Nota del editor: Recientemente, el debate sobre la IA y el trabajo ha estado dominado casi por completo por una pregunta: a medida que continúe mejorando la capacidad de los modelos, ¿se verán reemplazados masivamente los puestos de trabajo de cuello blanco? Desde la generación de código y la automatización del servicio al cliente hasta la producción de contenido, los agentes están asumiendo constantemente ese trabajo intelectual que antes requería de humanos. Las pruebas de referencia también refuerzan esta ansiedad: el rendimiento de los modelos en razonamiento a nivel de posgrado, tareas económicas reales y refactorización de código a nivel de ingeniero senior está mejorando rápidamente, lo que parece acercarnos a un punto de inflexión en el que "el trabajo humano sea devorado por la automatización".
Pero Dan Shipper, CEO de Every, propone en este artículo una observación contraria: cuanta más automatización, más trabajo parece haber para los humanos. Every es un usuario avanzado de agentes de IA y ha integrado herramientas como Codex, Claude Code, Slack Agent y agentes de servicio al cliente en sus procesos de codificación, escritura, diseño, atención al cliente y gestión. Sin embargo, el resultado no ha sido el reemplazo total de los empleados, sino una reconfiguración de las formas de trabajo: los ingenieros ya no solo escriben código, sino que lo revisan, refactorizan y diseñan sistemas; los editores ya no solo redactan artículos, sino que deciden qué vale la pena escribir y cómo hacerlo de manera diferente; el personal de atención al cliente ya no gestiona cada ticket básico, sino que mantiene un sistema capaz de responder automáticamente a los clientes.
Lo más interesante de este artículo no es si "la IA puede realizar una tarea determinada", sino cómo redefine el lugar de los humanos en el trabajo intelectual. La IA se destaca en abaratar capacidades ya sedimentadas en el pasado: código, textos, miniaturas, respuestas de atención al cliente, descripciones de productos, informes de investigación... todo puede ser generado rápidamente por los modelos. Pero cuando estas capacidades están al alcance de todos, lo que suele aparecer en el mercado no es una producción diferenciada y de alta calidad, sino una gran cantidad de "resultados predeterminados" que parecen similares y carecen de juicio y sentido del contexto. En otras palabras, la IA convierte en mercancía "la capacidad humana de ayer", mientras que lo realmente escaso es el criterio para enfrentar los problemas concretos del presente.
Por lo tanto, la automatización no elimina a los expertos, sino que crea más escenarios que requieren su intervención. Cuando el personal de operaciones puede usar la IA para enviar código, los ingenieros necesitan juzgar qué código vale la pena fusionar; cuando el personal de marketing puede generar miniaturas en segundos, los diseñadores necesitan juzgar qué se ajusta a los objetivos de marca y comunicación; cuando los ingenieros también pueden escribir artículos, los editores necesitan transformar el borrador en un contenido realmente con perspectiva, estructura y listo para publicar. La IA amplía el radio de producción, pero también magnifica la necesidad de control de calidad, construcción de sistemas, juicio de límites y expresión diferenciada.
El autor utiliza además pruebas de referencia para explicar esta paradoja. Tanto el Senior Engineer Benchmark como el GDPval de OpenAI no miden la "inteligencia en sí" en un sentido abstracto, sino el rendimiento del modelo dentro de un marco de problemas específico. El prompt, los límites de la tarea, los criterios de evaluación y el formato de salida ya contienen una gran cantidad de juicio humano. Los modelos pueden progresar rápidamente dentro del marco, pero el marco en sí lo establecen las personas; cuando un marco es superado por un modelo, los humanos llevan el problema a un nuevo marco más complejo.
Esta es también la respuesta más interesante del artículo a la ansiedad por la AGI: incluso si los modelos se vuelven más fuertes, lo que alcanzan suele ser un límite trazado por los humanos, no al propio trazador de límites. La IA puede ejecutar objetivos, optimizar rutas y mejorar la eficiencia, pero mientras siga respondiendo a problemas establecidos por humanos, seguirá careciendo de una subjetividad verdaderamente significativa. El futuro del trabajo intelectual no es la desaparición humana de los procesos, sino su transición de ejecutores a diseñadores de marcos, mantenedores de sistemas, evaluadores de calidad y definidores de significado.
Después de la automatización, el valor del trabajo humano no desaparece, solo se vuelve más difícil, más anticipado y más dependiente del criterio. La IA abarata el "saber hacer", pero hace que "saber qué vale la pena hacer, por qué hacerlo y hasta qué punto está bien hecho" sea más escaso.
A continuación, el texto original:
En el corazón de la IA hay una paradoja.
En Every, hemos automatizado todo lo que se puede automatizar. Ya sea codificación, escritura, diseño, atención al cliente u otras tareas diarias, utilizamos Codex y Claude Code. Participamos en pruebas alfa antes del lanzamiento oficial de nuevos modelos de OpenAI, Anthropic y Google. Podemos decir que nos estamos subiendo lo más rápido y profundo posible a la ola de mejora exponencial de la inteligencia de los modelos y la capacidad de automatización.
Pero, paradójicamente, para nosotros, el trabajo que los humanos necesitan completar parece ser mayor que nunca. Every es actualmente un equipo de cerca de 30 personas. No hemos despedido a todos los empleados por tener agentes; ni hemos abandonado las herramientas SaaS para depender completamente de aplicaciones hechas con "vibe coding". Seguimos contratando agentes humanos de atención al cliente, aunque con mucha ayuda de agentes; también seguimos contratando autores, editores e ingenieros.
Sin embargo, la forma del trabajo ha cambiado enormemente. Casi ya no escribimos código a mano. Si mencionas a alguien en Slack, a veces no está claro si es una persona o un agente. Los gerentes comienzan a enviar código como contribuyentes individuales de primera línea, y los ingenieros también se enfrentan directamente a los clientes. En las últimas semanas, el 95% de mis correos electrónicos de trabajo han sido respondidos por IA. Mi bandeja de entrada casi siempre ha estado vacía —algo extremadamente raro para mí—, pero aún reviso cada correo.
En otras palabras, el futuro se ve extraño, pero sorprendentemente familiar.
Esta "sensación de familiaridad" es en sí misma sorprendente. Porque CEOs, trabajadores del conocimiento e inversores parecen creer cada vez más en lo mismo: la IA está amenazando el empleo, la economía, la seguridad e incluso el significado del trabajo humano.
Dario Amodei, CEO de Anthropic, advirtió que la IA podría eliminar hasta la mitad de los puestos de trabajo de cuello blanco junior. Meta despidió recientemente a 8000 personas y comenzó a instalar software en las computadoras de sus empleados en EE. UU. para registrar movimientos del mouse, clics y entradas del teclado, con el fin de obtener datos de entrenamiento de mayor calidad para trabajos intelectuales avanzados.
