Recently, some media outlets reported that Microsoft revoked its internal Claude Code licenses 1. Claude Code is an AI coding tool launched by Anthropic. It became one of the most popular auxiliary development software within Microsoft just 6 months after being made available internally. This was followed by a sharp increase in token consumption, skyrocketing costs, but the output quality was unsatisfactory. After multiple considerations, Microsoft hit the brakes, directing employees to its own Copilot CLI.
The phenomenon where token consumption is disproportionate to actual output is also common in other platform companies. Uber exhausted its 2026 annual AI programming tool budget in just 4 months; some Amazon employees consumed tokens meaninglessly; Meta quietly removed the Tokenmaxxing leaderboard for internal employees, no longer encouraging token consumption with no tangible output 2. Everyone is embracing AI, but hasn't found the right approach; companies are emphasizing being AI-native, but (for now) don't see the returns, only the ever-growing bills. I call this "Token Uneconomical".
Token uneconomical results from the interplay of multiple factors including weak internal corporate controls, limited returns on token usage, and the architectural design of Agents themselves (such as Skill repetition, internal wastage in long-range tasks, multi-agent collaboration costs). In the future, these issues may gradually ease with the refinement of internal controls and continuous optimization of technical-side consumption. However, to turn the net token benefit positive, we need to address not only the supply side by optimizing token costs, but also the demand side, solving the difficult problem of how to make token consumption generate tangible value in a wide range of industrial scenarios.
Good Things Aren't Cheap
Over the past two years, mainstream large models have rapidly iterated. Development companies have adopted different product portfolio strategies based on their market positioning, leading to changes in API call prices ($ per million tokens). Model performance has improved significantly, but good things aren't cheap; the call prices for products within the same tier have also been quietly rising, becoming an important factor pushing up the token consumption costs for downstream users.
The Leader's Tiered Strategy
Anthropic is the earliest among closed-source model vendors to recognize that coding is the core scenario for token monetization. The main paying users of large models are developers and enterprise technical teams. They are less sensitive to price and value the model's coding efficiency and quality more. Gaining an early advantage in the coding business scenario enables token premium pricing.
Therefore, Anthropic focused its R&D on coding. After establishing an advantage in coding capabilities, starting with the launch of the Claude 3 series in early 2024, it took the lead in the industry in adopting a three-tiered product portfolio (flagship-mid-range-lightweight) for models of the same generation, achieving tiered pricing while capturing both the high-end and mass markets. The Opus series is positioned as the industry benchmark for coding, anchoring the high-end market with pricing of $15/$75 (input/output per million tokens, same below); the Sonnet series ($3/$15) provides a cost-effective choice for daily coding and office tasks; the Haiku series ($1/$5) targets lightweight, fast interaction scenarios with a user-friendly price. This fine-grained tiering allows Anthropic to maximize profit extraction at each price point while protecting market share.
This pricing strategy gives Anthropic, as a technical leader, more competitive levers and greater flexibility. For example, after noticing that the performance gap with competitors was rapidly shrinking, they significantly lowered prices with the Opus 4.5 release to squeeze competitors' market space. Another example: with the release of the new-generation model Mythos Preview ($25/$125), they inserted a new ultra-high-end tier above Opus, raising the flagship product price and reversing the previous trend of declining prices for high-end products. Subsequently released Fable 5 uses the same underlying architecture, imposes restrictions on some features citing safety reasons, and adopts a price of $10/$50 (still double that of the Opus series) for the broader market. This creates a three-dimensional pricing strategy based not just on performance, but also on the tightness of safety constraints, forming ability tiers, risk tiers, and pricing tiers, thereby regaining the premium market.
The effectiveness of this positioning strategy was fully validated between 2025 and 2026. Anthropic's Annual Recurring Revenue (ARR) soared from about $10 billion at the end of 2024 to about $450 billion by May 2026 3. More importantly, this strategy effectively protected the market premium as the product leader, allowing them to escape the trap of competing solely on price through performance advantages, completing the value loop where good things aren't cheap.
The Catch-up Players' Price Tug-of-War
In contrast, OpenAI and Google chose different, more diversified paths from Anthropic in the early stages of large model commercialization. OpenAI in 2024 invested heavily in multimodal projects like Sora; Google built an ecosystem strategy around Gemini covering multiple product lines like Search, Cloud services, and Workspace. These investments expanded the technological landscape but, due to dispersed resources, did not perform as prominently in office and coding scenarios. By the time they realized coding was the main battlefield for monetizing model capabilities and turned back to catch up, they had lost their first-mover advantage.
OpenAI's pivot back has been resolute. On one hand, refocusing on coding and Agent capabilities, cutting down massive projects like Sora; on the other hand, following Anthropic to establish its own tiered product matrix, closely shadowing one-on-one, while deliberately widening the price gap between flagship and lightweight models—high flagship prices to maintain the banner of leading models, and low lightweight prices to capture market share. GPT 5.5's pricing ($5/$30) aligned with Opus 4.7/4.8 ($5/$25), establishing a high-end price anchor equivalent to Claude Opus. The secondary models GPT 5.4 mini ($0.75/$4.50) and nano ($0.20/$1.25) were significantly lower than their Claude Haiku 4.5 counterpart ($1.00/$5.00), trading price for market share.
Google is the core of the Android ecosystem, with a complete commercial closed loop. It needs to handle more complex relationships and acts more cautiously. Gemini needs to serve Google Cloud enterprise clients, Workspace productivity users, and search product consumer experiences simultaneously. Even after realizing the importance of coding, it cannot decisively focus all resources on coding and office tasks; it still needs to follow a multimodal, diversified route.
Google also closely followed Anthropic, starting from Gemini 1.5, dividing its products into the flagship Pro series and the lightweight Flash series. However, its product iteration speed is relatively slower, with lower price positioning. The flagship model Gemini 1.5 Pro in early 2024, in short-prompt (<128k) scenarios, had an output price of just $5 per million tokens, one-third that of GPT-4o and one-fifteenth of Opus 3 at the time; Gemini 3.1 Pro released in February 2026 raised the output price to $12 per million tokens, significantly lower than GPT 5.4's $15 and Opus 4.6/4.7's $25 at the time. Moreover, Google made a reverse move, adding an ultra-lightweight Flash-Lite product line under the lightweight Flash line, pushing call prices down to the same level as open-source models. This is a typical strategy of trading price for volume.
