiaohongshu, there is no public data to confirm whether posts with AI-generated images receive lower recommendation weights after being labeled, but the platform's policy of "restricting distribution of unlabeled AI content" is already established. Each update to diffusion models may change pixel statistical signatures, and the corresponding detection models iterate simultaneously, meaning creators face a continuously moving target.
API Template Engine Rendering. Bannerbear is typical of this route. Users create templates in a designer, modify layer variables by passing JSON data via REST API, and the server renders and outputs PNGs or JPGs. Its core is also "programmatic rendering," not "model-generated pixels," and outputs lack diffusion model signatures. The difference from Cang Shifu's Skill is: Bannerbear's templates rely on manual design; AI doesn't participate in layout decisions. Cang Shifu's Skill lets Claude directly read/write HTML, giving layout selection power to AI. Bannerbear's solution has risks in another dimension: when many accounts use identical templates, colors, and fonts to produce graphics, even if each image isn't AI-generated, it can trigger pattern recognition of "programmatic batch production" on the platform side. The triggers for anti-spam rules aren't identical to AI detection, but for creators operating batch accounts, the result is also restricted distribution.
Platform-specific Custom Generation. Tools like Pin Generator are designed exclusively for Pinterest, automatically generating Pin images that align with the platform's algorithm preferences. The core of this route isn't evasion, but full adaptation—dimensions, visual style, publishing rhythm all conform to platform specifications. The advantage is the lowest review risk; the downside is obvious: tool capabilities are tied to platform rules. When Pinterest adjusts its algorithm or restricts third-party API calls, the tool directly fails. Compared to Cang Shifu's Skill, the former is a platform-exclusive tool, while the latter is a cross-platform general solution. Platform-exclusive is safer but more fragile; cross-platform is more flexible but more complex—a recurring trade-off in the AI tool space.
The three routes have different risk structures. AI generation offers the most freedom but must constantly respond to new detection models with each update. Template engines are most stable but risk being caught by anti-spam rules. HTML rendering walks between the two: layouts are flexibly controlled by AI, pixels are left to the browser and real photos, evading detection at the "AI-generated pixels" layer but unable to counter rule expansions at the platform's semantic level.
The Ceiling of the Layout System Lies Not in Code, But in Content Type
The 28 layout skeletons cover two mainstream visual systems: magazine and Swiss styles. For travel bloggers needing to display map routes, timelines, and multi-day itineraries, this system is a high match. Map annotations and itinerary connections are core information for such notes; the layout skeletons structure this information while maintaining a professional layout aesthetic.
However, Xiaohongshu's content ecosystem is far richer than travel guides. Outfit notes rely on personal photography style and color tone; makeup reviews need high-definition macro photos and product comparisons; lifestyle content heavily uses multi-photo collages and handwritten annotations. The "layout" for these content types isn't about structured information presentation but an expression of personal aesthetics and mood. The 28 layout skeletons are not tools but constraints in such scenarios.

Technical limitations are also real. It currently supports three sizes: 1080×1440 (Xiaohongshu 3:4), 2100×900 (Public Account 21:9), and 1080×1080 (Public Account 1:1). Formats like Douyin's 9:16 vertical cover or Bilibili's 16:9 horizontal cover are not supported. The image libraries rely on Unsplash and Pexels; their material leans towards high-quality photography, suitable for travel, scenery, and urban architecture. However, coverage for high-frequency materials in verticals like food close-ups, cosmetic product flat lays, or fashion items is limited in these libraries. The user-image-first strategy can partially mitigate this, provided creators have sufficient real photo material themselves.
The validation mechanism is a double-edged sword. validate-social-deck.mjs can intercept layout accidents before output, ensuring zero errors in 100 batch renders. This is an efficiency guarantee in operational scenarios requiring dozens of daily graphics. But it also means any design not conforming to preset layout rules will be rejected by the script. Creators wanting to add a slanted text decoration or custom margin within a standard layout cannot simply drag and adjust as in Canva; they need to edit the HTML and CSS source code directly.
The local deployment barrier is another stratification point. Creators capable of running Playwright and Node scripts can dive into layout skeletons and rendering scripts for customization. But for most Xiaohongshu bloggers, what's accessible is likely a functional subset via a web interface. The actual value derived from this Skill differs greatly between these two user groups. The core user base of open-source projects is creators and developers willing to tinker and with technical backgrounds, not the "one-click output" demands of average content producers.
No Universal Answer, But the Divergence of Technical Paths Itself Tells a Story
A Xiaohongshu travel blogger faces three choices: use Midjourney to generate illustration-style itinerary graphics, bearing the risk of labeling and demotion; use Bannerbear to set up templates and batch-fill data daily, bearing the anti-spam risks from template homogeneity; or use Cang Shifu's Skill, letting AI choose the layout and outputting via HTML rendering, bearing the risk of the platform expanding its "synthetic content" definition. There's no safe card, only combinations of different risk structures.
This landscape itself conveys a message: the adversarial iteration between platforms and AI tools has begun. Every time a platform updates its detection model, the technical advantage period for a batch of tools ends. Every time a new tool finds a bypass route, the platform adjusts its strategy. This is not a process that will converge to a stable state. The validity period of the HTML rendering solution depends on whether Xiaohongshu's audio-visual recognition model training continues to focus on "diffusion model pixel features" or expands to "all non-native photographic pixels."
For content creators, distinguishing between "AI-assisted" and "AI-replacement" gains practical significance. The platform's stance is clear: encourage AI as a creative amplifier, oppose using AI to replace humans for low-quality batch production. In Cang Shifu's Skill, AI handles layout decisions, not content generation; photos are real, layouts are preset skeletons by human designers. This precisely falls into the "AI-assisted" zone. Content where everything from copy to images is generated by models is what the platform explicitly aims to crack down on.
Whether this distinction will become an operational standard for platform review is uncertain. But tool developers are already responding to this definition with their technical choices.