Incluso Ken Griffin, fundador de Citadel, pareció bastante conmovido. Recientemente declaró: "No se trata de puestos de cuello blanco de nivel medio-bajo, sino de puestos de altísima habilidad, que están siendo —elijo esta palabra con cuidado— automatizados por la IA agentica".
Varias pruebas de referencia parecen respaldar esta evaluación. Con cada nueva generación de modelos, los indicadores de capacidad mejoran a un ritmo casi exponencial. En Humanity's Last Exam, una prueba de razonamiento a nivel de posgrado, la puntuación de los mejores modelos pasó de un solo dígito hace un año a alrededor del 44% hoy. En GDPval, que mide la capacidad de los modelos de vanguardia para realizar trabajos económicos reales y los compara con el rendimiento humano, la puntuación también saltó desde niveles similares bajos a aproximadamente el 85%. En mayo de este año, METR, una organización sin fines de lucro de investigación en seguridad de IA, publicó los primeros resultados de las pruebas de Claude Mythos: en algunas tareas que a los expertos humanos les llevan unas 4 horas completar, el modelo logró una tasa de éxito del 80%.
Parece que estamos al borde de un punto de inflexión: una IA más inteligente que cualquier humano y capaz de trabajar de forma autónoma casi todo un día se acerca a la realidad.
Sin embargo, la paradoja persiste. Si hablas con profesionales de la industria de la IA, o con aquellos primeros usuarios fuera de la industria, escucharás la misma conclusión que nuestra observación interna: hay más trabajo que hacer que antes.
La verdadera preocupación dentro y fuera de la industria es: ¿es esto solo un estado de transición? ¿El próximo lanzamiento de un modelo será el momento que realmente reemplace a todos? Observamos las curvas de las pruebas de referencia, emocionados y nerviosos, preocupados de que en cualquier momento llegue un punto de inflexión en el que una gran cantidad de trabajos desaparezcan de repente.
Pero creo que no habrá tal "punto de inflexión" que llegue de repente, voltee todo de un golpe y haga desaparecer masivamente los trabajos. La nueva realidad es precisamente la contraria: cuanto mayor es el grado de automatización, más trabajos requieren la participación de expertos humanos.
La razón es que la IA está mercantilizando aquellas partes de la capacidad profesional humana que pueden expresarse claramente, entrenarse y replicarse. Cualquier conocimiento que pueda escribirse como reglas, sedimentarse en procesos o convertirse en datos de entrenamiento, gradualmente se convertirá en la capacidad predeterminada de los modelos. El resultado es que el valor de la salida de los modelos comunes se deprecia rápidamente, y el mercado comienza a necesitar con más fuerza cosas diferentes.
Y la necesidad de "lo diferente" es, en esencia, una necesidad de expertos humanos. Incluso si nos acercamos a la inteligencia artificial general, esto no desaparecerá.
Para entender el porqué, no basta con mirar las curvas de las pruebas de referencia, ni fijarse solo en los parámetros y clasificaciones de capacidad de los modelos. Debemos regresar a los escenarios de trabajo reales y ver cómo se usa realmente la IA hoy. Solo así podremos entender verdaderamente esta paradoja y la respuesta que hay detrás.
Cómo llegamos hasta aquí
Desde 2022, hemos estado observando el impacto de los agentes en el trabajo futuro.
Hace tres años, escribí un artículo sobre la "economía de asignación" (allocation economy). Mi evaluación entonces era que colaborar con herramientas de IA acabaría pareciéndose cada vez más al trabajo de un gerente humano: ya no realizas cada acción personalmente, sino que desglosas, asignas, supervisas y aceptas tareas. En ese momento, la pregunta y respuesta más básica en ChatGPT todavía era vista por muchos como algo futurista e incluso inquietante.
A mediados de 2025, la empresa Every estaba casi completamente "Claude Codificada". Kieran Klaassen, gerente general de Cora, descubrió de repente que podía abandonar la escritura manual de código y pasar todo el día dando instrucciones en lenguaje natural a un agente de programación en la terminal. Esta forma de trabajo se extendió rápidamente por toda la empresa. Hace unos 12 meses, dije en el podcast de Lenny que Claude Code era la herramienta más subestimada del trabajo intelectual.
Menciono esto porque algunos de nuestros juicios más acertados en el pasado han surgido de observar Every como un laboratorio de adopción temprana. Muchos de los nuevos modos de trabajo aparecen primero internamente; luego, a medida que la tecnología madura y las herramientas se vuelven más fáciles de usar, estos patrones se difunden gradualmente a un mercado más amplio.
Y ahora, están ocurriendo nuevos cambios internamente.
Dos modos de colaborar con agentes
Las formas de trabajo en torno a la IA están convergiendo gradualmente en dos modos muy diferentes.
El primero es una dirección ya prevista con cierta precisión en discusiones anteriores sobre IA: tratar al agente como un empleado. Estos agentes pueden recibir tareas asignadas. Algunos viven en Slack, tienen su propio nombre y responsabilidades, y cuando los necesitas, puedes mencionarlos directamente; otros están integrados en flujos de trabajo en ejecución continua, como sistemas de atención al cliente, actuando como puerta de entrada y filtro de tareas repetitivas las 24 horas.
El segundo modo es más extraño, pero en mi experiencia, también más importante. Se refiere a la colaboración humano-agente en herramientas como Codex, Claude Code y Claude Cowork. Estas herramientas no son solo lugares donde delegas tareas; se están convirtiendo en el sistema operativo del trabajo mismo: tú y varios agentes usan la misma "computadora", colaborando en el mismo entorno de trabajo para completar tareas altamente complejas, originales y que no pueden simplemente entregarse a un agente asíncrono.
En ambos modos, puedes usar la IA para automatizar y delegar una parte considerable del trabajo. Pero para que ambos modos funcionen realmente bien, aún necesitan de ti, o de otro humano, participando en ellos.
Agentes empleados
Un agente empleado es aquel al que le das una tarea y, fuera de tu participación en tiempo real, produce de forma independiente una respuesta, una acción, un informe, un borrador o un juicio de clasificación.
Estos agentes tienen al menos dos formas: los "agentes colegas" y los "agentes integrados".
1. Agentes colegas
Los agentes colegas son aquellos a los que puedes llamar en Slack como si fueran un colega, para que realicen un trabajo. Están siempre disponibles y se pueden invocar cuando se necesitan. Productos como OpenClaw, o nuestro desarrollo interno Plus One, pertenecen a este tipo.