The eagerly anticipated Gemini 3.5 Pro has been delayed in its official release, reflecting the internal struggles Google faces in balancing performance, safety, and ecosystem adaptation. The pricing strategy for the new flagship model is also highly watched by the market.
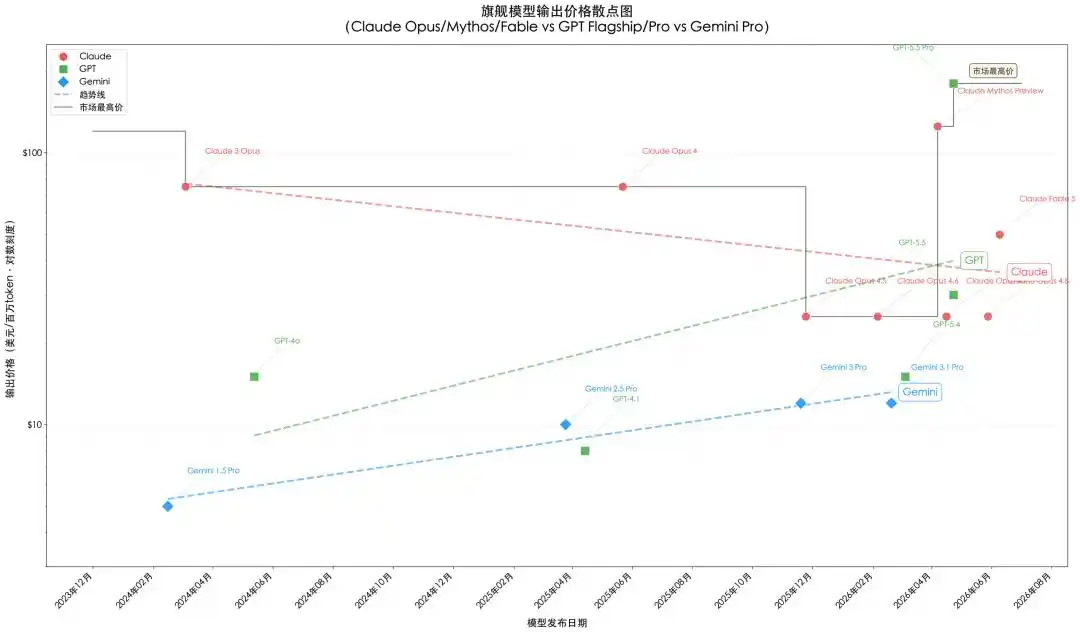
Figure 1: Flagship Model Pricing Trend. Claude series and GPT-4o/4.1/5.4 pricing from official pricing pages; GPT-5.5 series, Gemini 3.5 Flash pricing from OpenAI/Google platforms and third-party summaries; GLM series pricing based on overseas Z.ai platform, specific prices subject to exchange rate fluctuations and dual-track pricing. Drawing: Codebuddy
Secondary/Lightweight and Open/Semi-open Source Model Markets Silently Rising in Price Amid Demand Explosion
Flagship models compete on performance, secondary/lightweight models fight on price—this is the logically correct posture for market competition. Facing fierce market competition, the general expectation is a continuous decline in the market price center. However, the reality is exactly the opposite. The economical token market, composed of secondary/lightweight and open/semi-open source models, has seen its price center quietly rise over the past two years. The true elevation of the market's token price floor is precisely accomplished in this upward shift.
On the surface, this is a fiercely competitive red ocean. Affordable secondary/lightweight models like Sonnet, mini, Flash are the mainstream closed-source models' economical versions for the mass market, primarily aimed at capturing market share. Simultaneously, open-source or semi-open source models like DeepSeek, Qwen, and GLM have rapidly emerged, generally adopting a strategy of flagship positioning with secondary/lightweight pricing, bringing continuous price pressure to the secondary/lightweight closed-source model market. At the end of 2024, DeepSeek V3 entered the market with pricing around $0.27/$1.10, far lower than comparable closed-source models. The slightly later released R1 offered reasoning-enhanced capabilities at $0.55/$2.19, directly compressing the pricing space for GPT-4.1 mini and Claude Haiku. GLM-4 Plus offered near-GPT-4 level capability for just $0.69/$0.35, posing a huge attraction for price-sensitive developers. Competing on price seems the norm in this tiered market.
However, on the other hand, the release of each generation of secondary/lightweight and open/semi-open source models has been accompanied by an elevation of the price floor. For example, Haiku 3.5 released in October 2024 had input/output pricing of $0.80/$4.00; a year later, Haiku 4.5's pricing increased by 20% to $1.00/$5.00. Around the same time, the GPT mini series pricing almost doubled, from 4o mini's $0.15/$0.60 to 4.1 mini's $0.40/$1.60. The Gemini Flash series also followed, from 2.0 Flash's ultra-low $0.10/$0.40 to 2.5 Flash's $0.30/$2.50, with output per million tokens increasing over sixfold. Open/semi-open source models like the GLM series: GLM-5's pricing in overseas markets increased by about 67% to 100% compared to GLM-4.7. As Zhipu (智谱) itself stated, this significant price hike shows that the technical capabilities and market competitiveness of domestic models are rapidly improving.
The fundamental cause of this phenomenon is the explosive growth in the consumption of economical tokens. Most daily coding tasks, document processing, and automation workflows do not require Opus or GPT-5.5 level capabilities; they are handled by models like Sonnet, mini, Flash, or completed by open/semi-open source models. With the proliferation of AI coding assistants, Agent workflows, and enterprise-level AI applications, the call volume for these secondary/lightweight and open/semi-open source models has surged, far exceeding that of flagship models. On one hand, this leads to rapid increases in the consumption of economical models, making the game of burning cash to maintain low prices unsustainable. On the other hand, it opens up room for vendors to raise prices, with demand still growing rapidly even after price hikes. Therefore, even in the economical token market, the competitive logic is shifting from which token is cheaper to which token offers better value for money. Whether it's Claude Sonnet/Haiku, GPT mini/nano, Gemini Flash, or DeepSeek, Qwen, GLM series, the pricing center is trending upward.
