Just now, DeepSeek V4 received an update.
It newly launched the speculative decoding framework DSpark, and simultaneously open-sourced the full-stack speculative decoding framework DeepSpec that supports this version.
DeepSeek-V4-Pro-DSpark is not a new architecture model, but rather introduces a speculative decoding module based on DeepSeek-V4-Pro. The focus of this update is on engineering deployment, not iteration of the model's core capabilities itself.
DSpark has been deployed in the real online traffic of DeepSeek-V4 (Flash and Pro), significantly accelerating the inference speed of large language models (LLMs).

Technical Report: DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
Technical Report Link: https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
The core purpose of DSpark is to solve the latency and throughput bottlenecks faced by LLM inference in production environments (especially in high-concurrency scenarios). In short, DSpark successfully combines high-throughput "parallel generation" with adaptive "load-aware verification."
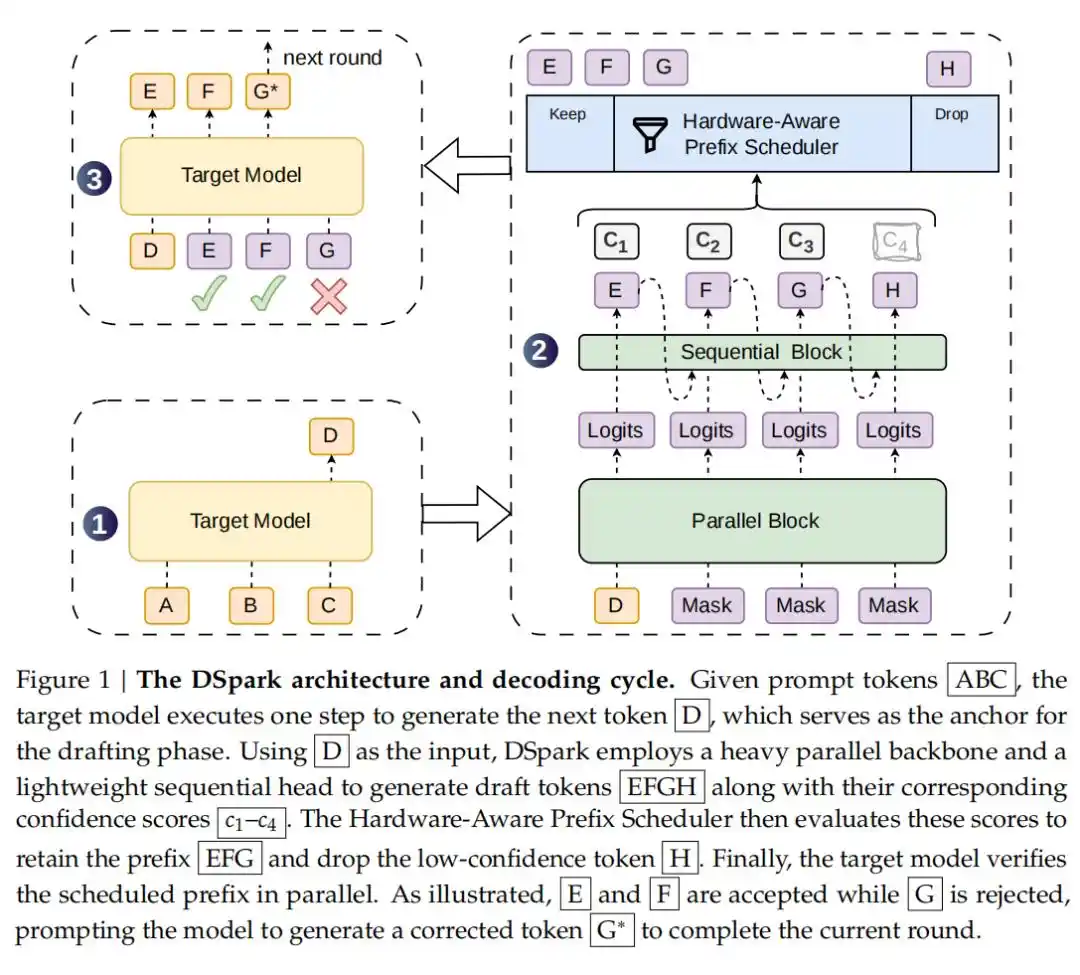
Speculative decoding is a technique to accelerate large language model inference without altering the model's output distribution. Its core idea is to introduce a lightweight "draft model" to pre-generate several candidate tokens, which are then batch-verified and accepted by the target model. This transforms serial, token-by-token generation into parallel, batch verification, greatly reducing end-to-end latency.