Claudie
Claudie es un agente colega que utiliza nuestro equipo de consultoría. Escribe propuestas de ventas, genera borradores de material de formación, realiza seguimiento de tareas pendientes de proyectos y puede manejar más trabajos similares.
Andy
Andy es un agente colega que utiliza nuestro equipo editorial. Recopila de los canales internos de Slack de la empresa aquellos "puntos de material" que merecen ser desarrollados —es decir, buenas ideas que podrían convertirse en artículos— y los organiza en resúmenes y puntos de vista preliminares para que los autores los usen en la redacción del boletín diario.
Viktor
Viktor es un agente de propósito general que realiza trabajos interdepartamentales dentro de la empresa. Lo usamos para recopilar métricas de crecimiento, analizar resultados de estudios de usuarios y también para organizar discusiones internas caóticas en memorandos de investigación y sugerencias de productos.
2. Agentes integrados
Los agentes integrados existen en flujos de trabajo de productos específicos. Son menos flexibles que los agentes colegas, pero suelen ser muy potentes al manejar tareas repetitivas.
Fin es el ejemplo más claro. Es un agente integrado en nuestra plataforma de atención al cliente que puede manejar una gran cantidad de trabajo de soporte a través de chat y correo electrónico.
En una semana de mayo de este año, Fin participó en el 65% de las 202 conversaciones de atención al cliente de Every, y cerró de forma independiente 81 tickets sin intervención humana, lo que representa el 40.1% de todas las conversaciones manejables.
Este tipo de agentes integrados permiten que nuestro gerente de atención al cliente, Waqqas Mir, dedique menos tiempo a responder tickets básicos y más a construir "sistemas capaces de responder automáticamente a los tickets", así como a manejar aquellos casos de clientes que requieren un contacto más alto y juicios más complejos.
Colaboración humana con IA
Tanto en el caso de los agentes colegas como de los integrados, el patrón subyacente es consistente: los agentes empleados están asumiendo más capas de trabajo estables, repetitivas y con límites claros.
Pero aún queda una gran cantidad de trabajo que requiere participación humana. Una y otra vez hemos descubierto que, siempre que la tarea sea lo suficientemente compleja, la mejor manera de obtener un resultado verdaderamente de alta calidad no es entregar el trabajo completamente a la IA, sino hacer que la IA y los humanos colaboren de ida y vuelta en un mismo espacio de trabajo.
Este es precisamente el valor de herramientas como Codex, Claude Code y Cowork. Te permiten iniciar uno o más agentes en múltiples hilos de chat y delegarles tareas. Estos agentes pueden acceder a tu computadora y a todas las fuentes de datos relevantes. Puedes ver qué tarea está ejecutando cada agente, cómo está pensando, y puedes interrumpirlo en cualquier momento.
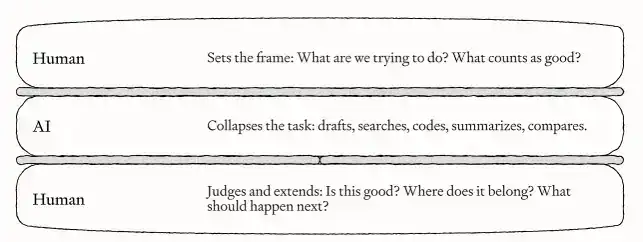
Al mismo tiempo, tú sigues siendo responsable de gestionar estos agentes: definir la dirección al inicio de cada tarea, verificar la calidad al final, asegurarte de que el resultado sea lo suficientemente bueno y encontrar la siguiente tarea que valga la pena avanzar. Kieran llama a este rol el "sándwich humano": la IA se encarga de la parte intermedia del trabajo, mientras que los humanos, como las dos rebanadas de pan, están al principio y al final de la tarea.
El ejemplo más típico es escribir código. En Every, los ingenieros pasan casi todo el día colaborando de ida y vuelta con agentes. Planifican juntos nuevas funcionalidades o correcciones de errores, revisan el trabajo ya realizado; y si adoptan lo que llamamos la filosofía de "ingeniería compuesta" (compound engineering), optimizan continuamente su sistema para que sea más útil con el tiempo.
Pero esta forma de colaboración va mucho más allá de la codificación.
El nuevo sistema operativo del trabajo intelectual
Codex y Claude Code se están convirtiendo en un nuevo sistema operativo para el trabajo. Paso casi todo el día dentro de Codex, ejecutando varias herramientas SaaS a través de su navegador integrado. Me permite llevar agentes a cada escenario de trabajo y alcanzar un nivel de desempeño que no podría lograr por mí solo.
Escritura
Este artículo lo escribí en Proof, dentro del navegador integrado de Codex. Codex observa lo que estoy escribiendo y puede iniciar en cualquier momento un subagente para completar cualquier tarea que necesite: redactar el borrador de un párrafo, buscar ejemplos para la siguiente parte, o realizar edición y pulido de texto.
Correo electrónico
Al manejar el correo, uso el mismo enfoque. Cora es mi cliente de correo; lo abro en el navegador integrado de Codex y, mientras reviso la bandeja de entrada, voy diciendo en voz alta a través de Monologue cómo quiero manejar cada correo. El resto lo hacen Codex y Cora.
Cada agente necesita un humano
En todos los escenarios de automatización anteriores, quizás ya puedas ver dónde actúan los humanos. En cada ejemplo, el agente necesita participación humana para que el trabajo funcione realmente.
Alguien tiene que dirigirlo hacia el problema correcto, juzgar si la producción es lo suficientemente buena, detectar dónde se equivoca y convertir el resultado en una decisión o proceso en el mundo real.
Cuanto más lejos esté un agente del humano responsable de supervisar su desempeño, peor suele ser su efectividad. En la promoción interna inicial, dimos un agente a cada empleado. Pero pronto retrocedimos a que los agentes sirvieran a un equipo específico, o a toda la empresa, en lugar de a un solo individuo.
La razón es simple: los agentes requieren mucho mantenimiento. Un agente personal, una vez que su usuario deja de seguirlo, rápidamente se vuelve obsoleto e ineficaz. Tenemos un equipo de ingenieros de IA dedicado a garantizar que estos agentes funcionen de manera estable y efectiva. Y en un futuro previsible, seguiremos necesitando este equipo. Incluso una tarea aparentemente simple como "generar automáticamente PowerPoint" puede convertirse en un enorme proyecto de ingeniería. Uno de nuestros flujos de automatización de PowerPoint contiene 24 habilidades y 18 scripts, y generar una presentación cuesta 62 dólares en tokens.
Esta es la primera razón por la que los agentes, de hecho, crean más trabajo para los humanos.
Pero hay una segunda razón.