From the above analysis, we can see that the token market is undergoing an overall elevation process: high-end pricing structure solidifying, mid-tier seeing both volume and price rise, and economical models following and rising. Anthropic established the industry's strongest pricing power based on its coding leadership. OpenAI and Google are accelerating their catch-up but still need to trade price for volume in the short term. Open/semi-open source models, while continuously raising the pricing floor, are also starting to share the dividends of market growth. The evolution of this landscape will profoundly affect the profit distribution and competitive dynamics of the entire AI industry. In a token market with soaring consumption and rising unit prices, the corresponding explosion in model vendors' revenue necessarily means rising costs for downstream token users, the underlying cause of the terminal consumption's token uneconomical state.
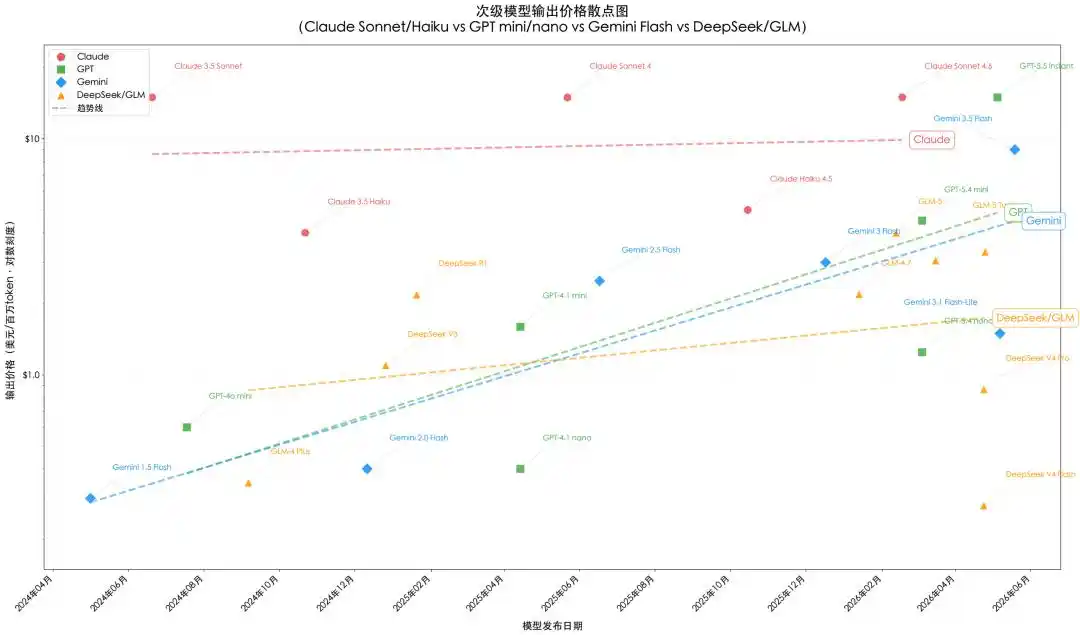
Figure 2: Secondary/Lightweight and Open/Semi-open Source Model Pricing Trend. Claude series and GPT-4o/4.1/5.4 pricing from official pricing pages; GPT-5.5 series, Gemini 3.5 Flash pricing from OpenAI/Google platforms and third-party summaries; GLM series pricing based on overseas Z.ai platform, specific prices subject to exchange rate fluctuations and dual-track pricing. Drawing: Codebuddy
The Invisible Consumption of Agents
Tokens getting more expensive certainly hurts the wallet, but what's even more distressing is that many tokens are systematically wasted when calling Agents to work. The Context Trap, Tokenizer Black Box, Skill Redundancy, and the Communication Tax and Entropy Drift in multi-Agent collaboration—these structural leakages and wastages stack together, constituting the internal technical root causes of token uneconomical.
Context Trap
Model inference requires calculating the relationship between each token and all other tokens. Therefore, the longer the context, the heavier the computational burden and the more token consumption. The same question, thrown to an Agent without preamble or history, consumes very few tokens. But if it includes dialogue history, tool logs, code files, error messages, and multi-round discussions, input token consumption might increase by several orders of magnitude.
And Agent architecture inherently amplifies the long-text trap. Agents break down problems, plan tool calls, read files, check feedback, revise plans, call tools again, cycle repeatedly. Each step might bring historical records back into the context. The same batch of information is read repeatedly, the same task is billed repeatedly. Salim et al., (2026)'s analysis of the ChatDev framework found that the Code Review stage consumed on average 39.5% of total tokens 4, the highest among all development stages. This means nearly 40% of token spending went into Agents repeatedly passing existing information amongst themselves, rather than genuinely generating new content.
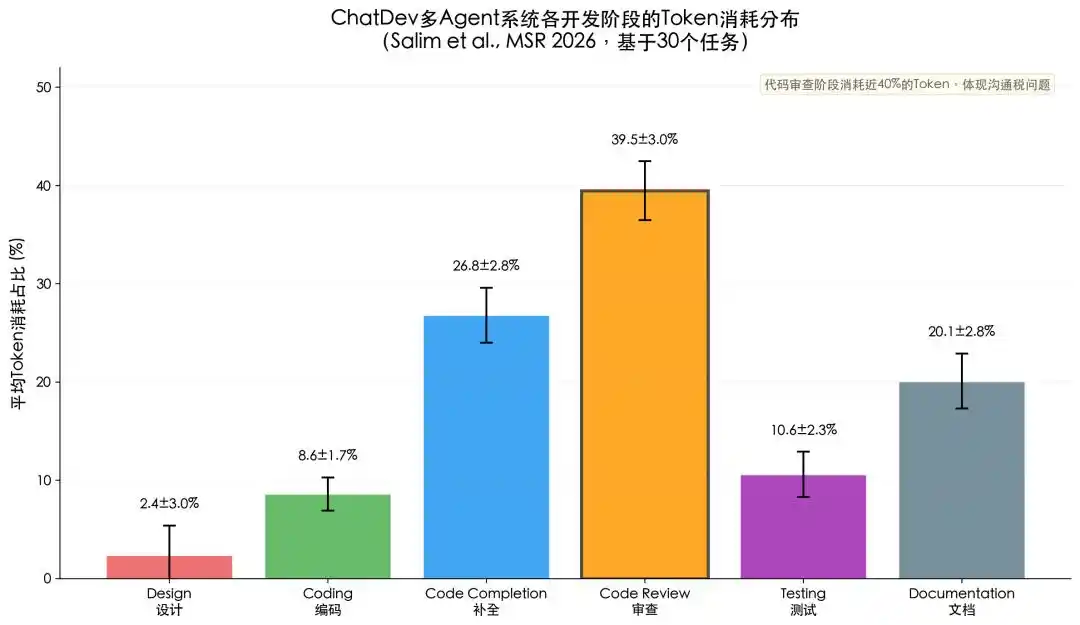
Figure 3: Analysis of Token Consumption Share by Stage for 30 Tasks in the ChatDev Framework. Salim, et al., (2026). Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering. Proceedings of the Mining Software Repositories Conference (MSR).