Building on this, DSpark's innovation lies in introducing a Semi-Autoregressive Generation architecture: it retains the high-throughput advantage of parallel draft models while incorporating a lightweight serial module to model dependency relationships between tokens within a block. This alleviates the issue of acceptance rate decay that parallel draft models tend to suffer in later positions.
In addition, there is Hardware-Aware Confidence-Scheduled Verification: previous speculative decoding would often blindly send all generated draft tokens for verification. Under high system load, these tail tokens, which have a very high probability of being rejected, waste valuable batch processing computing power. DSpark introduces a Confidence Head to estimate the survival probability of each token. Combined with a hardware-aware prefix scheduler, the system can dynamically tailor the optimal verification length for each request based on real-time engine throughput characteristics, allocating computing power only to tokens with the highest expected payoff.
To be deployed in real online infrastructure, DSpark's scheduler adopts an asynchronous mechanism to be compatible with zero-overhead scheduling (ZOS) and continuous CUDA graph replay. It uses historical predictions from the previous two steps to decide the current dynamic truncation length, thereby hiding scheduling latency, avoiding GPU pipeline stalls, and simultaneously guaranteeing the complete and lossless restoration of the target model's output distribution.
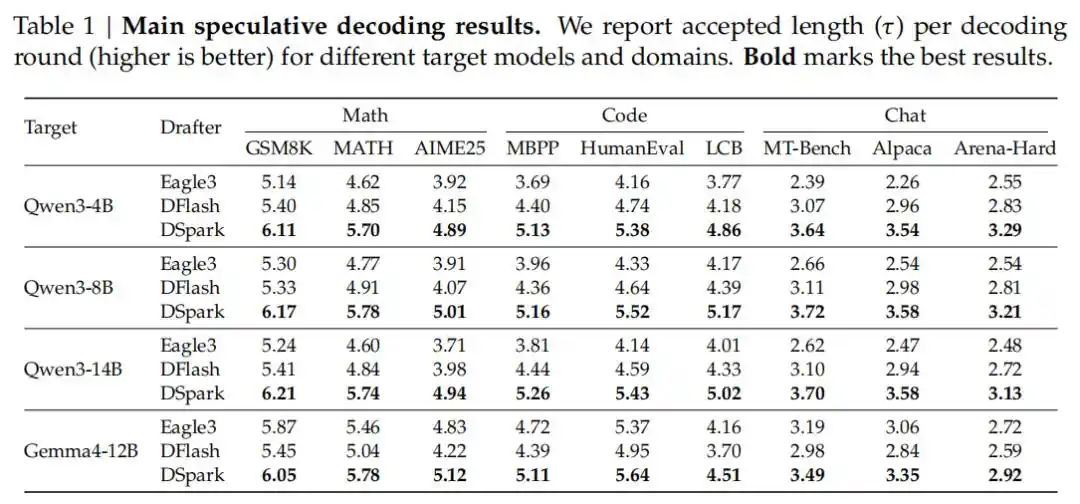
In tests covering multiple domains such as mathematical reasoning, code generation, and daily conversation, DSpark significantly outperformed the current state-of-the-art autoregressive model (Eagle3) and parallel draft model (DFlash). For example, on Qwen3 series (4B, 8B, 14B) target models, its average acceptance length improved by 26.7% to 30.9% compared to Eagle3, and by 16.3% to 18.4% compared to DFlash.