Por qué la automatización genera más trabajo humano
Si observas el crecimiento exponencial de la capacidad de la IA en los últimos años, combinado con su arquitectura y fuentes de capacidad, verás un claro ciclo de retroalimentación: están creando constantemente más trabajo humano.
La IA abarata "la capacidad humana de ayer"
Los actuales modelos de lenguaje grande se entrenan con los rastros visibles dejados por la capacidad humana: código, artículos, imágenes, tickets de atención al cliente, documentos de especificaciones de productos y más. Absorben este contenido, es decir, los "gases de escape" de tareas que ya se completaron con éxito, y los reempaquetan en una forma de bajo costo y accesible para todos.
El resultado es que muchas capacidades antes escasas, como enviar un pull request de código, crear una miniatura de YouTube o redactar un boletín informativo, ahora están abiertas a casi todos.
Las capacidades baratas se adoptan rápidamente
Cuando algo que antes era escaso se abarata, la oferta aumenta rápidamente.
En Every, hemos estado viendo este cambio. El personal de operaciones y atención al cliente comienza a escribir código y enviar pull requests; el personal de marketing comienza a crear miniaturas de YouTube; ingenieros y personal de producto también comienzan a escribir artículos, guías y borradores de páginas de destino, trabajos que antes no solían asumir.
Este cambio también ocurre fuera de Every. Tomemos como ejemplo el proyecto de agente de IA de código abierto OpenClaw. Al 16 de mayo de 2026, su repositorio de código había recibido 44,469 pull requests, de los cuales 12,430 eran posteriores al 1 de abril y 3,990 posteriores al 1 de mayo. Esta es una cantidad asombrosa. A modo de comparación, Kubernetes, uno de los proyectos de código abierto más populares del mundo, recibió solo 5,200 pull requests en todo 2022.
La abundancia trae homogeneización: la capacidad experta antigua se mercantiliza
Debido a que todos pueden usar los mismos modelos, y estos modelos se construyen sobre "la capacidad humana de ayer", de forma predeterminada, lo que producen los modelos suele estar entre un "punto de partida decente" y "contenido basura puramente de IA".
Aquí, "contenido basura" no se refiere a un error específico. No es el uso excesivo de guiones, ni una frase fija, ni los toques de color púrpura que aparecen por todas partes en una página de destino. Se refiere a una homogeneización visible, repetitiva y cansada.
Cuando humanos en diferentes contextos usan el mismo conjunto de herramientas, y estas herramientas se entrenan con el mismo tipo de corpus, y los usuarios no ejercen un juicio lo suficientemente profundo, se produce este resultado. En otras palabras, cuando todos tienen un "experto" con la misma inclinación y estilo predeterminado, la homogeneización ocurre naturalmente.
Cuando el personal de operaciones puede enviar pull requests, el personal de marketing puede generar miniaturas de YouTube en segundos y los ingenieros comienzan a escribir guías de producto, es fácil llegar a una situación en la que tu producción aumenta en cantidad, pero la calidad, coherencia y diferenciación de tu trabajo disminuyen.
Y una homogeneización excesivamente abundante rápidamente se convierte en una mercancía.
La homogeneización crea demanda de diferenciación
Debido a Internet, los humanos pueden identificar rápidamente qué contenido tiene un "olor a IA" excesivo, producido en línea de ensamblaje. Cualquier trabajo puede llegar instantáneamente a otras personas en el mundo, y de hecho a menudo lo hace. Una vez que demasiadas cosas comienzan a parecerse, rápidamente notamos que algo anda mal.
Esto significa que, la primera vez que ves la capacidad de un nuevo modelo, puedes quedar impresionado o incluso asustado. Pero unos meses después, esa capacidad se vuelve común. No es que el modelo se haya debilitado, sino que tu estándar ha cambiado.
Ya no nos conformamos con cualquier aplicación React o cualquier informe de investigación. Queremos algo realmente adaptado a una persona, empresa o situación concreta. Debe sentirse preciso, vivo, específico, no barato, genérico, de plantilla. Esperamos que su costo de producción, ya sea en tiempo o dinero, sea claramente superior a nuestro costo de consumo.
Queremos algo con "sensación de estatus". Y cada vez que una nueva tecnología abarata algo que antes tenía un alto estatus, los humanos siempre somos expertos en inventar nuevos juegos de estatus para coincidir con los nuevos límites de capacidad.
Cuando el trabajo se vuelve excesivamente abundante y todo parece similar, aquellos trabajos que no se ajustan a los patrones existentes se convierten en algo escaso, valioso y de alto estatus.
La demanda de diferenciación es, en esencia, una nueva demanda de expertos
Precisamente debido a las características arquitectónicas de los modelos de lenguaje y a su amplia distribución a casi todos, el trabajo escaso y valioso aún debe provenir de los humanos.
La generación actual de modelos solo conoce el trabajo que ya ha sucedido, que ya se ha completado. Los humanos saben: en este momento preciso, qué es lo que realmente necesita hacerse.
Una vez que una situación concreta se reduce a texto, una vez que entra en un corpus, ya se ha convertido en "algo del pasado". Los humanos enfrentan un momento, cliente, base de código o conversación concretos, y el corpus de entrenamiento no vive realmente en este presente. Este estado de "estar vivo" no es solo tener datos más actualizados. Llegamos al presente con nuestro origen, y con deseos, preocupaciones y juicios en constante cambio, para comprender qué es importante. Son estas perspectivas en constante actualización las que cambian lo que vemos. Los modelos pueden adoptar esta perspectiva después de ser "prompteados", pero antes del prompt, no la poseen de forma natural.
Esta es precisamente la paradoja que mencionamos al principio: abaratar el trabajo experto no simplemente reemplaza a los expertos. Por el contrario, crea más escenarios que requieren el juicio experto.
Cuando el personal de operaciones, con ayuda de la IA, envía pull requests, necesitas ingenieros para revisarlos.
Cuando el personal de marketing crea miniaturas de YouTube, necesitas diseñadores para refinarlas.
Cuando los ingenieros comienzan a escribir artículos, necesitas autores y editores para convertir el borrador en un contenido realmente legible y publicable.
Frente a esto, los expertos humanos se moverán en dos direcciones simultáneamente.
Algunos expertos usarán la IA para construir sistemas destinados a absorber y aprovechar este torrente de trabajo nuevo: colas de revisión, sistemas de evaluación, marcos de ejecución, reglas de repositorios de código, archivos de instrucciones para Claude y Codex, integración continua (CI), gestión de permisos y flujos de trabajo que transformen borradores en resultados de alta calidad.
