Crypto analyst RLinda had previously predicted that the Dogecoin price was headed for a correction. This comes after the meme coin rallied alongside Bitcoin, moving more than 10% to cross the $0.27 target in good time. However, there was a significant amount of resistance that was being mounted at this level, triggering the first wave of corrections. This correction is what the analyst predicted, and with the price nearing the support level, we take a look at the rest of the forecast.
The Reason For The Pullback
In the analysis, which was shared on the TradingView website, RLinda highlighted the fact that the initial Dogecoin price rally was the result of a breakout from downward resistance. The resulting rally had pushed the altcoin upward, ultimately landing on its local maximum price of $0.27. The next phase was simply correction and consolidation as bulls struggled to find firm ground.
The Dogecoin price retracement was further fueled by the Bitcoin price slowdown after hitting a new all-time high. Bitcoin had encountered resistance just above $126,000, and the result was a beatdown back into the $121,000 territory. Naturally, the performance of altcoins in comparison to Bitcoin is always heightened. Hence, altcoins suffered more losses than the leading cryptocurrency.
There has always been a lot of profit-taking in the market, as investors are now more inclined to pull out profits quickly due to the market performance over the last year. Given this, there is now increased bearish pressure at the local maximum price level, making it the target to beat if the Dogecoin rally is to continue.
Where Dogecoin Price Is Headed Next
With the sell-offs mounted at $0.2653-$0.2694, which the analyst predicted, the Dogecoin price has been beaten back down toward $0.2466, known as the first support level. There is demand around this area, meaning there is the possibility that a bounce will form from here.
However, there are still other support levels that bears could test to show dominance in the market. The other two targets outlined in the analysis are $0.2431 and $0.2376. Both of these lie at demand levels and carry very high chances of a reversal. If this level holds, then there is a possibility that the price bounces back to $0.28.
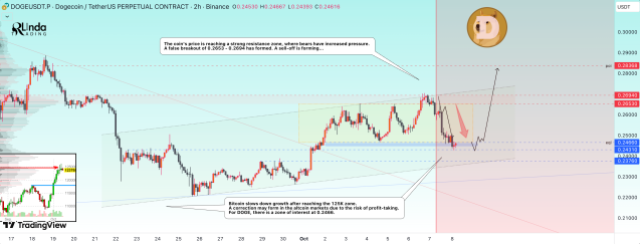
“The support zone that is of interest to the market is 0.2466, and this zone is quite capable of stopping the decline,” the analyst explained. “A false breakdown and holding the price above 0.246 – 0.243 may renew interest in growth.”
Related Posts