Tokenizer Black Box
The Tokenizer is the foundation of large model training, determining the upper limit of information density for a given parameter count, the lower limit of effective context length, and the reliability on edge cases (numbers/code/multilingual). More rational tokenization makes model training and inference more efficient and stable. The tokenizers and weights of open/semi-open source models are usually public, while those of closed-source models are a "black box." Updates to tokenizers are often accompanied by changes in token density.
In April 2026, with the release of Opus 4.7, Anthropic replaced the underlying tokenizer. According to disclosures in Anthropic's official documentation, the tokenizer adjustment primarily considered the practical needs of model training, adopting a finer-grained subword segmentation scheme to enhance performance. A side effect was that text of the same length expanded by 1.0x to 1.35x in token count 13. Results from multiple independent testing organizations showed the actual expansion factor was higher. Finout, an enterprise AI cost management platform, conducted weighted tests on real enterprise prompts, showing an average expansion rate of 1.47x (+47%) for technical documents and English-dense code files 14. ClaudeCodeCamp's comprehensive test on seven real file types resulted in an average of 1.325x (+32.5%) 15. Developer Simon Willison compared via API directly, finding the same system prompt expanded from 5,039 tokens to 7,335 tokens (+46%) under the new tokenizer, while token expansion for high-resolution images was as high as 3.01x (+201%) 16.
Earlier, OpenAI upgraded its tokenizer from cl100k_base to o200k_base with the release of GPT-4o, nearly doubling the vocabulary size. The official explanation stated this aimed to improve compression and enhance multilingual processing capabilities 17. However, vocabulary expansion itself does not mean a reduction in token count for the same text. In fact, for non-English content (especially CJK characters like Chinese, Japanese), the change in segmentation granularity of the new tokenizer might lead to an increase, not a decrease, in token count.
Regarding whether finer-grained tokenization improves model performance, there is currently a lack of systematic public justification from model vendors. Anthropic categorized the new tokenizer under Breaking Changes in the Opus 4.7 documentation, merely describing the factual change (finer-grained subword segmentation) without detailing the technical rationale or performance benefits. Some researchers in the community pointed out that finer tokenization could theoretically enrich the model's vocabulary representation, especially benefiting code understanding and structured data processing (JSON, XML formats hit the highest 1.35x expansion ceiling in Opus 4.7). However, whether this potential performance gain sufficiently justifies the nearly 50% cost increase remains an open question 13.
Tokenizer iteration frequency is significantly lower than model updates, but it concerns the most fundamental billing standard for tokens, and changes are hidden in technical details, making it almost impossible for ordinary users to detect. Closed-source models are particularly secretive about tokenizers, potentially becoming one of the factors exacerbating token uneconomical.
Meaningless Skill Calls
Skills are key tools that make Agent architectures more specialized. Some view skills as slightly longer markdown, others as folders containing various reference materials and instructions, and still others as extremely long structured prompts. In actual reasoning and Agent tasks, many skills are too long and too complex, increasing token consumption.
A large-scale empirical study by Gao et al., (2026) on 55,315 public skills revealed how ineffective skill loading wastes tokens 5. At the routing level (where the Agent decides whether to call a skill), a high 26.4% of skills had no routing description at all, like tool manuals without a table of contents, greatly increasing the probability of being loaded ineffectively by Agents. At the body content level, over 60% of skill content was not directly executable operational rules but background explanations or example text. Most tokens spent on using a skill went into reading the manual, not doing the work. More seriously, some skills densely reference files; a single call could inject tens of thousands or even over a hundred thousand tokens, with only a small fraction potentially relevant to the current task.
The SWE-Skills-Bench benchmark test by Han et al., (2026) further confirmed the limited utility of skills 6. This study tested 49 public software engineering skills on real GitHub projects. The results showed that 39 skills (79.6%) brought no improvement in pass rate (same Pass rate with or without the skill). The average utility increase across all 49 skills was a pitiful 1.2 percentage points, yet token overhead increased by up to 451%. Only 7 skills encoding specific domain expertise (e.g., financial risk control formulas, cloud-native traffic management, GitLab CI patterns) brought meaningful performance improvements (up to 30 percentage points); 3 skills even caused performance degradation due to version conflicts (up to 10 percentage points). This indicates that skill utility is highly dependent on scenario matching. Blindly calling skills only adds unnecessary cost.
Multi-Agent Gibberish and Long-Task Drift
Multi-Agent is currently a favored working method, allowing a user to lead a team of AIs—one for coding, one for review, one for testing, one for fixing. Multiple Agents each perform their duties, supervising each other, which indeed improves output quality in many cases. But machines also hold ineffective meetings. Conversations repeatedly cover already discussed task background, previous conclusions, and formatting boilerplate. Each repetition consumes tokens again. Salim et al., (2026) termed this the communication tax of multi-Agent systems 4.
Furthermore, delegating complex long tasks to multi-Agent systems is becoming a mainstream practice in programming and office work, gradually extending to daily life scenarios like dining, transportation, etc. Long tasks inherently have a tendency to drift off course. The context of such tasks is stuffed with tool outputs, errors, drafts, logs, easily causing model reasoning to gradually deviate from the goal. To correct this drift, developers often add summarization, memory, checking, rollback mechanisms, leading to more token consumption. In their study on TabTracer, Luo et al., (2026) observed that traditional chain-of-thought reasoning tends to fall into loops when paths become too long, and adversarial injection could deliberately trigger such loops, causing Agents to repeatedly consume tokens on wrong paths without realizing it 7. This extra consumption required to maintain stability is often called the entropy tax. The more complex the system, the freer the Agents, the more supervision is needed. The longer the task, the larger the context, the faster the entropy tax grows. In a seemingly efficient Agent team, over half of the token bill might be spent on internal coordination and self-correction.