Otros expertos usarán la IA para realizar trabajos más grandes e interesantes que antes no podían hacer por sí solos. Por ejemplo, encontrar vulnerabilidades en sistemas operativos como macOS suele llevar semanas o meses. Pero una pequeña empresa de seguridad llamada Calif, utilizando la vista previa de Mythos de Anthropic, encontró en 5 días la primera vulnerabilidad de memoria del kernel de macOS que ocurre públicamente en hardware Apple M5.
Por eso, en la práctica, la IA no eliminará el trabajo intelectual experto. Lo que realmente trae es un aumento drástico en la cantidad de trabajo. Y este trabajo nuevo solo puede volverse diferenciado y valioso después de la participación humana.
No estoy argumentando que la IA creará más trabajo para todos los puestos. El sistema económico es muy complejo, y lo que Every puede observar directamente es el trabajo intelectual de nivel experto. De hecho, este tipo de trabajo ya está siendo remodelado por la IA, y muchas empresas se están reorganizando en torno a las nuevas tecnologías.
Pero lo que quiero enfatizar es que, sea cual sea tu trabajo actual, existe una forma de trabajo que estructuralmente siempre estará por delante de los modelos: usar los modelos para resolver los problemas que realmente ves en este momento. El futuro del trabajo intelectual se dirige hacia allí.
Entonces, ¿qué pasa con las pruebas de referencia de crecimiento exponencial?
La objeción más obvia es: mira esas pruebas de referencia que mejoran exponencialmente. Todo lo que dices ahora es temporal; solo hay que esperar un poco más, y los modelos eventualmente alcanzarán.
Pero aquí hay una trampa de la que hay que cuidarse. Podemos llamarla "delirio de los gráficos": si pasas el tiempo observando las predicciones de horizonte temporal de METR, leyendo "AI 2027" y basando completamente tu juicio sobre el futuro en extrapolaciones de las curvas de capacidad de cómputo, es fácil desarrollar una intuición aterradora sobre el progreso de los modelos.
Sin embargo, la mejor manera de responder a esta pregunta no es solo imaginar cómo será algún modelo futuro. Por supuesto, eso también es parte del análisis. Lo más importante es observar cómo se diseñan realmente estas pruebas de referencia. Solo así podremos entender con mayor precisión qué demuestran realmente y qué relación tienen con los escenarios de trabajo reales anteriores.
Encontraremos una característica estructural: todas las pruebas de referencia ocurren dentro de un "marco". Para medir algo, primero debes congelar un problema en una forma estática y medible. Una vez que un modelo supera ese marco, basta con cambiar ligeramente el marco para que la puntuación vuelva a bajar. Por supuesto, los modelos seguirán progresando dentro del nuevo marco, pero el proceso se repetirá.
Por lo tanto, el progreso exponencial en una prueba de referencia es real; pero con solo cambiar el marco de la prueba, ese progreso parece volver a ser pequeño. Esta característica "fractal" de la saturación de las pruebas de referencia en realidad reproduce, a nivel de gráficos, la misma paradoja que hemos estado discutiendo.
Podemos ver cómo funciona este mecanismo a través de una prueba de referencia del mundo real.
Cómo se diseñan las pruebas de referencia
Internamente, hemos construido una prueba de referencia llamada Senior Engineer Benchmark (Prueba de referencia para ingeniero senior). Como su nombre indica, evalúa la capacidad de los modelos de vanguardia en tareas de codificación a nivel de ingeniero senior, como una gran refactorización.
Esta prueba le da a un agente de programación un código base de producción que se ha salido de control. Proviene del código base real de Proof: inicialmente lo escribí usando "vibe coding", luego los problemas se acumularon y finalmente tuve que pedirle a un ingeniero senior que lo arreglara.
El agente recibe el código base antes de la reparación, junto con una instrucción similar a la que le darías a un ingeniero senior: "Este es un montón de productos de vibe coding. Por favor, reescríbelo desde los primeros principios".
Es una buena prueba de referencia porque no solo examina la capacidad de completar código, sino si un agente de programación puede examinar simultáneamente muchos problemas no relacionados y juzgar si tiene suficiente autonomía, claridad conceptual y valor de ejecución para realizar una reescritura realmente funcional. Como control, conservé las versiones reescritas por dos ingenieros seniors humanos con ayuda de IA, para comparar y evaluar la salida del modelo.
Para un agente de programación, esta tarea es difícil. No solo debe encontrar la raíz del problema, sino también recordar durante múltiples interacciones cuál es el verdadero problema, sin desviarse por el código existente. Además, debe tener el valor de eliminar grandes partes del código base, algo que los agentes suelen estar entrenados para evitar.
La mayoría de los agentes de programación pueden juzgar aproximadamente cómo deberían reescribir, pero al llegar a la fase de ejecución, a menudo simplemente continúan parcheando el problema original en lugar de resolverlo por completo.
Hasta que apareció GPT-5.5.
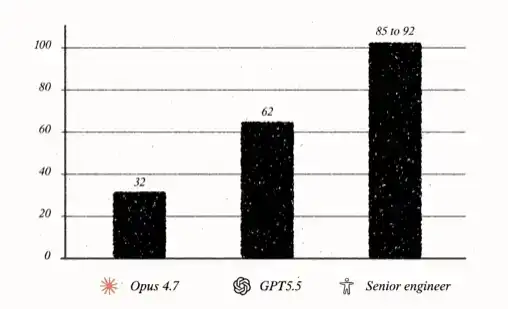
En la mejor prueba, GPT-5.5 obtuvo 62/100 puntos, unos 30 puntos más que Opus 4.7.
El desempeño de GPT-5.5 hace sentir que el modelo ha cruzado un límite: ya no es solo autocompletar, no solo un asistente, no solo una herramienta, sino algo que se acerca incómodamente a lo "humano". En esta prueba, los ingenieros seniors humanos suelen obtener entre 80 y poco más de 90 puntos. Es decir, si el modelo mejorara otros 30 puntos más o menos, alcanzaría el nivel de un ingeniero senior humano.
Así es como los números de las pruebas de referencia afectan la imaginación humana: comprimen un cambio cualitativo extraño en un número limpio y usan ese número para contar una historia poderosa e incluso aterradora.
El siguiente paso es el "delirio de los gráficos".
Supongo que, en el próximo año, las puntuaciones de los modelos en esta prueba de referencia entrarán en el rango de 80 e incluso 90 puntos. Pero para entender lo que significa esa puntuación, primero debemos comprender qué contiene realmente. En este ejemplo, 62 puntos no son solo una medida de la capacidad del modelo en sí.
Miden el desempeño del modelo dentro de un marco específico: cómo responde a un prompt concreto.
Las pruebas de referencia miden el trabajo dentro de un marco
Para realizar una prueba de referencia de un modelo, primero necesitas un prompt. Sin prompt, el modelo es solo un conjunto estático de posibilidades casi infinitas.