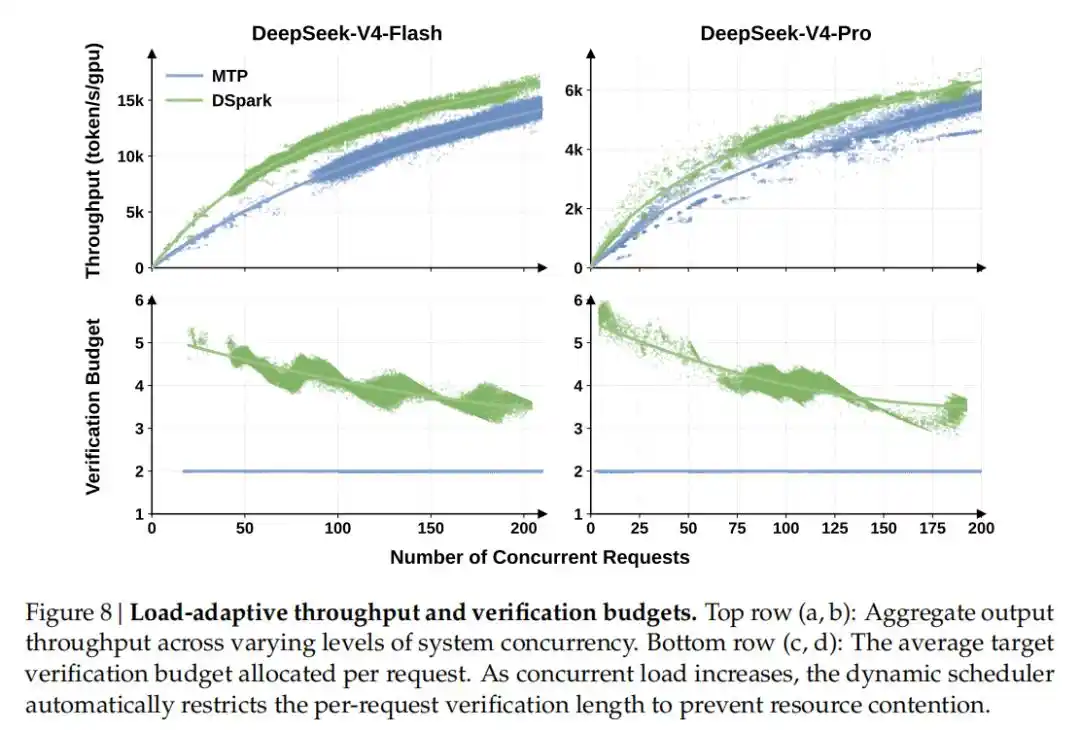
Compared to the previous generation single-token production benchmark (MTP-1) in deployment, while maintaining the same overall throughput, DSpark increased user generation speed by 60%-85% (Flash model) and 57%-78% (Pro model) respectively.
Released alongside DSpark is DeepSpec, a full-stack codebase for training and evaluating speculative decoding draft models. It is the "open-source infrastructure" that hosts this solution and other advanced algorithm implementations, containing data preparation tools, draft model implementations, training code, and evaluation scripts.
DeepSpec splits the overall workflow into three stages: data preparation, training, and evaluation. The three stages need to be run sequentially, with the output of the previous stage serving as input for the next.
In the data preparation stage, one needs to download prompt data, regenerate answers using an inference engine on the target model, and build the target cache. Notably, taking the default Qwen/Qwen3-4B configuration as an example, the target cache volume can reach about 38 TB, requiring thorough assessment of storage resources before use.
The training stage can be launched via bash scripts/train/train.sh. This script will call train.py and launch a worker for each visible GPU. Users can choose different algorithm and target model configurations in the config/ directory by specifying config_path. The project also supports adjusting training settings by overriding config_path, target_cache_dir, and using --opts to modify individual configuration fields.
Regarding hardware, DeepSpec's default configuration and scripts are designed for a single-node 8-GPU environment. If there are fewer GPUs, users need to correspondingly reduce the number of visible GPUs in CUDA_VISIBLE_DEVICES.
The evaluation stage is launched via bash scripts/eval/eval.sh. The evaluation script will use the trained draft model checkpoint to measure acceptance on multiple speculative decoding benchmark tasks. The project's currently listed evaluation datasets include GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca, and Arena-Hard-v2, covering different task types such as mathematical reasoning, code generation, dialogue ability, and comprehensive Q&A.
In terms of algorithms, DeepSpec currently has three built-in draft models: DSpark, DFlash, and Eagle3. For target model series, the project currently supports Qwen3 and Gemma.
The open-sourcing of DeepSpec integrates the engineering practices of speculative decoding, which were previously scattered across various research teams, into a reproducible and extensible standardized toolchain. For researchers and engineers hoping to accelerate inference for their own large models, this means they can directly train custom draft models on a mature framework, skipping a large amount of repeated infrastructure building work.
Reference Links:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), authors: Ze Nan, Yang Wen