The Context Trap, Tokenizer Black Box, meaningless skill calls, gibberish literature, and long-task drift—the combined effect on token consumption is not a simple addition but a multiplicative exponential growth. More notably, the impact of these technical wastages is asymmetric across users. Developers with technical backgrounds can mitigate these issues to some extent by adjusting system prompts, trimming skill content, setting context window management strategies, etc. However, for ordinary enterprise users lacking technical background, they neither understand the internal token flow mechanisms of Agents nor can they effectively intervene in their behavior. They only see numbers on the bill constantly growing, not knowing where the money is spent or why so much was spent. In this sense, token uneconomical is not just a technical efficiency issue but also an issue of technological equity. The usage threshold for AI tools has shifted from knowing how to code to understanding the cost dynamics of Agent architectures. In reality, most users of intelligent agents lack the relevant technical background, placing them at a structural disadvantage.
Finding Real Demand
Compared to various supply-side issues like pricing and ineffective consumption, the limitations on the application side are more important reasons for token uneconomical. Despite remarkable progress in model performance over the past two years, the general applicability of tokens remains quite limited. Most current token usage is confined to highly digitized scenarios, like coding assistance, document processing, data analysis. Stepping outside these strong areas, large model performance rapidly declines as the digitization level of the application scenario decreases. Reaching service industries with extremely low digitization levels, such as catering, housekeeping, retail terminals, and on-site repairs, the tasks tokens can independently complete are limited to already highly digitized process management parts, making it difficult to practically participate in on-site operations.
This is not to say AI can never enter these fields, but that there exists a structural chasm between the current pure language model paradigm (token-in, token-out) and the real world. This problem existed during the mobile internet era and is a fundamental reason why digital technology failed to fundamentally transform primary and secondary industries. The development of artificial intelligence provides new possibilities for bridging this chasm. Foundational research in AI for Science, World Models, and robotic systems is making progress. In the past two years, Nobel Prizes in Physics and Chemistry were awarded to AI scientists; significant progress was made in humanoid robots by Figure, Tesla Optimus, and Unitree. However, these frontier areas are still in the laboratory stage. Before groundbreaking application-level breakthroughs are achieved, tokens will likely remain trapped in highly digitized scenarios.
Coding is a Special Case of Generality
Coding is currently the best-performing application scenario for large language models, but this scenario is not universally representative. A more accurate description is a special case with generality.
Generality means that coding outputs the universal language of Agents, which can directly drive different types of Agents to assist in completing a wide variety of tasks in scenarios with good digital foundations (where processes and files are already digitized and driven by algorithms). From this perspective, it's no accident that Anthropic's Claude Code, specializing in coding, and OpenAI's GPT Codex are the most popular Agent products on the market.
The special case refers to the significant advantages the coding scenario possesses in the model's post-training phase. First, deterministic signal feedback: the code generated by the model is run once, and compilers, interpreters, unit tests immediately provide precise, structured, unambiguous judgments of right or wrong. Second, on this basis of automatic signal feedback, an efficient automated post-training closed loop can be formed, seamlessly feeding the feedback into the reinforcement learning loop. The intelligent agent rapidly generates, encounters errors, and self-corrects within a digital sandbox. Such autonomous training environments are rare in other scenarios, often even impossible to form.
Once leaving coding, the efficiency of model training drops significantly. In traditional business worlds with relatively low digitization and where automatic post-training closed loops cannot form—such as management decision-making, legal negotiations, clinical medicine, supply chain logistics—the costs of data collection and result verification would consume any token economy. Intelligent agents unable to obtain low-cost feedback signals cannot undergo exponential self-evolution, making it difficult to replicate their huge success in coding.
In February 2023, A&O Shearman (formerly Allen & Overy) took the lead in establishing an exclusive strategic partnership with Harvey AI, a vertical large model company in the legal field, deploying the latter's AI legal assistant across the former's 43 offices worldwide 18. During a trial period lasting several months, A&O Shearman's more than 3,500 lawyers globally submitted approximately 40,000 queries to Harvey, covering multiple legal workflows like contract drafting, regulation retrieval, due diligence, etc., indeed improving work efficiency 19.
The other side of the coin: A&O Shearman explicitly stated in its official press release that all outputs generated by Harvey AI require careful review by practicing lawyers before use 18. AI did not truly replace lawyers' professional judgment, merely adding an AI preliminary review layer on top of the original workflow. When senior partners received AI-annotated contract drafts, the time spent on review was almost equivalent to reviewing the original contract from scratch. Of course, the results of human review are high-value data for subsequent model training, but clearly, the cost of such feedback is much higher compared to an automatic closed loop like coding. It cannot be ruled out that when feedback data accumulates to a certain critical point in the future, the performance of intelligent agents in real-world scenarios will improve significantly, approaching or even surpassing professional levels. But compared to coding, the arrival of this critical point still has a long way to go.
The Difficult Leap to the Physical World
Legal work tasks primarily still involve a large amount of text processing, a scenario with a high level of digitization that is certainly becoming highly digitized. When the proportion of tasks that can be digitized, directly controlled, and operated from the digital world decreases, the proportion of tasks intelligent agents can complete also decreases accordingly. Although most real-world facilities are software-driven, relying solely on intelligent agents writing code to control the physical world still faces huge obstacles.
Taking the development of humanoid robots as an example, although they have surpassed the best human records in marathon races, humanoid robots still struggle with most real-world tasks. Cleaning, moving objects, opening doors, navigating cluttered scenes—actions effortless for humans are immense challenges for robots. As Moravec (1988) said, "It is comparatively easy to make computers exhibit adult-level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility." Nearly forty years later, the truth of this statement is still rising 23. In her long article "From Words to Worlds," Li Fei-Fei listed spatial intelligence and embodied intelligence as medium-term goals requiring a longer time to mature 8. The reason is that the real world has no compiler; the physical world does not accept iteration, only verification. And the cost of verification is always higher than the cost of generation.