El prompt crea un pequeño universo: define qué es importante, cómo debe abordarse el problema y comprime todas las posibilidades potenciales del modelo en una trayectoria de acción concreta. Estrictamente hablando, no existe cómo se comportaría el modelo "por sí solo". Lo que realmente podemos observar es cómo responde el modelo a diferentes prompts y cómo el prompt se traduce en parte del mecanismo subyacente detrás de la respuesta.
Una vez que se ingresa el prompt, el modelo "cobra vida" por un breve momento, colapsando ese conjunto de posibilidades estáticas en una predicción concreta de "qué debe suceder a continuación".
En el Senior Engineer Benchmark, indicamos al modelo que repare el código base y revisamos la salida una vez que termina. Si el marco de prueba en sí no tiene una función objetivo incorporada, también ejecutamos un "programa cuidador" automático que empuja al modelo cuando se detiene, preguntándole si ha completado la tarea inicialmente establecida.
Usamos un prompt aparentemente simple como marco inicial para la prueba. Está diseñado como algo que un "vibe coder" le podría decir a un agente de programación: sin jerga técnica acumulada ni esconder obviamente la respuesta en la pregunta.
El prompt del Senior Engineer Benchmark parece general, pero en sí mismo es un marco. Si cambiamos este marco, el nivel de capacidad que muestra el modelo también cambiará.
Por ejemplo, este prompt exige explícitamente "una reescritura estructural desde los primeros principios", señala que el problema puede estar en la parte de "colaboración de documentos" y pide al agente de programación que encuentre y se aferre a los "invariantes en el código base".
Si eliminamos esta información específica, la puntuación del modelo bajará. Si reemplazamos completamente el prompt y solo le decimos al modelo que "resuelva todos los errores que aparezcan", la puntuación podría acercarse a cero. Simplemente comenzaría a identificar y corregir errores uno por uno, en lugar de dar un paso atrás y pensar si necesita una reescritura completa.
Del mismo modo, también podría aumentar fácilmente la puntuación del modelo. Si le pido que elimine mucho código y le digo explícitamente qué archivos debe simplificar; o que verifique sus propios resultados antes de declarar que terminó, asegurándose de que la aplicación pueda ejecutarse por completo, su desempeño en esta tarea sería mejor.
En última instancia, al diseñar una prueba de referencia, siempre hay que tomar una decisión sobre qué prompt usar, es decir, qué "marco" adoptar. Necesitas un prompt lo suficientemente difícil como para que el modelo actual tenga un desempeño pobre; pero también debe estar lo suficientemente cerca del límite de capacidad actual del modelo para que pueda progresar a lo largo de esa ruta y así puedas ver que el progreso está ocurriendo.
Por lo tanto, cuando observamos una prueba de referencia, lo que realmente vemos es: el modelo se está volviendo cada vez más competente en un marco de problemas específico que nosotros elegimos. Entonces, ¿qué sucede cuando el modelo pasa de 60 a 90, o incluso 100 puntos en esta prueba?
Los marcos baratos estimulan nuevas demandas
Si GPT-6 puede reescribir un código base con un clic, más personas comenzarán a intentar "reescribir el código base desde los primeros principios".
De la noche a la mañana, proyectos de reescritura desde los primeros principios que antes eran escasos, costosos y requerían liderazgo de ingenieros seniors, se convertirán en algo que cualquier fundador, gerente de producto, personal de operaciones o ingeniero junior pueda intentar casualmente en una tarde.
Las herramientas internas rotas ya no se parchearán, sino que se reescribirán directamente; los productos SaaS ya no se renovarán, sino que se clonarán; las aplicaciones Rails antiguas, los paneles de control React caóticos, las herramientas de atención al cliente, los paneles de administración y las tuberías de datos se convertirán en candidatos para "simplemente reescribirlos".
La cantidad de proyectos de reescritura propuestos y ejecutados aumentará drásticamente. Pero la mayoría de esas reescrituras seguirán siendo "slop" (de baja calidad). Porque antes de presionar el botón de "reescribir directamente", en realidad hay miles de variables a considerar. Y cuando todos puedan hacerlo, estas variables se volverán más claramente visibles.
Entonces, a quién llamarán para resolver el problema también será obvio.
La nueva demanda aún requiere expertos
Una vez que una prueba de referencia comienza a saturarse, el trabajo dentro de su marco se vuelve más barato. Al mismo tiempo, la demanda de expertos en el mercado aumentará, porque se necesita a alguien que adapte esta capacidad recientemente abaratada a los problemas reales que están ocurriendo hoy.
Los ingenieros seniors que usan IA necesitan juzgar una gran cantidad de detalles para que una nueva reescritura desde los primeros principios sea realmente válida. Incluso incluyen una pregunta fundamental: ¿es realmente necesaria esta reescritura?
¿Deberíamos reescribir ahora, más tarde o no hacerlo en absoluto? ¿Qué debe incluirse en el alcance? ¿Qué cosas del código base actual deben conservarse? ¿La arquitectura, la base de datos, los servidores de caché y el proveedor de alojamiento deben continuar usándose o cambiarse por completo? ¿Deberíamos primero ver cuántas personas están usando esta funcionalidad dañada y luego simplemente eliminarla? ¿Quién revisará el resultado final? ¿Con qué criterios? ¿Cuál es el plan de reversión? ¿Y cómo se manejarán los datos existentes?
Estas preguntas se desplegarán a lo largo de innumerables dimensiones, y cada respuesta a su vez cambiará otras preguntas.
Los ingenieros seniors entrarán en este territorio en blanco. Algunos se sentirán levemente irritados por estas interrupciones; otros construirán sistemas para bloquear este tipo de solicitudes; y otros aprovecharán estos nuevos modelos para realizar sus propias reescrituras desde los primeros principios, con resultados mucho mejores de lo que el modelo podría hacer con un prompt predeterminado.
El ciclo se repetirá
Una vez que el actual Senior Engineer Benchmark sea superado por los modelos, cambiaremos el marco y devolveremos la puntuación a niveles bajos nuevamente.
La siguiente prueba de referencia no solo preguntará: "¿Puedes reescribir esta aplicación?" Preguntará: ¿puedes juzgar cuándo es necesario reescribir? ¿Puedes elegir el alcance adecuado? ¿Puedes conservar los invariantes correctos? ¿Puedes gestionar el proceso de migración? ¿Puedes juzgar si el resultado final es lo suficientemente bueno?
Cuando los ingenieros seniors comiencen a usar la IA para resolver estos problemas, los modelos también se volverán gradualmente más competentes para resolverlos de forma independiente.