Simulation technology, once highly anticipated, has shown some effectiveness, but there's still a long way to go to achieve efficiency similar to Agent self-adaptation in coding scenarios. Simulation technology aims to bypass the problem of the physical world lacking a compiler, using digital twins and physics engines to build a virtual verification space. But embodied intelligence development still collides with the Simulation-to-Real Gap. The optimal control trajectories trained in simplified sandboxes using massive tokens become extremely fragile upon encountering real-world friction, material fatigue, and environmental noise. Aljalbout et al., (2025) argue that the Sim-to-Real gap is not a single problem but results from the superposition of multiple sub-gaps: dynamics differences, perception distortions, actuator nonlinearities, system design flaws, etc. A perfect simulator is computationally infeasible 20.
Moreover, simulation training strategies often exploit inaccurate but deterministic boundary conditions in modeling to achieve deceptively high performance. But when deployed in real environments, these strategies are often unreliable and may even pose risks. For example, OpenAI's Dactyl dexterous hand project used 64 NVIDIA V100 GPUs and 920 32-core CPU servers to accumulate training experience equivalent to 13,000 years in simulation, achieving extremely high success rates in manipulating blocks 21. However, when facing non-preset material, temperature, and wear changes in the real world, the dexterous hand's robustness rapidly declined. In 2021, OpenAI disbanded its entire robotics team. Co-founder Wojciech Zaremba explained the decision, stating that resources needed to be shifted to areas where achievements were easier to attain 22. Although officially not listing the Sim-to-Real Gap as the main reason, the industry widely believes the contradiction between the high computing cost of simulation training and the uncertainty of real-world deployment was a key factor prompting OpenAI to abandon the robotics direction.
Verifying model performance in the real physical world incurs time and capital costs orders of magnitude higher than in the virtual world, and such real-world testing is irreplaceable. This asymmetry in verification costs illustrates, from one perspective, the special nature of the coding scenario. Algorithms are not omnipotent, nor are tokens.
If the effective application range of tokens remains long-term confined to coding and a few digital scenarios, consistently unable to bridge the chasm from the digital world to the physical world, the sustainability of AI industrialization and industrial AI-ification is called into question. The future of the token economy depends on our ability to extend the effective range of tokens from digital islands to the broader real world. Before real demand in the physical world explodes, token uneconomical may persist for a long time.
Spillover Risks of Token Uneconomical
Token uneconomical is not evenly distributed across the entire AI industry chain. Upstream infrastructure and hardware vendors are reaping huge profits in the current wave of fixed-asset investment fever; midstream model vendors are still competing on product performance, with high capital expenditures squeezing cash flow; downstream application effects vary by person and scenario, with most enterprises still watching and waiting. Industry chain risks are converging in the midstream, where model vendors are establishing small circles of circular financing in capital markets. The accumulated risks of token uneconomical, once erupting, will inevitably affect financial markets and even impact people's livelihood stability.
Uneven Distribution of Industry Chain Risk
The Token-Agent boom is driving massive capital investment upstream into data centers, networks, chip manufacturing, as well as power and energy infrastructure. TSMC's capital expenditure for 2026 is projected to reach $52 to $56 billion 9. Microsoft, Alphabet, Amazon, and Meta's combined AI infrastructure investment from 2025 to 2026 far exceeds $300 billion, climbing towards a scale approaching $700 billion 10. Midstream large model companies are the engine of this wave of AI investment, the anchor for all optimistic AI expectations, the "hope of the entire village." However, despite explosive revenue growth, major vendors remain deeply mired in losses, with computing power procurement costs staying high. OpenAI is not expected to become profitable until around 2030 11. Meanwhile, downstream enterprise users who are actually using Agents, actually burning tokens, have already started controlling costs. After all, seeing no reasonable return yet, setting token budget caps, performing cost attribution, and tightening usage licenses are all logical management actions.
We compared the free cash flow (FCF = operating cash flow - capital expenditure) changes over the past two years and the net profit margins for the most recent year for representative listed companies across the AI industry chain (Figure 4). In 2025, upstream players TSMC (44.5%) and NVIDIA (55.6%) not only had higher net profit margins but also achieved rapid FCF growth of 14.5% and 58.8%. In contrast, downstream players Amazon, Microsoft, and Meta, while their net profit margins remained stable or even improved compared to previous years, saw their FCF decline by 76.6%, 14.8%, and 3.4% respectively, mainly due to significantly increased capital expenditures. The token gold mine hasn't been proven yet; those digging for gold are still investing money, while those selling shovels are already making huge profits.
This situation has repeated multiple times in history. At the beginning of industrial revolutions, with the rise of new technologies, demand first explodes on the investment side and upstream in the industry. Midstream massive capital expenditure becomes huge profits for upstream, while downstream final consumption is just emerging, not yet sufficient to support midstream companies' capacity expansion. Risks converge in the midstream of the industry, with capital and capacity running ahead of real paying demand. In the short term, valuation corrections, idle capacity, and some participants exiting are almost inevitable. In the long term, as long as underlying demand ultimately materializes, the prematurely built data centers, chips, and networks will still find use, becoming the productivity foundation supporting economic growth. For the public and regulators, we need to guard against industry chain risks transmitting outward through financial markets, causing significant economic fluctuations due to risk spillover.