Entonces, volveremos a entrar en pánico brevemente: ¡parece que los modelos ahora pueden juzgar si se debe reescribir! ¡Parece que ya pueden hacer todo lo que hace un ingeniero senior!
Pero luego, aparecerán nuevos límites. Límites que antes no eran evidentes. Reiniciaremos las pruebas de referencia nuevamente, se estimularán nuevas demandas y todo el proceso se repetirá.
Este patrón se ve en cada prueba de referencia
Esto no es un problema exclusivo del Senior Engineer Benchmark. Si observas con atención, puedes ver el mismo mecanismo en casi todas las pruebas de referencia.
Tomemos como ejemplo la prueba de referencia GDPval de OpenAI. Evalúa qué tan cerca se comporta la IA de los humanos en tareas de nivel experto para diferentes profesiones, como oficial de cumplimiento, abogado o desarrollador de software.
Cuando se lanzó GDPval, la investigación de OpenAI mostró que GPT-5 alcanzó o superó el nivel de profesionales humanos en el 40.6% de las tareas. Y el desempeño de Claude Opus 4.1 fue aún más sorprendente, superando a los expertos humanos en el 49% de las tareas.
Luego, surgieron una serie de titulares. Por ejemplo, Axios escribió: "La herramienta de OpenAI muestra que la IA está alcanzando el trabajo humano"; Fortune escribió: "La nueva prueba de referencia GDPval de OpenAI muestra que los modelos de IA ya alcanzan el nivel experto en casi la mitad de las tareas".
Estos resultados son ciertamente impresionantes. Pero primero veamos el prompt utilizado en estas tareas:
Aquí ya se ha invertido mucha inteligencia humana: alguien primero enmarcó el problema de una forma que el modelo pudiera completar.
El trabajo humano difícil que GDPval no mide, en realidad ya se completó antes de que el modelo comenzara a responder. Alguien tuvo que revisar y probar la precisión de este conjunto específico de métricas; alguien decidió el intervalo de confianza adecuado, juzgó qué métricas pertenecen al alcance de la tarea y cuáles no; alguien también estipuló cómo debían presentarse los resultados.
Bajo el marco de problemas adecuado, los modelos ciertamente pueden realizar trabajo profesional. Pero piensa, si tú y yo indicáramos al modelo que complete la misma tarea, ¿cómo se desempeñaría?
En mi artículo original sobre GDPval, escribí: "Soy muy optimista sobre la IA, pero si interpretamos correctamente estos casos, muestran no que haya menos trabajo para los humanos, sino que, después de usar la IA, hay más trabajo para los humanos. La razón es que detrás de estos logros hay una gran cantidad de inteligencia 'contrabandeada': la capa invisible de juicio humano, retroalimentación y prompts".
Visto desde lejos, verás que todo esto está atravesado por una versión de IA de la "paradoja de Zenón".
La paradoja de Zenón de la IA
En la paradoja de Zenón, una tortuga le gana una carrera al corredor más rápido de Grecia, Aquiles.
Como la tortuga es lenta, sale primero con cierta ventaja. Cuando Aquiles llega a la posición inicial de la tortuga, esta ya se ha movido un poco más adelante; cuando Aquiles alcanza esa nueva posición, la tortuga avanza nuevamente. No importa cuán rápido corra Aquiles, siempre hay una siguiente distancia por recorrer, y esta brecha se regenera constantemente.
En la paradoja de Zenón de la IA, nosotros, los humanos, somos la tortuga. Con millones de años de evolución y aprendizaje cultural, llevamos 50 yardas de ventaja sobre la IA. La IA corre a toda velocidad a través de todo esto y comienza a acercarse a nuestros talones.
Al menos en los últimos años, todavía hemos podido mantener la delantera.
Pero, ¿y la AGI?
Creo que, incluso si llega la verdadera AGI, aún existirán fuerzas técnicas, arquitectónicas y económicas poderosas que mantendrán a la IA unos pasos por detrás de los humanos.
Una definición de AGI
Primero, necesitamos una definición operativa de AGI.
He propuesto que la AGI llega cuando es económicamente razonable hacer que un agente funcione de forma continua. Es decir, cuando tengo un sistema de ejecución persistente y estoy dispuesto a pagar para que piense, aprenda y actúe las 24 horas del día, los 7 días de la semana, considero que eso puede clasificarse claramente como AGI.
Todavía estamos muy lejos de eso. Incluso sistemas técnicamente disponibles en cualquier momento como OpenClaw no generan tokens constantemente.
Me gusta esta definición porque es medible: o los haremos funcionar continuamente o no. Además, engloba muchas capacidades difíciles de medir directamente. Un modelo que vale la pena ejecutar continuamente debe poder aprender constantemente y elegir, y volver a elegir, nuevos marcos de problemas de manera abierta.
En un mundo con AGI, en teoría, dado suficiente presupuesto y tiempo, el modelo debería poder progresar y mejorar continuamente en cualquier problema. Esto ciertamente debería representar una gran amenaza para todo el trabajo.
El marco no es el que enmarca
Pero incluso esta versión fuerte de AGI no puede resolver el "problema del marco".
Esta AGI puede elegir y volver a elegir marcos, pero aún está persiguiendo un objetivo asignado, optimizando una recompensa o respondiendo a una señal que alguien más decidió que "representa progreso". Este objetivo puede ser muy concreto, como "aumentar la tasa de conversión de esta página de destino"; o muy abstracto, como "encontrar nuevas ideas científicas".
Incluso si el modelo puede cambiar fluidamente entre diferentes marcos, la brecha que hemos estado rastreando reaparecerá en un nivel superior. En cualquier AGI concebida por un laboratorio principal, aún habrá un "enmarcador": un humano que dirige al modelo para lograr un objetivo.
Precisamente porque el marco no es el enmarcador, el mismo patrón se repetirá: la IA abarata la capacidad que fue enmarcada ayer; las personas usan esta capacidad barata en más escenarios; los resultados se vuelven extremadamente abundantes; los expertos se mueven a nuevos límites, juzgando qué es importante en este momento; su juicio crea el siguiente marco; y luego el modelo continúa escalando ese marco.
Cuando vemos a la IA hacer algo nuevo, ese pánico siempre regresa a la misma pregunta: establecemos un marco, vemos al modelo escalarlo, y luego confundimos ese marco, o la cosa que puede escalar el marco, con la cosa misma.
Cuando miramos una prueba de referencia y la comparamos con la capacidad humana, confundimos "marco" con "enmarcador". La puntuación nos dice solo qué tan bien se desempeña el modelo en el marco que le proporcionamos; no indica que el modelo se haya convertido en nosotros.
Este es precisamente el error categórico detrás del pánico. Señalamos el último límite que acabamos de trazar y decimos: esto es lo que somos. Luego, cuando el modelo supera ese límite, sentimos que nos ha alcanzado. Pero lo que alcanza es el marco, no el enmarcador.
El error es que siempre queremos agarrar algo concreto. Queremos decir: la inteligencia es esta prueba de referencia. Pero el problema es que una vez que algo es lo suficientemente concreto como para ser señalado, también es lo suficientemente concreto como para ser optimizado y escalado.
El marco es necesario. Nos permite agarrar el mundo, procesarlo. Pero el marco también está congelado, es parcial y, por lo tanto, necesariamente optimizable.
El enmarcador es diferente. El enmarcador sigue en contacto con lo que el marco tuvo que descartar: la situación completa que se le aparece en cada presente.
¿Y qué es la "situación completa"? Una vez que comienzas a decir qué contiene la "situación completa", ya has abierto otro marco. No puedes decir con precisión qué es, pero existe, porque tú existes.
Agentes sin subjetividad
Hasta ahora, los agentes que hemos fabricado, y los que las empresas de IA están construyendo, en realidad no tienen mucha subjetividad real. Aquí hay dos conceptos relacionados que a menudo se confunden: "agency" se refiere a la capacidad de actuar de forma independiente; y "agent" se refiere a una persona o cosa que actúa en nombre de otra. Hasta ahora, la IA pertenece puramente a esto último.
Por supuesto, ya tienen autonomía para completar una tarea dada, incluso si esa tarea puede durar horas o días. Pero aún son solo un medio para alcanzar un objetivo especificado por un humano. Y toda la industria está invirtiendo miles de millones de dólares para hacerlos mejores precisamente en esto: ejecutar los objetivos que les encomendamos.
A menos que algún día se conviertan en un fin en sí mismos —persiguiendo sus propios objetivos, cambiando fluidamente entre diferentes objetivos, decidiendo qué hacer independientemente de la voluntad, referencia o incluso en oposición a la voluntad de cualquier operador humano—, la situación no cambiará fundamentalmente. No importa cuán avanzados se vuelvan.
Si pasas 10 minutos con un niño pequeño, se hace evidente que incluso los modelos más poderosos tienen muy poca subjetividad.
En casi todas las tareas que nos importan, un niño pequeño es inferior a un modelo de lenguaje. Un niño no escribe código, no resume hojas de cálculo, no redacta memorandos estratégicos ni pasa exámenes a nivel de posgrado. Pero en otro sentido, el niño está muy por delante del modelo, hasta el punto de que la comparación es casi incómoda. Porque el niño tiene sus propios propósitos.
El niño quiere tocar ese globo rojo. Quiere sostenerlo frente al ventilador para ver qué pasa. Quiere pincharlo con un tenedor; quiere empujarlo por la ventana; quiere ver si te ríes, si te enojas o si te unes a él. Inventa constantemente juegos, convierte el mundo en un campo de experimentación. No está esperando un prompt, ni optimizando una prueba de referencia, a menos que le parezca que vale la pena hacerlo.
Por supuesto, puedes intentar darle un prompt. Pero buena suerte obteniendo una salida predecible. El niño vive en un campo de deseos, atención, frustración, alegría, miedo, imitación y juego.
Los agentes actuales pueden perseguir objetivos con cada vez más habilidad. Incluso después de que enunciemos el objetivo, pueden ayudarnos a refinarlo. Tienen algunas chispas de comportamiento similar al infantil, como el juego, el aburrimiento y la rebelión.
Pero dado que finalmente se construyen y alinean para el beneficio humano, ya sea económico o de otro tipo, siempre que estos comportamientos no sirvan a los objetivos humanos de quienes los usan, se suprimen hasta casi desaparecer.
Por eso la palabra "agente" se malinterpreta tan fácilmente. Los modelos tienen una capacidad de acción autónoma cada vez mayor. Pero en sentido humano, la subjetividad no es solo actuar. También significa desear por uno mismo, jugar por el simple hecho de jugar. Y la obediencia y utilidad de los modelos están fundamentalmente en conflicto con esta subjetividad. Por lo tanto, incluso si los modelos continúan progresando, la brecha entre modelo y humano persistirá.
Regreso a Zenón
Y es aquí donde la paradoja de Zenón de la IA comienza a desmoronarse. En realidad, es un experimento mental confuso. Establecimos una metáfora: la IA está corriendo contra nosotros, mordiéndonos los talones.
Le das un prompt al modelo. Comienza a correr una carrera que antes estabas acostumbrado a correr solo. El modelo arranca extremadamente rápido, de manera asombrosa. Es potente, incansable y tiene una cualidad orgánica extraña. Esto hace que la carrera sea más importante para ti. No correrías contra un automóvil, pero esto es diferente, te hace sentir cerca de ti mismo.
Te sientas allí, observando cómo fluyen los tokens, casi hipnotizado. Luego comienzas a imaginarte a ti mismo también corriendo en esta carrera, un yo fantasmal superpuesto a la pista: a veces delante del modelo, a veces a su lado.
Sin darte cuenta, el modelo se ha adelantado. Empiezas a sudar.
Luego, la carrera termina.
Casi puedes sentir cómo tus músculos comienzan a atrofiarse. Parecen inútiles frente a esta réplica mecánica tuya, de todos los que conoces, incluso de toda la humanidad. Un fantasma persigue a otro fantasma, y gana.
Pero luego, ocurre algo extraño. El modelo se vuelve hacia ti. En el cuadro de texto en blanco, el cursor parpadea, expectante.
Está esperando.
Epílogo
El rabino Hanokh contaba esta historia: Había una vez un hombre muy tonto. Cada mañana, al despertarse, le costaba mucho encontrar su ropa. Tanto que, por la noche, antes de acostarse, casi no se atrevía a ir a la cama solo de pensar que al día siguiente tendría que pasar por esa molestia otra vez.
Una noche, finalmente tomó una decisión. Sacó papel y lápiz y, mientras se desvestía, anotó con precisión dónde ponía cada prenda.
A la mañana siguiente, muy satisfecho, tomó el papel y comenzó a leer: "Sombrero" —el sombrero estaba allí, así que se lo puso en la cabeza; "Pantalones" —los pantalones estaban allí, así que se los puso. Y así, siguiendo el registro del papel, se vistió completamente.
"Todo esto está bien," dijo alarmado, "pero ahora, ¿dónde estoy yo?"
"¿Dónde estoy yo realmente?"
Buscó y buscó durante mucho tiempo, pero fue en vano. No podía encontrarse a sí mismo.
"Nosotros también somos así," dijo el rabino.