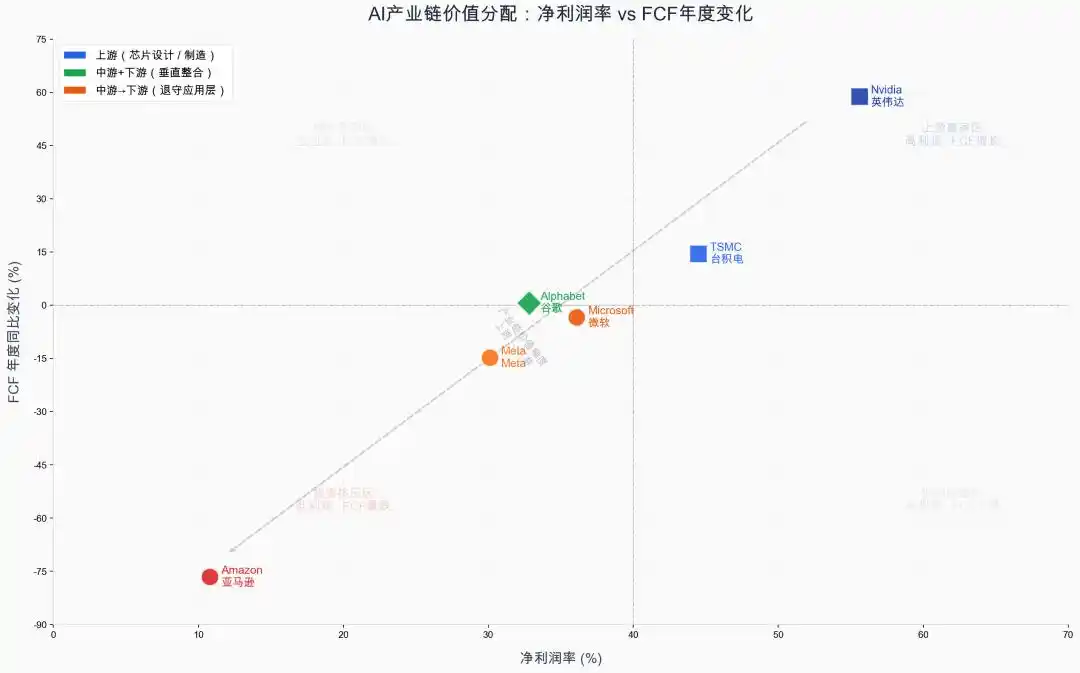
Figure 4: Comparison of Free Cash Flow Growth Rate and Net Profit Margin Across AI Industry Chain Upstream and Downstream (FY2025—2026). Data source: Company annual reports, 10-K SEC filings. Drawing: Codebuddy
Circular Financing and Shadow Credit
Industry chain risks concentrate in midstream model vendors, and some of these midstream model vendors and upstream hardware companies are engaging in circular financing, making it unclear whether it's genuine technology-driven growth or a valuation game supported by capital self-circulation. For example, the "AI Perpetual Motion Machine" formed by OpenAI, NVIDIA, and Oracle: OpenAI first accepts strategic investment from NVIDIA (originally promised $100 billion, later scaled down and participated as part of OpenAI's new funding round); OpenAI then uses the raised funds to purchase cloud services from Oracle (the two signed a 5-year compute purchase contract worth about $300 billion); finally, Oracle uses OpenAI's payment commitment for credit enhancement, issues bonds to raise funds to purchase GPUs from NVIDIA for data center construction, completing the capital loop. Each step seems to have a reasonable business logic, yet each step feels overly "advanced."
OpenAI's total compute procurement framework exceeds $1 trillion, mismatched with its current $33 billion annualized revenue (ARR as of May 2026) 26, based entirely on expectations of future high growth. Once downstream token end consumption cannot bring exponential revenue growth for model vendors, "promises" become "bubbles." And expectations for token end consumption seem not optimistic. According to Bain & Company's calculations, to absorb the 200GW of new computing power expected by 2030, end consumption needs to generate about $2 trillion in new annual revenue. But even factoring in cost savings from AI, there remains a gap of about $800 billion 12.
Such circular financing games also appeared during the dot-com bubble at the turn of the century. But today's valuation bubble is half hidden in the opaque private credit market, making it harder to grasp potential risks accurately. The Fed's interest rate hikes raised rates in high-risk bond markets like startups and leveraged buyouts. Banks, under Basel requirements, had to exit this market, leaving space for private institutions, ultimately creating a U.S. private credit market of about $3 trillion.
Asset managers like Apollo, Ares, Blue Owl, KKR, Blackstone use BDCs (Business Development Companies) and direct lending to provide 20-30 year leveraged financing for data center construction. These loans are often negotiated privately, priced using models (mark-to-model), potentially causing maturity mismatch (matching 30-year future cash flows with technology like LLMs iterating monthly). Simultaneously, because model vendors lack cash, interest is often paid-in-kind (PIK, interest rolled into principal), stacking risks that are not easily noticed.
A Bank for International Settlements report stated that equity markets (primary and secondary) have already fully priced the upside potential of the AI industry chain, but debt markets haven't priced in the downside risk 25. Once downstream demand releases slowly and revenues fall short of expectations, the valuation logic of circular financing collapses (equity compression), models within private credit are forced to be revalued (credit impairment), and the risk of bubble bursting and simultaneous stock and bond crashes surges.
Resource Hunger Squeezes Other Demand
Token consumption-fueled compute expansion creates immense demand for water and electricity from data centers, often creating huge supply gaps in the short term, squeezing local residents' water and electricity needs.
The Data Center Alley in Northern Virginia, USA, hosts the world's densest concentration of data centers, handling about 70% of global internet traffic. Because local grid capacity was locked in early by tech companies through long-term bulk purchase agreements, energy quotas for residents and traditional businesses were severely squeezed. According to a December 2024 report by the Virginia Joint Legislative Audit and Review Commission (JLARC), data center electricity consumption already exceeds twice the output of Virginia's largest nuclear power plant. Merely meeting the energy needs of data centers planned or under construction in Loudoun County alone would require adding generating capacity equivalent to several nuclear power plants to the grid by 2030.
The frantic rush by data centers for high-voltage transmission lines and clean energy forces local utility companies to spend huge sums upgrading the grid. Dominion Energy plans to invest tens of billions over the next fifteen years in grid expansion. This massive infrastructure cost will ultimately be passed on to residents' monthly bills in the form of grid maintenance fees, capacity charges, etc. Capacity auction prices in Dominion's service area have skyrocketed from $29/MW-day to $444/MW-day, an increase of over 1400%, directly reflecting severe scarcity in grid generation and transmission capacity 24. The Piedmont Environmental Council's (PEC) analysis of Dominion Energy's Integrated Resource Plan (IRP) shows that during the plan's coverage period, ordinary residents' electricity bills could double.
The crowding-out effect of compute expansion on daily needs is not limited to Virginia; similar conflicts have occurred in Dublin, Ireland; Jurong, Singapore; Guizhou, China, and other major global compute nodes. In this sense, token uneconomical not only exists in the digital world but also casts a long shadow in real life.
Finding the Token Value Equation
Tokens are one of the most basic production factors of the intelligent era. Like all other production factors—land, data, capital, labor—as long as there is resource misallocation and factor wastage, so-called "uneconomical" conditions will inevitably exist. In this sense, token uneconomical is not just a temporary phenomenon at the beginning of the AI industry chain's explosion but coexists with the token economy, persisting throughout the development of the intelligent economy. In the specific present, the token economy hasn't fully manifested, so token uneconomical is relatively prominent.
Persistent existence doesn't mean letting it run rampant. We can apply force from both supply and demand sides to reduce token uneconomical, strengthen the token economy, and genuinely translate technological development into tangible economic value. The supply side can reduce per-unit token costs through refined technical means, plug leaks and wastages, and prevent risk diffusion. The demand side can continuously discover new application scenarios to make tokens spent worthwhile. When the supply-side cost decline curve intersects with the demand-side value increase curve, the net benefit after offsetting token economy and uneconomical can turn from negative to positive.
Refined Technical-Side Reforms
Context Caching and Semantic Compression. Context Caching has become common practice for model vendors. When multi-Agent pipelines frequently hit historical caches, the billing for input tokens is significantly reduced. However, this approach also has limitations. In complex enterprise-level deployments, due to cache scattering failure caused by highly forked Agent paths, actual cost savings are relatively limited. A more fundamental solution lies in context compression—not simply truncating historical information by sliding windows but performing active compression at the semantic level, retaining key instructions and reasoning chains, removing repetition and redundancy. This Semantic Context Compression can significantly reduce input token consumption while protecting instruction-following rates.
Skill Optimization and Subtraction Thinking. The SkillReducer study by Gao et al., (2026) provides two paths for skill optimization 5. First, description compression: supplementing concise information for skills lacking routing descriptions, compressing redundant background explanations and examples. Second, progressive loading: not stuffing the full skill into context all at once but loading on-demand, achieving up to 39% skill size compression. When combined, they significantly reduce token consumption for skill calls while improving model functionality quality by 2.8%. This shows that Agent skill calls aren't the more, the better. Sometimes, the benefit of subtraction far exceeds that of addition. Reducing invalid information in the context not only lowers token consumption but can also improve the accuracy of model output. "Less is more" here not only aligns with the beauty of code but also makes tokens more economical.
Model Routing and Task Offloading. Using a large model to kill a chicken (overkill) is an important reason for token wastage. Performing adaptive Model Routing based on task complexity, offloading simple, high-frequency subtasks to lightweight open-source models with specific domain capabilities, only invoking expensive Frontier models at key decision points. Such tiered invocation can significantly lower the average token cost per task without sacrificing quality at critical junctures.
Multi-Agent Hard Budget Constraints and Moderator Architecture. Multi-Agent systems without division of labor, budget caps, and clear stopping conditions have a greatly increased probability of turning into marathon tea parties. The solution path is to design a moderator architecture within multi-agent collaboration networks that incorporates Hard Budget Constraints and asynchronous arbitration mechanisms. The Monte Carlo Tree Search method proposed by Luo et al., (2026) adds intermediate-step tool verification in multi-agent processes, saves candidate states, and rolls back when necessary 7. This thinking can be elevated from the reasoning level to the architecture level, setting token budget caps for each subtask, with a moderator Agent monitoring global consumption, forcibly terminating ineffective loops before the budget is exhausted. This not only prevents financial loss of control but often also improves the system's overall efficiency.
Value Anchoring on the Business Side
Token Governance and Cost Discipline. Microsoft restricting Claude Code, Meta removing token consumption leaderboards—big companies have already shifted from simply encouraging token consumption to emphasizing token output and cost discipline 1,2. Quotas, approvals, model routing, cost attribution, team billing—in the future, these measures will likely become basic elements of enterprise AI governance. This is a necessary stage as AI enters production systems. Even if AI is a powerful tool for promoting innovation and accelerating production, the accounts must be clear. How many tokens used, how much verifiable output produced, how much rework caused—all must be measured. Without measurement, there is no management; without caps, there is no discipline. Truly advanced companies won't reward using AI the most, but using the fewest tokens to accomplish the most work.
Rationing will become the norm. Enterprises won't supply tokens infinitely but, like managing cloud computing resources, set budget pools and approval processes. This governance does not oppose technological innovation; on the contrary, rationing will force architects to design more efficient Agent systems, internalizing cost constraints.
Finding Real-World Scenarios for Large-Scale Commercial Token Applications. This is fundamental to achieving a positive net token benefit. Coding and Agent architectures are just small steps toward the token economy. Finding commercial scenarios that can generate huge productivity leaps is a prerequisite for entering the fast lane of token economic development and achieving massive economic value creation. Currently, cases of large-scale application of Agent architectures in real commercial scenarios bringing huge returns are still few and mostly individual cases. Universal solutions applicable to other enterprises and industries are still brewing.
Embodied intelligence and digital twins are expansion directions, but we must face the asymmetric verification costs brought by the Sim-to-Real Gap. A more pragmatic path is finding intermediate zones with weak deterministic feedback within traditional industries, such as image screening in assisted diagnosis (referenced against imaging standards), demand forecasting in supply chains (backtested against historical data), initial contract screening in the legal field (compared against clause templates). The verification costs in these scenarios, while not approaching zero like a compiler, are far lower than pure physical world verification. They are expected to become bridges for the token economy to move from digital sandboxes to the real world. OpenAI's recent restart of robotics research indicates that embodied intelligence, though difficult, cannot ultimately be bypassed.
Returning to ROI
Any investment where the value created exceeds the cost spent, no matter how advanced the technology, will ultimately be unsustainable. Token uneconomical is not a technological failure but a temporary predicament often encountered when technology moves toward large-scale production. Like the steam engine at the beginning of the Industrial Revolution—inefficient, coal-hungry—this didn't negate that the steam engine represented the future direction of productivity development. Through continuous improvements in thermal efficiency and expansion of application scenarios, steam power ultimately became the most fundamental force driving the first stage of the Industrial Revolution. Today's tokens and Agent architectures are like early steam engines—noisy, fuel-guzzling—but have shown potential far beyond human power in specific scenarios. Their subsequent development will inevitably be a series of technological innovations from extensive to refined. In the future, more valuable Agents won't be those with the most complex chains of thought, but those that accomplish tasks with the fewest tokens. When the industry moves from the show-off stage, valuing quantity, to the production stage, valuing precision, when every token spent must answer what value its output brings, when tokens return to the gold standard of ROI, the Agent era will have found its value equation.
This article is from the WeChat public account "Tencent Research Institute" (ID: cyberlawrc), author: Li Gang